多表查询和子查询
Posted Nothing_doit
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多表查询和子查询相关的知识,希望对你有一定的参考价值。
主要介绍了多表查询,以及在多表/单表查询时常用的函数和关键字,介绍了如何使用子查询。多表查询
employee表,departments表,localtions表结构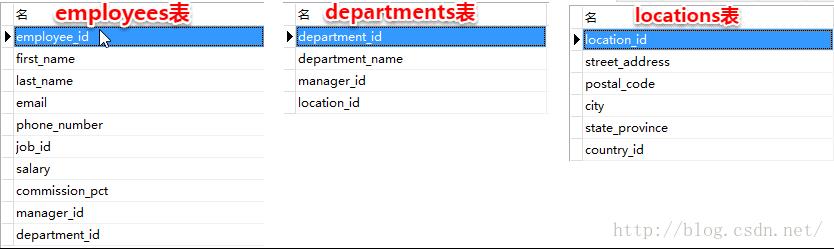
引例:
select last_name, department_name from employees, departments分析:
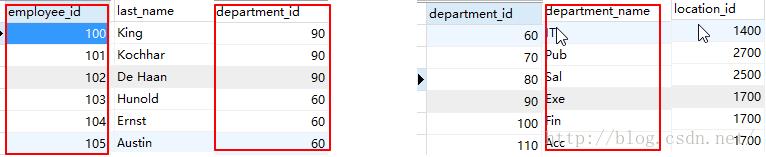
经过联接可以根据employee_id查到department_id,然后根据deparment_id查到department_name
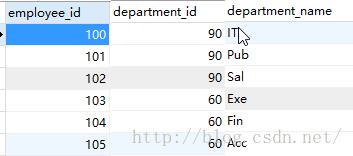
| from employees, departments |
若左表8条记录,右表20条记录,使用笛卡尔联接就会产生160条记录。 通常这种连接方式我们是不提倡的,影响效率。
笛卡尔集产生条件: ①所有表中的所有行互相连接 ②在标间连接的时候没有设置连接条件,或者连接条件无效
笛卡尔乘积,逗号连接
|
SELECT
* FROM 表名1,表名2; |
将country2表和city2表联接 SELECT * FROM city2, country2 WHERE countrycode = code;
使用ON 子句创建连接
自然连接中是以具有相同名字的列为连接条件的。 可以使用 ON 子句指定额外的连接条件。 这个连接条件是与其它条件分开的。 ON 子句使语句具有更高的易读性。等值连接
| SELECT 列名1, 列名2, ... FROM 表1 [INNER] JOIN 表2 ON 联接条件(等值条件) JOIN 表3 ON 联接条件 WHERE 普通过滤条件 |
查询城市人口数大于100万的城市名称和所属国家
SELECT ci.name city, co.name country , ci.population cityPop FROM city2 ci [INNER] JOIN country2 co ON ci.countrycode = co.code WHERE ci.population > 1000000;
| 注意事项: 内联虽然和逗号一样, 优先使用内联 INNER关键字可以省略 ON和WHERE虽然可以混用, 但是不建议 ON 后面最好是联接条件 WHERE 后面是普通过滤条件 查询结果就是满足联接条件的行 |
区分重复的列名 使用表名前缀在多个表中区分相同的列。 在不同表中具有相同列名的列可以用表的别名加以区分。
好处: 使用别名可以简化查询。 使用表名前缀可以提高执行效率。
多个连接条件与 AND 操作符
表的联接可以不止一个 查询一下国家和首都,只显示首都人口大于500万的国家SELECT co.name country, ci.name capital, ci.populatiON, cl.language FROM country co JOIN city ci ON co.capital = ci.id JOIN countrylanguage cl ON co.code = cl.countrycode WHERE ci.populatiON > 5000000 AND cl.isofficial = 'T';
| 连接 n个表,至少需要 n-1个连接条件 |
外联接
保证某个表的数据的完整性 LEFT JOIN 左外连接,保证左表的完整性 RIGHT JOIN 右外连接,保证右表的完整性| SELECT 列名1,列名2,... FROM 表1 LEFT [OUTER] JOIN 表2 ON 联接条件 WHERE 普通过滤条件 |
查询所有国家和首都 SELECT co.name country, ci.name capital FROM country co LEFT JOIN city ci ON co.capital = ci.id;
查询所有国家及官方语言 SELECT country.name, cl.language, cl.isofficial FROM country LEFT JOIN countrylanguage cl ON country.code = cl.countrycode WHERE cl.isofficial = 'T' or cl.isofficial is null 哪些国家没有首都 SELECT co.name country, ci.name capital, co.capital, ci.id FROM country co LEFT JOIN city ci ON co.capital = ci.id WHERE ci.name is null;
单行函数
| LOWER('SQL COURSE') ----> sql course 将目标字符串转为小写 |
| UPPER('SQL Course')----> SQL COURSE 将目标字符串转为大写 |
| CONCAT('Hello', 'World')---->HelloWorld 联接两个字符串 |
| SUBSTR('HelloWorld',1,5)---->Hello 获取子串 |
| LENGTH('HelloWorld')---->10 获取字符串的长度 |
| INSTR('HelloWorld', 'W')---->6 在目标位置插入字符 |
| LPAD(salary,10,'*')---->*****24000 右对齐填充 |
| RPAD(salary, 10, '*')---->24000***** 左对齐填充 |
| TRIM(‘H’ FROM 'HelloWorld')----->elloWorld 截取字符串 |
| REPLACE('abcd','b','m')---->amcd 替换目标字符 |
| ROUND(45.926, 2)---->45.93 四舍五入 |
| TRUNC(45.926, 2)---->45.92 截断 |
| MOD(1600, 300)---->100 求余 |
常用的单行函数使用方式及效果 将所有员工的名字连接起来,并对工资进行右对齐填充 SELECT CONCAT(first_name, last_name) name, lpad(salary, 10, '0') FROM company.employees; 把所有国家和首都名使用:连接起来,并全部转为大写显示 SELECT UPPER(CONCAT(co.name, ' : ', ci.name)) FROM country co LEFT JOIN city ci ON co.capital = ci.id
组函数
| 分组函数作用于一组数据,并对一组数据返回一个值 |
| AVG(列名) 求平均数 MAX(列名) 求最大值 SUM(列名) 求和 MIN(列名) 求最小值 |
查询所有员工的平均工资和最大最小值,求和. SELECT AVG(salary) 平均工资, MAX(salary) 最高工资, MIN(salary) minSalary, SUM(salary) sumSalary FROM company.employees;
查看表中的记录数,不要使用具体列名,除非是主键
SELECT count(*) FROM country;
SELECT --last_name, MIN(salary) 最低平资 FROM company.employees;
SELECT --name, max(population) FROM country WHERE continent = 'europe';
| 在统计计算中拒绝出现代表个体的信息,上边的name,last_name都属于个体信息,不能在统计计算中出现 |
GROUP BY
分组函数和组函数配合使用进行查询
| SELECT 分组条件, 组函数(这里的组函数是作用于某一组成员) FROM 表名 GROUP BY 分组条件 |
查询每个部门的平均工资 SELECT department_id, AVG(salary) FROM company.employees GROUP BY department_id;
查询各大洲的平均寿命和最少人口数 SELECT continent, avg(lifeexpectancy) avgLife, min(population) minPop FROM country GROUP BY continent
HAVING
| 对分组结果进行过滤. 不能使用WHERE HAVING只能对分组结果进行过滤 |
查询部门平均工资大于9000的部门id
SELECT department_id, AVG(salary) FROM company.employees GROUP BY department_id HAVING avg(salary) > 9000;
查询哪些国家的语言超过10种要求显示国家名称 SELECT co.name, count(cl.language) langs FROM countrylanguage cl right JOIN country co ON cl.countrycode = co.code GROUP BY co.name HAVING langs > 10 ORDER BY langs; 查询中国的城市个数 SELECT countrycode, count(*) FROM city GROUP BY countrycode HAVING countrycode = 'chn';
DISTINCT
对获取到的某些记录进行去重
在City表中有多少不同的地区。
SELECT
DISTINCT District
FROM
city;
小结:
|
当上述关键字参与查询是,提供一种思考思路。
1) 判断需要从哪个表中取数据 确定FROM 2) 一张表够吗? 如果不够 JOIN 3) 需要保证某表数据完整吗? 如果需要 考虑外联, 继续考虑左右的问题 4) 联接条件的确定 ON 5) 判断是否需要虚表的中的所有数据, 如果不需要 WHERE 6) 是否需要分组, 如果需要 GROUP BY, 进一步判断分组依据的列名. 7) 把分组依据的列名放在SELECT后面 8) 继续考虑SELECT究竟要选择哪些列(组函数) 9) 分组的结果是都需要吗? 如果不需要 HAVING过滤 10)是否需要对最终的显示排序 ORDER BY |
| 一个完整的SQL语句: select 分组依据的列名, 其他的列, 组函数 from 表名1(子查询) join 表名2 on 表的联接条件 left join 表名3 on (外联接时on条件必须有) 表的联接条件 where 过滤条件 group by 分组依据的列名 having 组函数 比较表达式(分组结果的过滤) order by 排序依据的列 desc limit 略过的记录数,最终显示限制的记录数(每页显示的记录数) |
哪些国家没有列出任何使用语言? SELECT a.name FROM country a LEFT JOIN countrylanguage b ON a.code = b.countrycode WHERE b.language is null; ----------------------------- SELECT a.name, count(language) FROM country a LEFT JOIN countrylanguage b ON a.code = b.countrycode GROUP BY a.name HAVING count(language) = 0;
列出在城市表中80%人口居住在城市的国家 SELECT a.name, (sum(b.populatiON) / a.populatiON) AS rate FROM country a JOIN city b ON a.code = b.countrycode GROUP BY a.name HAVING rate >= 0.8;
Sweden国家说的是什么语言? SELECT a.name, b.language FROM country a JOIN countrylanguage b ON a.code = b.countrycode WHERE a.name = 'Sweden';
查询中国的每个省的总城市数量和总人口数 SELECT district, count(*), sum(population) FROM city WHERE countrycode = 'chn' GROUP BY district ORDER BY sum(population) desc; ------------------------------------- SELECT countrycode, district, count(*), sum(population) FROM city GROUP BY district HAVING countrycode = 'chn' ORDER BY sum(population) desc;
子查询
| 子查询 (内查询) 在主查询之前一次执行完成。 子查询的结果被主查询(外查询)使用 。 可以用一个子查询替代上边的的表名。 子查询,将查询操作嵌套在另一个查询操作中。先执行子查询,再执行外查询 |
单行子查询
| 只返回一行。 使用单行比较操作符。 |
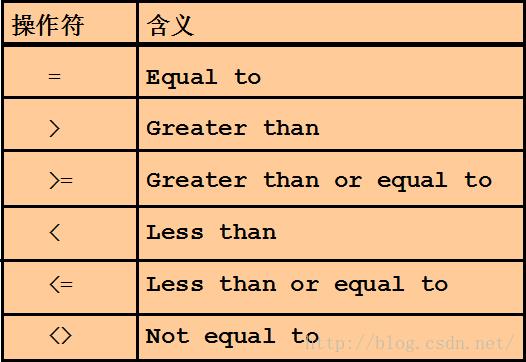
| SELECT 列名1,列名2... FROM 表名(子查询) WHERE 过滤条件(同样也可以使用子查询) |
查询谁的工资比'Abel'的工资高 SELECT last_name FROM employees WHERE salary >(SELECT salary FROM employees WHERE last_name = 'Abel');
在子查询中使用组函数
查询城市人口最多的城市名称 SELECT name FROM city WHERE population = (SELECT max(population) FROM city);
查询最发达的国家 SELECT name FROM country WHERE gnp = (SELECT max(gnp) FROM country);
子查询中的 HAVING 子句
| 首先执行子查询。 向主查询中的HAVING 子句返回结果。 |
查询最低工资大于50号部门最低工资的部门id和其最低工资 SELECT department_id, MIN(salary) FROM employees GROUP BY department_id HAVING MIN(salary) >(SELECT MIN(salary) FROM employees WHERE department_id = 50);
非法使用子查询
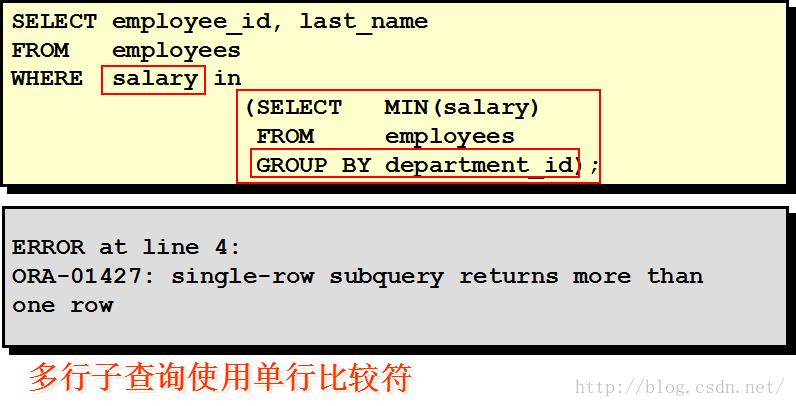
子查询中的空值问题
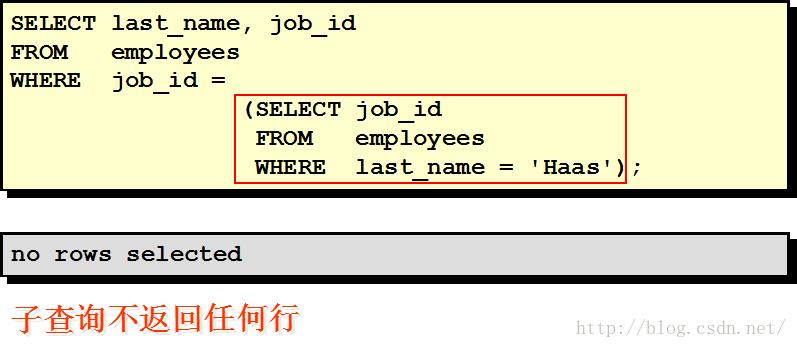
| 注意:子查询要包含在括号内。 单行操作符对应单行子查询,多行操作符对应多行子查询。 |
多行子查询
| 返回多行。 使用多行比较操作符。 |

在多行子查询中使用 ANY 操作符
返回其它部门中比job_id为‘IT_PROG’部门 任一工资低的员工的员工号、姓名、job_id 以及salary SELECT employee_id, last_name, job_id, salary FROM employees WHERE salary < ANY (SELECT salary FROM employees WHERE job_id = 'IT_PROG') AND job_id <> 'IT_PROG';
在多行子查询中使用 ALL 操作符
返回其它部门中比job_id为‘IT_PROG’部门 所有工资都低的员工 的员工号、姓名、job_id 以及salary
SELECT employee_id, last_name, job_id, salary FROM employees WHERE salary < ALL (SELECT salary FROM employees WHERE job_id = 'IT_PROG') AND job_id <> 'IT_PROG';
子查询中的空值问题
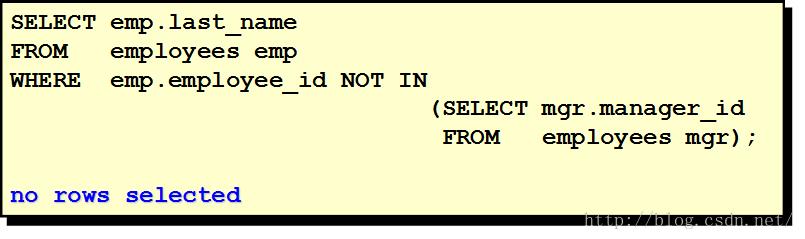
| 小结:在查询时基于未知的值时,应使用子查询 子查询可以返回多个结果/单个结果,结果个数不同应该使用不同的操作符 |
以上是关于多表查询和子查询的主要内容,如果未能解决你的问题,请参考以下文章