pix2pixHD算法笔记
Posted AI之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pix2pixHD算法笔记相关的知识,希望对你有一定的参考价值。
论文:High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
论文链接:https://arxiv.org/abs/1711.11585
代码链接:https://github.com/NVIDIA/pix2pixHD
图像到图像的翻译是GAN的一个重要应用,表示基于输入图像生成指定的输出图像的过程,比如有监督的pix2pix(参考博客),无监督的CycleGAN(参考博客)等。而基于语义分割图生成对应图像可以看做是图像到图像的翻译中的一个特例,如Figure1(a)所示,其中左下角是语义分割图,模型基于这张图生成(a)这张看起来和实际图像差别不大的合成图。这个研究方向主要有2个发展趋势:1、生成的图像要尽可能接近真实图像;2、生成图像的分辨率越来越大,也就是越来越往高清大图发展。
这篇发表在CVPR2018的pix2pixHD在这两个方面都有不错的贡献。pix2pixHD是在pix2pix算法基础上做了优化,pix2pix算法合成图像的分辨率在256
×
\\times
× 256左右,作者曾经尝试直接用pix2pix算法生成高分辨率图像,但是发现训练过程不稳定,效果也不好,因此才不断优化得到pix2pixHD。pix2pixHD的训练依然是有监督的,也就是需要pair对的数据。

这篇论文除了能生成高清大图外,还有基于算法扩展实现的交互式体验。
1、实例级别的修改。用户可以将修改后的语义分割图输入模型得到合成图像。比如我可以基于一张实际拍摄的图像先得到其语义分割图,然后我可以手动修改这张语义分割图,比如将其中的人去掉,或者将其中的树变成房子,最后我再将修改后的语义分割图作为生成器的输入得到一张合成图像。比如Figure1(b)就是将语义分割图中的树换成房子后得到的合成图像。
2、合成图像多样化。基于同一张输入图像能够得到更加多样的合成图像是目前图像合成领域的研究热点。比如Figure1(c)就是基于(a)中的语义分割图得到的另一张合成图像,和(a)图在车颜色、道路方面都不大一样。
我们先来看看pix2pixHD在生成高质量的高清大图方面做了哪些优化工作。整体来看,pix2pixHD在pix2pix的基础上主要做了4个方面的改进:1、生成器从U-Net升级为多级生成器(coarse-to-fine generator)。2、判别器从patch GAN升级为多尺度判别器(multi-scale discriminator)。3、优化目标上增加了基于判别器特征的匹配损失。4、增加实例级别的信息。
首先,pix2pixHD的多级生成器如Figure3所示,主要包含G1和G2两部分,二者在结构上是类似的。G1表示全局生成网络(global generator network),输入和输出大小是1024
×
\\times
× 512,G2表示局部增强网络(local enhancer network),输入和输出大小是2048
×
\\times
× 1024。整体上可以看做是在一个常规的生成器(G2)中嵌入了另一个生成器(G1),G1最后输出的特征和G2中间输出的特征做特征融合作为G2后半部分的输入,主要目的是为了引入G1中学到的全局结构特征,这一点和PG-GAN的思想很像,同时在训练过程中也是先训练分辨率较小的G1,然后再一起训练G1和G2。

其次,pix2pixHD的多尺度判别器设计,先基于真实图像和合成图像构建3层图像金字塔(比如
2014
×
1024
2014\\times1024
2014×1024,1024
×
\\times
× 512,512
×
\\times
× 256),针对每层图像分别训练一个判别器进行判别,这3个判别器的结构是一样的,只不过处理的输入尺寸不一样。这一部分的设计是希望尺寸小的判别器促进图像整体方面的合成,尺寸大的判别器促进图像细节方面的合成,读过PG-GAN的同学应该能感受到这种思想。
然后是优化目标层面的,增加了基于判别器特征的匹配损失,如下式所示。Dk(i)表示判别器Dk的第i层特征。这一部分在生成器的中间特征层面做限制,而不仅仅是最终的输出图像,因此对于训练过程的稳定有一定帮助。
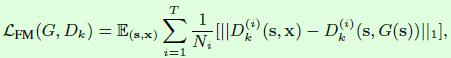
最后是增加实例级别的信息。我们知道语义分割图和实例分割图的最大差别在于后者区分相同类别的实例,比如一张图中的2个人,在语义分割图中会用同一种颜色来表示这2个人,而在实例分割图中会用2种不同的颜色来表示这2个人。在pix2pixHD的生成器和判别器中同样利用了实例级别的信息,如Figure4所示,(a)是语义分割图,(b)是实例边缘图,基于(a)和(b)就可以区别不同实例。实现层面,原本生成器的输入只是语义分割图(a),而现在变成将语义分割图(a)和实例边缘图(b)在通道维度上concat后才作为生成器的输入;同理,原本判别器的输入只是语义分割图和真实图像或生成图像在通道维度上concat后的结果,而现在变成语义分割图、实例边缘图和真实图像或生成图像在通道维度上concat后的结果。

增加实例信息对图像合成效果有一定帮助,比如可以得到更加清晰的边界,如图Figure5所示。

接下来看看基于pix2pixHD算法扩展的交互式体验。
首先是实例级别的修改。这里利用了前面介绍的实例级别的信息,因此实例级别的修改就比较简单。
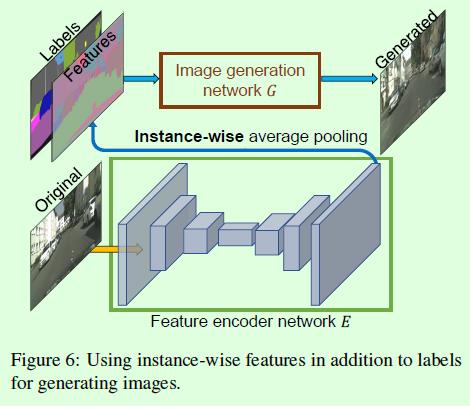
其次是合成图像多样化。许多图像合成算法只能基于语义标签得到单一的合成图像,虽然也有一些算法可以得到多样的输出,但大多数是基于全局进行的,而这篇论文的不同点在于可以做实例级别的多样输出,比如车的不同颜色。实现层面先通过新增一个encoder网络抽取图像特征,然后对特征做实例级别的均值池化操作,最后将这种池化后的特征和生成器的原输入组合成为新的输入,从而实现实例级别图像多样化,如Figure6所示。
实验结果:
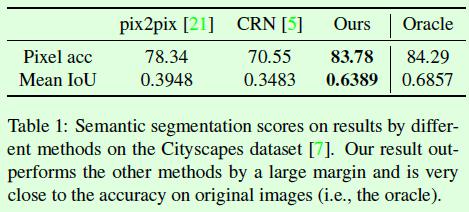
基于算法得到的合成图像做语义分割得到标签图,可以计算该标签图的指标,假如和基于真实图像做语义分割得到的标签图计算的指标接近,那就在一定程度上说明合成图的质量较高,Table1就是这样的实验结果对比。
pix2pixHD算法在基于边缘图像生成真实图像(edge2photo)任务上的泛化能力也很强,尤其是生成的人脸图像,如Figure2所示。

以上是关于pix2pixHD算法笔记的主要内容,如果未能解决你的问题,请参考以下文章