Hibernate缓存何时使用和如何使用
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hibernate缓存何时使用和如何使用相关的知识,希望对你有一定的参考价值。
参考技术A 关于hibernate缓存的问题基本的缓存原理
Hibernate缓存分为二级
第一级存放于session中称为一级缓存 默认带有且不能卸载
第二级是由sessionFactory控制的进程级缓存 是全局共享的缓存 凡是会调用二级缓存的查询方法 都会从中受益 只有经正确的配置后二级缓存才会发挥作用 同时在进行条件查询时必须使用相应的方法才能从缓存中获取数据 比如erate()方法 load get方法等 必须注意的是session find方法永远是从数据库中获取数据 不会从二级缓存中获取数据 即便其中有其所需要的数据也是如此
查询时使用缓存的实现过程为 首先查询一级缓存中是否具有需要的数据 如果没有 查询二级缓存 如果二级缓存中也没有 此时再执行查询数据库的工作 要注意的是 此 种方式的查询速度是依次降低的
存在的问题
一级缓存的问题以及使用二级缓存的原因
因为Session的生命期往往很短 存在于Session内部的第一级最快缓存的生命期当然也很短 所以第一级缓存的命中率是很低的 其对系统性能的改善也是很有限的 当然 这个Session内部缓存的主要作用是保持Session内部数据状态同步 并非是hibernate为了大幅提高系统性能所提供的
为了提高使用hibernate的性能 除了常规的一些需要注意的方法比如
使用延迟加载 迫切外连接 查询过滤等以外 还需要配置hibernate的二级缓存 其对系统整体性能的改善往往具有立竿见影的效果!
(经过自己以前作项目的经验 一般会有 ~ 倍的性能提高)
N+ 次查询的问题
什么时候会遇到 +N的问题?
前提 Hibernate默认表与表的关联方法是fetch= select 不是fetch= join 这都是为了懒加载而准备的
)一对多(<set><list>) 在 的这方 通过 条sql查找得到了 个对象 由于关联的存在 那么又需要将这个对象关联的集合取出 所以合集数量是n还要发出n条sql 于是本来的 条sql查询变成了 +n条
)多对一<many to one> 在多的这方 通过 条sql查询得到了n个对象 由于关联的存在 也会将这n个对象对应的 方的对象取出 于是本来的 条sql查询变成了 +n条
)iterator 查询时 一定先去缓存中找( 条sql查集合 只查出ID) 在没命中时 会再按ID到库中逐一查找 产生 +n条SQL
怎么解决 +N 问题?
)lazy=true hibernate 开始已经默认是lazy=true了 lazy=true时不会立刻查询关联对象 只有当需要关联对象(访问其属性 非id字段)时才会发生查询动作
)使用二级缓存 二级缓存的应用将不怕 +N 问题 因为即使第一次查询很慢(未命中) 以后查询直接缓存命中也是很快的 刚好又利用了 +N
) 当然你也可以设定fetch= join 一次关联表全查出来 但失去了懒加载的特性
执行条件查询时 iterate()方法具有著名的 n+ 次查询的问题 也就是说在第一次查询时iterate方法会执行满足条件的查询结果数再加一次(n+ )的查询 但是此问题只存在于第一次查询时 在后面执行相同查询时性能会得到极大的改善 此方法适合于查询数据量较大的业务数据
但是注意 当数据量特别大时(比如流水线数据等)需要针对此持久化对象配置其具体的缓存策略 比如设置其存在于缓存中的最大记录数 缓存存在的时间等参数 以避免系统将大量的数据同时装载入内存中引起内存资源的迅速耗尽 反而降低系统的性能!!!
使用hibernate二级缓存的其他注意事项
关于数据的有效性
另外 hibernate会自行维护二级缓存中的数据 以保证缓存中的数据和数据库中的真实数据的一致性!无论何时 当你调用save() update()或 saveOrUpdate()方法传递一个对象时 或使用load() get() list() iterate() 或scroll()方法获得一个对象时 该对象都将被加入到Session的内部缓存中 当随后flush()方法被调用时 对象的状态会和数据库取得同步
也就是说删除 更新 增加数据的时候 同时更新缓存 当然这也包括二级缓存!
只要是调用hibernate API执行数据库相关的工作 hibernate都会为你自动保证 缓存数据的有效性!!
但是 如果你使用了JDBC绕过hibernate直接执行对数据库的操作 此时 Hibernate不会/也不可能自行感知到数据库被进行的变化改动 也就不能再保证缓存中数据的有效性!!
这也是所有的ORM产品共同具有的问题 幸运的是 Hibernate为我们暴露了Cache的清除方法 这给我们提供了一个手动保证数据有效性的机会!!
一级缓存 二级缓存都有相应的清除方法
其中二级缓存提供的清除方法为
按对象class清空缓存
按对象class和对象的主键id清空缓存
清空对象的集合中的缓存数据等
适合使用的情况
并非所有的情况都适合于使用二级缓存 需要根据具体情况来决定 同时可以针对某一个持久化对象配置其具体的缓存策略
适合于使用二级缓存的情况
数据不会被第三方修改
一般情况下 会被hibernate以外修改的数据最好不要配置二级缓存 以免引起不一致的数据 但是如果此数据因为性能的原因需要被缓存 同时又有可能被第 方比如SQL修改 也可以为其配置二级缓存 只是此时需要在sql执行修改后手动调用cache的清除方法 以保证数据的一致性
数据大小在可接收范围之内
如果数据表数据量特别巨大 此时不适合于二级缓存 原因是缓存的数据量过大可能会引起内存资源紧张 反而降低性能 如果数据表数据量特别巨大 但是经常使用的往往只是较新的那部分数据 此时 也可为其配置二级缓存 但是必须单独配置其持久化类的缓存策略 比如最大缓存数 缓存过期时间等 将这些参数降低至一个合理的范围(太高会引起内存资源紧张 太低了缓存的意义不大)
数据更新频率低
对于数据更新频率过高的数据 频繁同步缓存中数据的代价可能和 查询缓存中的数据从中获得的好处相当 坏处益处相抵消 此时缓存的意义也不大
非关键数据(不是财务数据等)
财务数据等是非常重要的数据 绝对不允许出现或使用无效的数据 所以此时为了安全起见最好不要使用二级缓存
因为此时 正确性 的重要性远远大于 高性能 的重要性
目前系统中使用hibernate缓存的建议
目前情况
一般系统中有三种情况会绕开hibernate执行数据库操作
多个应用系统同时访问一个数据库
此种情况使用hibernate二级缓存会不可避免的造成数据不一致的问题 此时要进行详细的设计 比如在设计上避免对同一数据表的同时的写入操作 使用数据库各种级别的锁定机制等
动态表相关
所谓 动态表 是指在系统运行时根据用户的操作系统自动建立的数据表
比如 自定义表单 等属于用户自定义扩展开发性质的功能模块 因为此时数据表是运行时建立的 所以不能进行hibernate的映射 因此对它的操作只能是绕开hibernate的直接数据库JDBC操作
如果此时动态表中的数据没有设计缓存 就不存在数据不一致的问题
如果此时自行设计了缓存机制 则调用自己的缓存同步方法即可
使用sql对hibernate持久化对象表进行批量删除时
此时执行批量删除后 缓存中会存在已被删除的数据
分析
当执行了第 条(sql批量删除)后 后续的查询只可能是以下三种方式
a session find()方法
根据前面的总结 find方法不会查询二级缓存的数据 而是直接查询数据库
所以不存在数据有效性的问题
b 调用iterate方法执行条件查询时
根据iterate查询方法的执行方式 其每次都会到数据库中查询满足条件的id值 然后再根据此id 到缓存中获取数据 当缓存中没有此id的数据才会执行数据库查询
如果此记录已被sql直接删除 则iterate在执行id查询时不会将此id查询出来 所以 即便缓存中有此条记录也不会被客户获得 也就不存在不一致的情况 (此情况经过测试验证)
c 用get或load方法按id执行查询
客观上此时会查询得到已过期的数据 但是又因为系统中执行sql批量删除一般是针对中间关联数据表 对于中间关联表的查询一般都是采用条件查询 按id来查询某一条关联关系的几率很低 所以此问题也不存在!
如果某个值对象确实需要按id查询一条关联关系 同时又因为数据量大使用 了sql执行批量删除 当满足此两个条件时 为了保证按id 的查询得到正确的结果 可以使用手动清楚二级缓存中此对象的数据的方法!!(此种情况出现的可能性较小)
建 议
建议不要使用sql直接执行数据持久化对象的数据的更新 但是可以执行 批量删除 (系统中需要批量更新的地方也较少)
如果必须使用sql执行数据的更新 必须清空此对象的缓存数据 调用
SessionFactory evict(class)
SessionFactory evict(class id)等方法
在批量删除数据量不大的时候可以直接采用hibernate的批量删除 这样就不存在绕开hibernate执行sql产生的缓存数据一致性的问题
不推荐采用hibernate的批量删除方法来删除大批量的记录数据
原因是hibernate的批量删除会执行 条查询语句外加 满足条件的n条删除语句 而不是一次执行一条条件删除语句!!当待删除的数据很多时会有很大的性能瓶颈!!!如果批量删除数据量较大 比如超过 条 可以采用JDBC直接删除 这样作的好处是只执行一条sql删除语句 性能会有很大的改善 同时 缓存数据同步的问题 可以采用 hibernate清除二级缓存中的相关数据的方法
调 用
SessionFactory evict(class) ;
SessionFactory evict(class id)等方法
所以说 对于一般的应用系统开发而言(不涉及到集群 分布式数据同步问题等) 因为只在中间关联表执行批量删除时调用了sql执行 同时中间关联表一般是执行条件查询不太可能执行按id查询 所以 此时可以直接执行sql删除 甚至不需要调用缓存的清除方法 这样做不会导致以后配置了二级缓存引起数据有效性的问题
退一步说 即使以后真的调用了按id查询中间表对象的方法 也可以通过调用清除缓存的方法来解决
具体的配置方法
根据我了解的很多hibernate的使用者在调用其相应方法时都迷信的相信 hibernate会自行为我们处理性能的问题 或者 hibernate 会自动为我们的所有操作调用缓存 实际的情况是hibernate虽然为我们提供了很好的缓存机制和扩展缓存框架的支持 但是必须经过正确的调用其才有可能发挥作用!!所以造成很多使用hibernate的系统的性能问题 实际上并不是hibernate不行或者不好 而是因为使用者没有正确的了解其使用方法造成的 相反 如果配置得当hibernate的性能表现会让你有相当 惊喜的 发现 下面我讲解具体的配置方法
ibernate提供了二级缓存的接口
net sf hibernate cache Provider
同时提供了一个默认的 实现net sf hibernate cache HashtableCacheProvider
也可以配置 其他的实现 比如ehcache jbosscache等
具体的配置位置位于hibernate cfg xml文件中
- <property name= hibernate cache use_query_cache >true</property> <property name= hibernate cache provider_class >net sf hibernate cache HashtableCacheProvider</property>
很多的hibernate使用者在 配置到 这一步 就以为 完事了
注意 其实光这样配 根本就没有使用hibernate的二级缓存 同时因为他们在使用hibernate时大多时候是马上关闭session 所以 一级缓存也没有起到任何作用 结果就是没有使用任何缓存 所有的hibernate操作都是直接操作的数据库!!性能可以想见
正确的办法是除了以上的配置外还应该配置每一个vo对象的具体缓存策略 在影射文件中配置 例如
- <hibernate mapping> <class name= sobey *** m model entitySystem vo DataTypeVO table= dcm_datatype > <cache usage= read write /> <id name= id column= TYPEID type= java lang Long > <generator class= sequence /> </id> <property name= name column= NAME type= java lang String /> <property name= dbType column= DBTYPE type= java lang String /> </class> </hibernate mapping>
关键就是这个<cache usage= read write /> 其有几个选择read only read write transactional 等
然后在执行查询时 注意了 如果是条件查询 或者返回所有结果的查询 此时session find()方法 不会获取缓存中的数据 只有调用erate()方法时才会调缓存的数据
同时 get 和 load方法 是都会查询缓存中的数据
对于不同的缓存框架具体的配置方法会有不同 但是大体是以上的配置(另外 对于支持事务型 以及支持集群的环境的配置我会争取在后续的文章中中 发表出来)
Hibernate中一级缓存和二级缓存使用详解
一、一级缓存二级缓存的概念解释
(1)一级缓存就是Session级别的缓存,一个Session做了一个查询操作,它会把这个操作的结果放在一级缓存中,如果短时间内这个
session(一定要同一个session)又做了同一个操作,那么hibernate直接从一级缓存中拿,而不会再去连数据库,取数据;
(2)二级缓存就是SessionFactory级别的缓存,顾名思义,就是查询的时候会把查询结果缓存到二级缓存中,如果同一个sessionFactory
创建的某个session执行了相同的操作,hibernate就会从二级缓存中拿结果,而不会再去连接数据库;
(3)Hibernate中提供了两级Cache,第一级别的缓存是Session级别的缓存,它是属于事务范围的缓存。这一级别的缓存由hibernate管理
的,一般情况下无需进行干预;第二级别的缓存是SessionFactory级别的缓存,它是属于进程范围或群集范围的缓存。这一级别的缓
存可以进行配置和更改,并且可以动态加载和卸载。 Hibernate还为查询结果提供了一个查询缓存,它依赖于第二级缓存;
二、一级缓存和二级缓存的比较
(1)第一级缓存 第二级缓存 存放数据的形式相互关联的持久化对象 对象的散装数据 缓存的范围事务范围,每个事务都有单独的第一级
缓存进程范围或集群范围,缓存被同一个进程或集群范围内的所有事务共享并发访问策略由于每个事务都拥有单独的第一级缓存,不
会出现并发问题,无需提供并发访问策略由于多个事务会同时访问第二级缓存中相同数据,因此必须提供适当的并发访问策略,来保
证特定的事务隔离级别数据过期策略没有提供数据过期策略。
(2)处于一级缓存中的对象永远不会过期,除非应用程序显式清空缓存或者
清除特定的对象必须提供数据过期策略,如基于内存的缓存中的对象的最大数目,允许对象处于缓存中的最长时间,以及允许对象处
于缓存中的最长空闲时间物理存储介质内存内存和硬盘。
(3)对象的散装数据首先存放在基于内存的缓存中,当内存中对象的数目达到数
据过期策略中指定上限时,就会把其余的对象写入基于硬盘的缓存中。
(4)缓存的软件实现在Hibernate的Session的实现中包含了缓存的
实现由第三方提供,Hibernate仅提供了缓存适配器(CacheProvider)。用于把特定的缓存插件集成到Hibernate中。
(5)启用缓存的方式
只要应用程序通过Session接口来执行保存、更新、删除、加载和查询数据库数据的操作,Hibernate就会启用第一级缓存,把数据库
中的数据以对象的形式拷贝到缓存中,对于批量更新和批量删除操作,如果不希望启用第一级缓存,可以绕过Hibernate API,直接
通过JDBC API来执行指操作。
(6)用户可以在单个类或类的单个集合的粒度上配置第二级缓存。如果类的实例被经常读但很少被修改,就
可以考虑使用第二级缓存。
(7)只有为某个类或集合配置了第二级缓存,Hibernate在运行时才会把它的实例加入到第二级缓存中。
用户管理缓存的方式第一级缓存的物理介质为内存,由于内存容量有限,必须通过恰当的检索策略和检索方式来限制加载对象的数目。
Session的 evit()方法可以显式清空缓存中特定对象,但这种方法不值得推荐。第二级缓存的物理介质可以是内存和硬盘,因此第二
级缓存可以存放大量的数据,数据过期策略的maxElementsInMemory属性值可以控制内存中的对象数目。
(8)管理第二级缓存主要包括两个方面:选择需要使用第二级缓存的持久类,设置合适的并发访问策略:选择缓存适配器,设置合适的数据过期策略。
三、 一级缓存的管理
(1)当应用程序调用Session的save()、update()、savaeOrUpdate()、get()或load(),以及调用查询接口的 list()、iterate()或
filter()方法时,如果在Session缓存中还不存在相应的对象,Hibernate就会把该对象加入到第一级缓存中。当清理缓存时,
Hibernate会根据缓存中对象的状态变化来同步更新数据库。 Session为应用程序提供了两个管理缓存的方法: evict(Object obj)
:从缓存中清除参数指定的持久化对象。 clear():清空缓存中所有持久化对象。
(2)save、update、saveOrupdate、load、list、iterate、lock会向一级缓存存放数据;
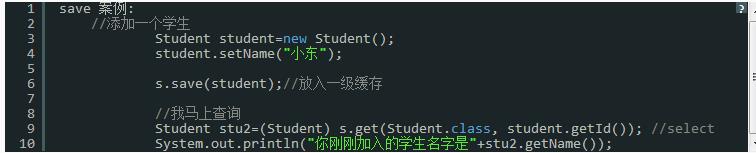
(3)什么操作会从一级缓存取数据:get、load、list
get / load 会首先从一级缓存中取,如没有.再有不同的操作[get 会立即向数据库发请求,而load 会返回一个代理对象,直到用户真的去使用数据,才会向数据库发请求;
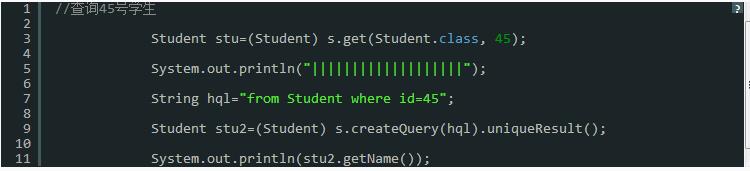
从上面的案例,我们看出 query.list() query.uniueResut() 不会从一级缓取数据! 但是query.list 或者query.uniqueRestu() 会向一级缓存放数据的.
注意:
① 一级缓存不需要配置,就可以使用,它本身没有保护机制,所以我们程序员要考虑这个问题,我们可以同 evict 或者 clear来清除session缓存中对象. evict 是清除一个对象,clear是清除所有的sesion缓存对象
② session级缓存中对象的生命周期, 当session关闭后,就自动销毁.
③ 我们自己用HashMap来模拟一个Session缓存,加深对缓存的深入.
四、Hibernate二级缓存的管理
1. Hibernate二级缓存策略的一般过程如下:
1) 条件查询的时候,总是发出一条select * from table_name where …. (选择所有字段)这样的SQL语句查询数据库,一次获得所有的数据对象。
2) 把获得的所有数据对象根据ID放入到第二级缓存中。
3) 当Hibernate根据ID访问数据对象的时候,首先从Session一级缓存中查;查不到,如果配置了二级缓存,那么从二级缓存中查;查不到,再查询数据库,把结果按照ID放入到缓存。
4) 删除、更新、增加数据的时候,同时更新缓存。
Hibernate二级缓存策略,是针对于ID查询的缓存策略,对于条件查询则毫无作用。为此,Hibernate提供了针对条件查询的Query Cache。
5) 二级缓存的对象可能放在内存,也可能放在磁盘.
2. 什么样的数据适合存放到第二级缓存中?
1) 很少被修改的数据
2) 不是很重要的数据,允许出现偶尔并发的数据
3) 不会被并发访问的数据
4) 参考数据,指的是供应用参考的常量数据,它的实例数目有限,它的实例会被许多其他类的实例引用,实例极少或者从来不会被修改。
3. 不适合存放到第二级缓存的数据?
1) 经常被修改的数据
2) 财务数据,绝对不允许出现并发
3) 与其他应用共享的数据。
4. 常用的缓存插件 Hibernater二级缓存是一个插件,下面是几种常用的缓存插件:
◆Ehcache:可作为进程范围的缓存,存放数据的物理介质可以是内存或硬盘,对Hibernate的查询缓存提供了支持。
◆OSCache:可作为进程范围的缓存,存放数据的物理介质可以是内存或硬盘,提供了丰富的缓存数据过期策略,对Hibernate的查询
缓存提供了支持。
◆SwarmCache:可作为群集范围内的缓存,但不支持Hibernate的查询缓存。
◆JBossCache:可作为群集范围内的缓存,支持事务型并发访问策略,对Hibernate的查询缓存提供了支持。
5. 配置Hibernate二级缓存的主要步骤:
1) 选择需要使用二级缓存的持久化类,设置它的命名缓存的并发访问策略。这是最值得认真考虑的步骤。
2) 选择合适的缓存插件,然后编辑该插件的配置文件。
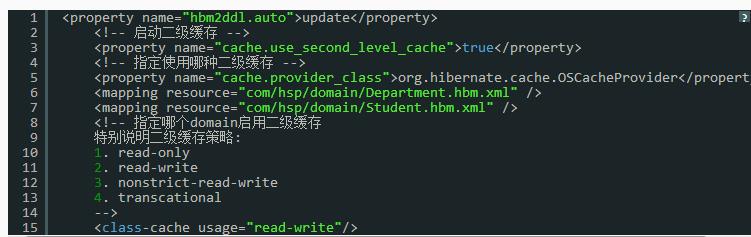
3)可以把oscache.properties文件放在 src目录下,这样你可以指定放入二级缓存的对象capacity 大小. 默认1000
6.使用二级缓存:
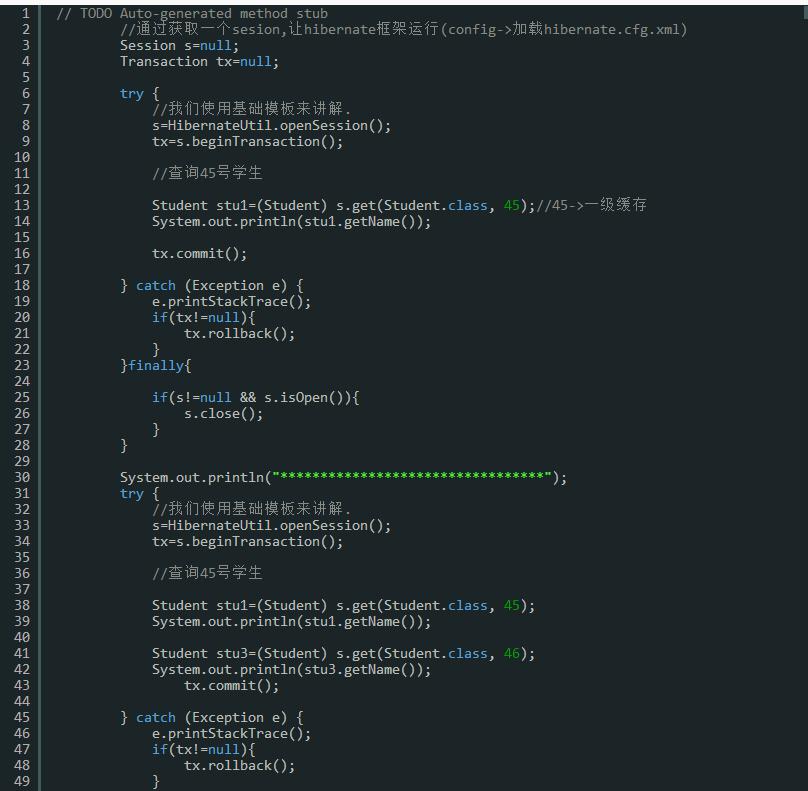
在配置了二级缓存后,请大家要注意可以通过 Statistics,查看你的配置命中率高不高
以上是关于Hibernate缓存何时使用和如何使用的主要内容,如果未能解决你的问题,请参考以下文章