如何使用Phoenix在HBase中创建二级索引
Posted YaoYong_BigData
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用Phoenix在HBase中创建二级索引相关的知识,希望对你有一定的参考价值。
一、Apache Phoenix是什么
首先Phoenix是HBase之上的SQL工具,至于HBase是什么,我就不介绍了,你若不懂,就不需要往下继续看了。Phoenix旨在通过标准的SQL语法来简化HBase的使用,并可以使用标准的JDBC连接HBase,而不是通过HBase的Java客户端APIs。它可以让你执行所有的CRUD和DDL操作,比如创建一张表,插入数据以及查询数据。SQL和JDBC可以大大减少用户代码的开发,当然它也提供一些性能优化的手段,通过SQL和JDBC,你可以更方便的将HBase集成到你现有的系统或者工具。
当Phoenix接收到SQL查询后,它会在本地编译成HBase的API,然后推到集群进行分布式的查询或计算。它自动创建了一个元数据库用来存储HBase的表的元数据信息。因为Phoenix是直接调用的HBase的API,coprocessors和自定义的filters,所以对于大量小查询可以实现毫秒级返回,千万级别的数据实现秒级返回。
二、pache Phoenix使用场景
Phoenix非常适合HBase的随机访问,它的二级索引特性同时可以让你实现非主键查询的快速返回,而不需要进行全表扫描。它可以让你像传统数据库表的方式创建和管理HBase中的表,同时Phoenix也支持复合主键。
Phoenix可以给Rowkey加盐,从而避免因为简单递增的Rowkey引起的RegionServer热点问题。通过指定不同的租户连接实现数据访问的隔离,从而实现多租户,租户只能访问属于他的数据。
虽然Phoenix有这么多优势,但是它依旧无法替代RDBMS。比如它还有以下限制:
-
Phoenix不支持跨行的事务
-
查询优化和join机制比大多数RDBMS要简陋
-
二级索引是通过索引表实现的,主表和索引表的同步会存在问题,虽然只是在一段很短的时间内。所以索引无法完全满足ACID
-
多租户功能比较简单
三、pache Phoenix与Hive/Impala的比较
Hive/Impala也可以作为HBase之上的SQL工具。包括Phoenix这3个工具在很多功能上都有一些重叠,比如它们都提供SQL执行以及JDBC驱动
不像Impala和Hive,Phoenix与HBase结合更加紧密,从而可以更好的利用HBase的一些特性,比如coprocessors和skip scans。
-
Phoenix的目标是在HBase之上提供一个高效的类关系型数据库的工具,定位为低延时的查询应用。Impala则主要是基于HDFS的一些主流文件格式如文本或Parquet提供探索式的交互式查询。Hive类似于数据仓库,定位为需要长时间运行的批作业。
-
Phoenix很适合需要在HBase之上使用SQL实现CRUD,Impala则适合Ad-hoc的分析类工作负载,Hive则适合批处理如ETL。
-
Phoenix非常轻量级,因为它不需要额外的服务。
-
Phoenix还支持一些高级功能,比如多个二级索引,flashback查询等。无论是Impala还是Hive都无法提供二级索引支持。
以下是比较:
| Apache Phoenix | Impala | Hive | |
| 语法 | SQL | SQL | HiveQL |
| 定位 | 为低延时应用在HBase之上提供高效的SQL查询 | 大数据集之上的交互式探索分析 | 批处理比如ETL |
| 二级索引 | Yes(无法保证ACID) | No | No |
| 额外的服务 | No | Yes | Yes |
| HBase的高级特性 | Yes | No | No |
四、Global Indexes(全局索引)
- 全局索引适用于读多写少业务;
- 全局索引绝大多数负载都发生在写入时,当构建了全局索引时,数据表的添加、删除和修改都会更新相关的索引表(数据删除了,索引表中的数据也会删除;数据增加了,索引表的数据也会增加);
- 读取时,Phoenix将选择最快能够查询出数据的索引表。默认情况下,除非使用Hint,如果SELECT查询中引用了其他非索引列,该索引是不会生效的;
- 全局索引一般和覆盖索引搭配使用,读的效率很高,但写入效率会受影响。
创建语法:
CREATE INDEX 索引名称 ON 表名 (列名1, 列名2, 列名3...)五、Local Indexes(本地索引)
- 本地索引适合写操作频繁,读相对少的业务;
- 当使用SQL查询数据时,Phoenix会自动选择是否使用本地索引查询数据;
- 在本地索引中,索引数据和业务表数据存储在同一个服务器上,避免写入期间的其他网络开销;
- 在Phoenix 4.8.0之前,本地索引保存在一个单独的表中,在Phoenix 4.8.1中,本地索引的数据是保存在一个影子列蔟中;
- 本地索引查询即使SELECT引用了非索引中的字段,也会自动应用索引的。
注意:创建表的时候指定了SALT_BUCKETS,是不支持本地索引的。
创建语法:
CREATE local INDEX 索引名称 ON 表名 (列名1, 列名2, 列名3...)六、Covered Indexes(覆盖索引)
Phoenix提供了一种叫Covered Index覆盖索引的二级索引。这种索引在获取数据的过程中,内部不需要再去HBase上获取任何数据,你查询需要返回的列的数据都会被存储在索引中。要想达到这种效果,你的select 的列,where 的列都需要在索引中出现。举个例子,如果你的SQL语句是 select name from hao1 where age=2,要最大化查询效率和速度最快,你就需要建立覆盖索引:
CREATE INDEX index1_c ON hao1 (age) INCLUDE(name);注意关键字INCLUDE,就是包含需要返回数据结果的列。这种索引方式的最大好处就是速度快,而我们也知道,索引就是空间换时间,所以缺点也很明显,存储空间耗费较多。Phoenix的索引其实就是建了一张HBase的表。你可以通过HBase Shell的list命令看到。查看表index1_c,你会发现,这张表一共三列,一列就是索引,第二列是RowKey,最后一列就是Name的值。很明显在这里记录的RowKey,就是为了快速查找HBase中的数据。只是这里用不到,Name已经被缓存在这张索引里面了,直接返回。

我们来看一下执行计划,首先看一下没有查询条件的计划,如下图,是一个全表扫描的计划:
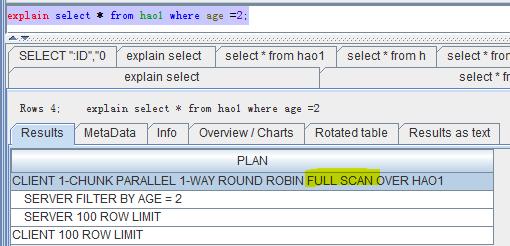
而加了索引以后,就是下图这样。很明显,已经是Range Scan,使用到了索引INDEX1_C。
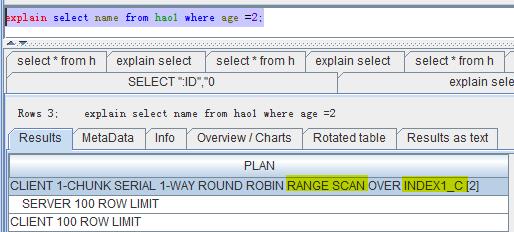
但要注意的是,如果是 select * from hao1 where age =2 的话,还是会看原数据表,只是使用RowKey去访问了,效率自然没有直接从索引表中回去。因为select 的其他列不在索引表内。
七、Functional Indexes(函数索引)
函数索引从从Phoenix4.3版本就有,这种索引的内容不局限于列,还能在表达式上建立索引。如果你使用的表达式正好就是索引的话,数据也可以直接从这个索引获取,而不需要从数据库获取。
1.在建立函数索引时,我们先执行两个查询语句好方便与建立索引以后的性能进行对比。
select s1,s7 from hbase_test where substr(s7,1,10)='1550864580';
select s1,substr(s7,1,10) from hbase_test where substr(s7,1,10)='1550864580';
2.建立函数索引
create index index2_hbase_test on hbase_test (substr(s7,1,10));3.再次执行前面的查询语句进行比较
select s1,s7 from hbase_test where substr(s7,1,10)='1550864580';
select s1,substr(s7,1,10) from hbase_test where substr(s7,1,10)='1550864580';
如果查询项包含substr(s7,1,10),则查询时间在毫秒级,而之前需要30多秒。如果查询项不包含substr(s7,1,10),则跟不建索引时是一样的。如果想让第一个查询语句走索引,我们可以在建立索引时采用INCLUDE(S7)来实现。
八、全局索引、本地索引不同点和比较
直白话:全局索引是表,适合重读轻写的场景 ;
本地索引是列族,适合重写轻读的场景。
1.索引数据
- global index单独把索引数据存到一张表里,保证了原始数据的安全,侵入性小;
- local index把数据写到原始数据里面,侵入性强,原表的数据量=原始数据+索引数据,使原始数据更大。
2.性能方面
- global index要多写出来一份数据,写的压力就大一点,但读的速度就非常快;
- local index只用写一份索引数据,节省不少空间,但多了一步通过rowkey查找数据,写的速度非常快,读的速度就没有直接取自己的列族数据快。
九、总结
Phoenix的二级索引主要有两种,即全局索引和本地索引。全局索引适合那些读多写少的场景。如果使用全局索引,读数据基本不损耗性能,所有的性能损耗都来源于写数据。本地索引适合那些写多读少,或者存储空间有限的场景。
索引定义完之后,一般来说,Phoenix会判定使用哪个索引更加有效。但是,全局索引必须是查询语句中所有列都包含在全局索引中,它才会生效。举个例子,下面是创建索引的语句:
create index my_index on hbase_test (s6);而查询语句是:
select s2 from hbase_test where s6='13505503576';上例就不会用到索引my_index。因为s2并没有包含在索引中。所以使用全局索引,必须要所有的列都包含在索引中。那么怎样才能使用索引呢?有三种方法。
1.创建索引时使用覆盖索引
CREATE INDEX index1_hbase_test ON hbase_test(s6) INCLUDE(s2)这种索引会把s2加到索引表里面,同时s2也会随着原数据表中的变化而变化。这种方式很明显的缺点是索引表的大小较大,然后就是全局索引不适合写特别多的情况。
2.使用类似于Oracle的Hint,强制索引
select /*+ INDEX(hbase_test index1_hbase_test)*/ s5 from hbase_test where s6='13505503576';

如果不带hint,查询时间为35s,带了hint强制使用索引后查询时间为0.099秒。
查询引擎会使用index1_hbase_test这个索引,由于它会发现索引表中没有s5数据,所以每一行它都会去原数据表中获取s5的值。这个强制索引只有在你认为索引有比较好的选择性的时候才是好的选择,也就是说s6等于13505503576的行数不多。不然的话,使用Phoenix默认的全表扫描的性能也许会更好。
这样的查询语句会导致二次检索数据表,第一次检索是去索引表中查找符合s6为13505503576的数据,这时候发现s5字段并不在索引字段中,会去hbase_test表中第二次扫描,因此只有当用户明确知道符合检索条件的数据较少的时候才适合使用,否则会造成全表扫描,对性能影响较大。
注:使用函数索引,查询语句中带上hint也没有作用。
3.创建本地索引
create local index index2_hbase_test on hbase_test (s7);本地索引和全局索引不同的是,查询语句中,即使所有的列都不在索引定义中,它也会使用索引,这是本地索引的默认行为。Phoenix知道原数据和索引数据在同一个RegionServer上,能保证索引查找是本地的。
以上是关于如何使用Phoenix在HBase中创建二级索引的主要内容,如果未能解决你的问题,请参考以下文章