MLP,GCN,GAT,GraphSAGE, GAE, Pooling,DiffPool
Posted super尚
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MLP,GCN,GAT,GraphSAGE, GAE, Pooling,DiffPool相关的知识,希望对你有一定的参考价值。
MLP GCN GAT区别与联系
在节点表征的学习中:
- MLP节点分类器只考虑了节点自身属性,忽略了节点之间的连接关系,它的结果是最差的;
- 而GCN与GAT节点分类器,同时考虑了节点自身属性与周围邻居节点的属性,它们的结果优于MLP节点分类器。
从中可以看出邻居节点的信息对于节点分类任务的重要性。
基于图神经网络的节点表征的学习遵循消息传递范式:
- 在邻居节点信息变换阶段,GCN与GAT都对邻居节点做归一化和线性变换(两个操作不分前后);
- 在邻居节点信息聚合阶段都将变换后的邻居节点信息做求和聚合;
- 在中心节点信息变换阶段只是简单返回邻居节点信息聚合阶段的聚合结果。
GCN与GAT的区别在于邻居节点信息聚合过程中的归一化方法不同:
-
前者根据中心节点与邻居节点的度计算归一化系数;
-
后者根据中心节点与邻居节点的相似度计算归一化系数。
-
前者的归一化方式依赖于图的拓扑结构,不同节点其自身的度不同、其邻居的度也不同,在一些应用中可能会影响泛化能力。
-
后者的归一化方式依赖于中心节点与邻居节点的相似度,相似度是训练得到的,因此不受图的拓扑结构的影响,在不同的任务中都会有较好的泛化表现。
另外,GCN利用了拉普拉斯矩阵,GAT利用attention系数。一定程度上而言,GAT会更强,因为 顶点特征之间的相关性被更好地融入到模型中。
一些问题
GCN是一种全图的计算方式,一次计算就更新全图的节点特征。学习的参数很大程度与图结构相关,这使得GCN在inductive任务上遇到困境。
- 为什么GAT适用于有向图?
我认为最根本的原因是GAT的运算方式是逐顶点的运算(node-wise),这一点可从公式(1)—公式(3)中很明显地看出。每一次运算都需要循环遍历图上的所有顶点来完成。逐顶点运算意味着,摆脱了拉普利矩阵的束缚,使得有向图问题迎刃而解。
- 为什么GAT适用于inductive任务?
GAT中重要的学习参数是 W 与 a(·) ,因为上述的逐顶点运算方式,这两个参数仅与顶点特征相关,与图的结构毫无关系。所以测试任务中改变图的结构,对于GAT影响并不大,只需要改变 Ni,重新计算即可。
与此相反的是,GCN是一种全图的计算方式,一次计算就更新全图的节点特征。学习的参数很大程度与图结构相关,这使得GCN在inductive任务上遇到困境。
GCN GAT GraphSAGE
GraphSAGE的提出
前面说的GCN的缺点也是很显然易见的,第一,GCN需要将整个图放到内存和显存,这将非常耗内存和显存,处理不了大图;第二,GCN在训练时需要知道整个图的结构信息(包括待预测的节点), 这在现实某些任务中也不能实现(比如用今天训练的图模型预测明天的数据,那么明天的节点是拿不到的)。
在介绍GraphSAGE之前,先介绍一下Inductive learning和Transductive learning。注意到图数据和其他类型数据的不同,图数据中的每一个节点可以通过边的关系利用其他节点的信息。这就导致一个问题,GCN输入了整个图,训练节点收集邻居节点信息的时候,用到了测试和验证集的样本,我们把这个称为Transductive learning。然而,我们所处理的大多数的机器学习问题都是Inductive learning,因为我们刻意的将样本集分为训练/验证/测试,并且训练的时候只用训练样本。这样对图来说有个好处,可以处理图中新来的节点,可以利用已知节点的信息为未知节点生成embedding,GraphSAGE就是这么干的。
GraphSAGE是一个Inductive Learning框架,具体实现中,训练时它仅仅保留训练样本到训练样本的边,然后包含Sample和Aggregate两大步骤,Sample是指如何对邻居的个数进行采样,Aggregate是指拿到邻居节点的embedding之后如何汇聚这些embedding以更新自己的embedding信息。下图展示了GraphSAGE学习的一个过程
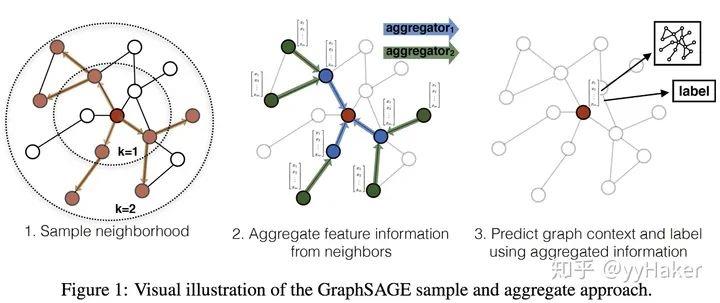
第一步,对邻居采样(k=1,第一跳最多采样3个;k=2,第二跳最多采样两个)
第二步,采样后的邻居embedding传到节点上来,并使用一个聚合函数聚合这些邻居信息以更新节点的embedding(从最内层开始更新,总共对红色节点更新两次)
第三步,根据更新后的embedding预测节点的标签
GrapgSage优点
(1)利用采样机制,很好的解决了GCN必须要知道全部图的信息问题,克服了GCN训练时内存和显存的限制,即使对于未知的新节点,也能得到其表示
(2)聚合器和权重矩阵的参数对于所有的节点是共享的
(3)模型的参数的数量与图的节点个数无关,这使得GraphSAGE能够处理更大的图
(4)既能处理有监督任务也能处理无监督任务
Graph Attention Networks(GAT)
为了解决GNN聚合邻居节点的时候没有考虑到不同的邻居节点重要性不同的问题,GAT借鉴了Transformer的idea,引入masked self-attention机制,在计算图中的每个节点的表示的时候,会根据邻居节点特征的不同来为其分配不同的权值。
GAT优点
(1)训练GCN无需了解整个图结构,只需知道每个节点的邻居节点即可
(2)计算速度快,可以在不同的节点上进行并行计算
(3)既可以用于Transductive Learning,又可以用于Inductive Learning,可以对未见过的图结构进行处理
三者特点
GCN:训练是 full-batch 的,难以扩展到大规模网络,并且收敛较慢;
GAT:参数量比 GCN 多,也是 full-batch 训练;只用到 1-hop 的邻居,没有利用高阶邻居,当利用 2 阶以上邻居,容易发生过度平滑(over-smoothing);
GraphSAGE:虽然支持 mini-batch 方式训练,但是训练较慢,固定邻居数目的 node-wise 采样,精度和效率较低。
三者的缺点:
1.GCN 的缺点在于它灵活性差,transductive,并且扩展性非常差,除此之外这篇论文借助验证集来早停帮助性能提升,跟它半监督学习的初衷有点相悖。
2.GraphSage 这篇论文旨在提升 gcn 扩展性和改进训练方法缺陷。它将模型目标定于学习一个聚合器而不是为每个节点学习到一个表示,这中思想可以提升模型的灵活性和泛化能力。除此之外,得益于灵活性,它可以分批训练,提升收敛速度。但是它的问题是因为节点采样个数随层数指数增长,会造成模型在 time per batch 上表现很差,弱于 GCN,这方面的详细讨论可以参考 Cluster-GCN 这篇论文。
3.GAT 这篇论文创新之处是加入 attention 机制,给节点之间的边以重要性,帮助模型学习结构信息。相对的缺点就是训练方式不是很好,其实这个模型可以进一步改,用 attention 做排序来选取采样节点,这样效果和效率方面应该会有提升。
共同缺点
这三种模型针对的图结构都是 homogeneous 的,也就是只有同一种节点和连边,如果是异质网络(heterogeneous)则不能直接处理。能解决的任务目前来说主要是通过 embedding 做节点分类和连边预测。
三者应用方面区别
GCN 和 GraphSAGE 均是各向同性的网络结构,某些情况下学习表示的能力较差一些,只能用于无向图。而 GAT 是各向异性的,考虑了各个邻居节点的权重,可以用于有向图。
GCN 和 GAT 在最开始被提出来的时候,是不考虑自身节点信息的,因此性能比较差,后来人们对图矩阵增加自环的方式来一定程度上缓解这个问题。而 GraphSAGE 被设计出来就考虑了节点本身的信息。
BenchmarkGNN 文章在各个任务上对这几种方法进行了比较,GCN 是性能最差的,GAT 性能介于中间,GraphSAGE 性能较好。另外 GCN 和 GAT 均可以使用残差连接的方式来提升性能。
参考:
MLP GCN GAT
GCN与GAT之间的重要联系和区别
GCN, GAT, GraphSAGE对比【整理】
图神经网络入门必读: 一文带你梳理GCN, GraphSAGE, GAT, GAE, Pooling, DiffPool
以上是关于MLP,GCN,GAT,GraphSAGE, GAE, Pooling,DiffPool的主要内容,如果未能解决你的问题,请参考以下文章