抓 Bug 神器的工作原理——聊聊 Sentry 的架构
Posted FesonX
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了抓 Bug 神器的工作原理——聊聊 Sentry 的架构相关的知识,希望对你有一定的参考价值。
Sentry 是什么?这是一个用于错误上报的服务中心,使用近乎一致的 API 设计,统一了不同语言生产环境代码异常上报的难题。
文章目录

2020 年二月份,领导让我负责在公司内部测试和使用 Sentry,彼时 Sentry 的文档还不是很完善,我也只是初步接触基础服务的搭建,Sentry 于我而言就是一个黑盒子。
2016 年,Sentry 的开发者答复说**目前没有任何关于 Sentry 架构的公开资料,最佳的途径就是阅读源码:)**这个工程量确实比较大,我个人在使用 Docker-compose 搭建 Sentry 时,借用一连串的日志输出来观察整个数据流,根据服务间的依赖也只能猜测大致的架构。
2020 年下半年,Sentry 开始陆续将文档补全,这个项目的架构图终被公开,结合其他文档,Sentry 的数据流浮出水面。
架构概述
下方这个图是根据 Sentry 官方文档重绘的,我把所有存储相关的组件用紫色的图形做了区分,其他 Sentry 服务组件用蓝色表示(除了顶部的应用)。
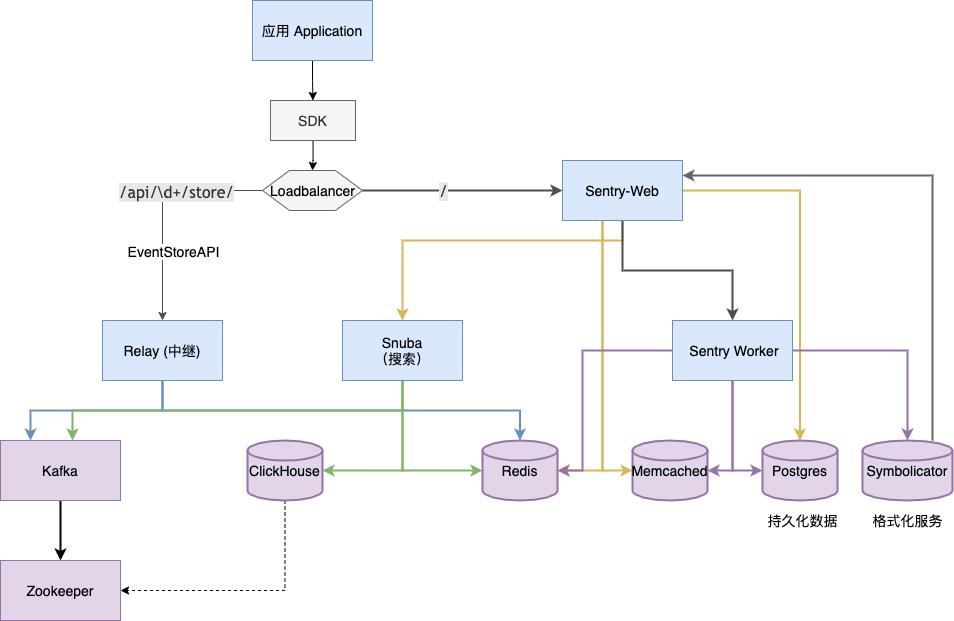
这样画下来之后,服务基本就分层完毕:
- Loadbalancer(负载均衡器)负责路由转发(这一服务由用户搭建),错误上报转发到
/api/\\d+/store,其他项目、成员、错误管理功能由 Sentry Web 负责。这一层的承担数据入口、展示的作用 - Relay 负责消息中继转发,并把数据先汇集到 Kafka;Snuba 负责接收 SentryWeb 的请求,进行数据的聚合、搜索;Sentry Worker 则是一个队列服务,主要负责数据的存储。
- Kafka 作为消息队列,ClickHouse 负责接近实时的数据分析,Redis(主要) 和 Memcached 负责项目配置、错误基础信息的存储和统计。Postgres 承担基础数据持久化(主要是项目、用户权限管理等)Symbolicator 主要用于错误信息格式化。
- 最底下的 Zookeeper 是 Kafka 用于节点信息同步的,如果我们设置了多个 ClickHouse 节点,也可以用它来保存主从同步信息或者做分布式表。
Relay —— 错误信息处理的中转站
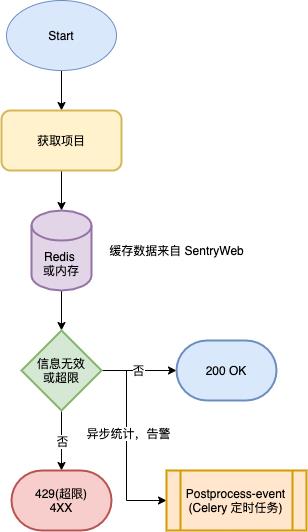
Relay 收到原始数据后,主要做这几件事。
- 对其格式进行有效性校验
- 查询内存或者从 Redis 拉取缓存得到项目配置信息,校验请求是否合法(项目是否存在或者有没有触发限流,没触发限流则会对 API 额度进行累计,写入 Redis)
- 发起一个异步请求给定时任务(SentryWorker,postprocess-event)做下一步处理
Kafka 和 Celery —— 应用解耦和异步保存数据
Relay 数据转发到 Kafka 的 ingest-events Topic(Ingest 即摄取),消费者消费后把消息放入 postprocess-event 这个 Celery 定时任务服务排队处理。队列做的事情如下
- Symbolicate-event,在 ios 上有个叫 symbolicate-crash 的工具,是将机器的崩溃日志转化为可读的崩溃代码定位日志,这里的 Symbolicator 同样承担类似的职能,由它经手的消息,我们就可以在页面上看到代码在哪里出错了。
- process-event,字面含义就是处理消息,在 Sentry 上启用的插件(Plugins or Integration)会在这个步骤中应用到消息体上,例如,整合了一个 Slack bot(机器人),就会在这个步骤发送告警。
- save-event,消息经过简化,保存到数据库,同时再次发到 Kafka,但这次换到 event Topic,Snuba 这个搜索组件内部会有一个消费者,对这部分数据批量写入到 ClickHouse。你可能好奇为什么不直接存进去算了还要搞多这一步,这是因为 ClickHouse 虽然大数据量处理能力很强,但频繁写入能力是真的菜鸡(假设做了主从,那就更灾难了,把从库和 Zookeeper 都一起拉下水),所以需要 Snuba 来限制写入频率。
Sentry Web
Sentry Web 这边主要跟配置等持久化数据打交道,创建项目、权限控制、限流分配等都是它负责。查询搜索错误消息、Dashboard 聚合等功能则是 Snuba 承担,由它来当翻译官,把用户查询条件转化为 SQL 语句发给 ClickHouse。
题外话 —— 为什么 Sentry 适合商用
以往的开源项目大部分可以看成是单个组件,升级修复的工作量对一般的工程师而言还是可以接受的。但是 Sentry 这个错误上报服务背后却是十几二十个微服务组成的,一次服务升级可能涉及到很多个微服务、存储服务,瞬间依赖爆炸,测试无从下手。
对于小公司而言,如果不使用 Docker,搭建一个 Sentry 服务,就需要很多台服务器,如果要做主从、集群还需要再乘以 N,如果要做 TLS,又得花大笔钱去购置证书。本来是想节省代码查错的时间成本,可能最后却多花了钱在部署和运维上。
单租户隔离(Single Tenant Isolation)、持续集成测试、TLS 加密、容灾都交给了 Sentry 来做,给它打钱自然而然地成了最划算的方案,不得不说,真羡慕这种站着赚钱的项目:)。
参考资料
- [Question] Sentry Architecture #3419
- Path of an Event through Relay
- Sentry: Event Ingestion Pipeline
- Introducing Snuba: Sentry’s New Search Infrastructure
- The Architecture Of Sentry
以上是关于抓 Bug 神器的工作原理——聊聊 Sentry 的架构的主要内容,如果未能解决你的问题,请参考以下文章