JackHttp -- 从原理来理解 HTTP
Posted JackWaiting
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JackHttp -- 从原理来理解 HTTP相关的知识,希望对你有一定的参考价值。
在介绍 HTTP 之前,首先我们来思考几个问题
- HTTP 到底是什么?
- HTTP 在整个网络通信中扮演着怎样的角色?
- HTTP 是如何进行通信的呢?
带着这 3 个问题 ,我们来开始今天的内容。(当然,如果大神对这3个问题比较清楚,可以直接跳到末文看总结)。
在理解 HTTP 之前,首先我们得先来看看 TCP/IP 协议族是什么?
简介TCP/IP
定义:
TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/网际协议)是指能够在多个不同网络间实现信息传输的协议簇。TCP/IP 协议不仅仅指的是 TCP 和 IP 两个协议,而是指一个由 FTP、SMTP、TCP、UDP、IP 等协议构成的协议簇, 只是因为在TCP/IP 协议中 TCP 协议和 IP 协议最具代表性,所以被称为TCP/IP协议。
看上面的描述一大堆,不需要死记硬背,我们只需要有一个概念,也就是 TCP/IP 的本质。
本质:
一系列协议所组成的一个网络分层模型。
哦,,搞半天你是个协议族,还分层?分几层 ?为啥子要分层?
具体分层:
| OSI 七层模型 | TCP/IP 模型 | 功能 | TCP/IP 具体包含的协议 |
|---|---|---|---|
| 应用层 | 应用层 | 文件传输,电子邮件,文件服务,虚拟终端 | TFTP,HTTP,SMMP,FTP,SMTP,DNS,Telnet |
| 表示层 | 应用层 | 数据格式化,代码转换,数据加密 | 没有协议 |
| 会话层 | 应用层 | 接触或建立与别的接点的联系 | 没有协议 |
| 传输层 | 传输层 | 提供端到端的接口 | TCP,UDP |
| 网络层 | 网络层 | 为数据包选择路由 | IP,ICMP,RIP,OSPF,BCP,ICMP |
| 数据链路层 | 链路层 | 传输由地址的帧以及错误功能检测 | SLIP,CSLIP,PPP,ARP,RARP,MTU |
| 物理层 | 链路层 | 以二进制数据形式在物理媒体上传输数据 | ISO2110,IEEE802,IEEE802.2 |
简单的看这个图似乎好像有些复杂,这里我们只需要了解三点:
- TCP/IP 的分层是从开放系统互联 OSI (Open System Interconnection)模型演变而来的。
- TCP/IP 与 OSI 在分层模块上有些区别,OSI 参考模型注重“通信协议必要的功能是什么”,而 TCP/IP 则更强调“在计算机上实现协议应该开发哪种程序”。
- 在 TCP/IP 协议中,它们被简化为了四层.分别是应用层、传输层、网络层、链路层
知道以上信息再结合我们实际的开发,其实上面这个表可再以优化一下,把我们常用的协议取出,如下:
| TCP/IP 模型 | TCP/IP 具体包含的协议 |
|---|---|
| 应用层 | HTTP,FTP,DNS |
| 传输层 | TCP,UDP |
| 网络层 | IP |
| 数据链路层 | 路由,WIFI |
这样看就简洁多了吧,OK,回到之前我们的疑问,我们现在大致了解了 TCP/IP 协议族确实需要分层,并且是分四层,那么,重点来了?到底为什么需要分层呢?
核心原因,主要是网络的不可靠性,或者说是网络的不稳定造成的。 假设我们的网络是稳定可靠的,那么应用层软件其实可以直接和链路层设备进行通信,哪还需要中间这么复杂的过程。其中 TCP 协议的三次握手和他的窗口(吞吐量)也主要是来处理网络的不稳定和不可靠性的,后面的文章中会讲到。另外分层的次要原因还考虑到安全、节约宽带、方便管理等。
弄明白上面几个问题后,我们对 HTTP 在网络通信中扮演的角色已经有了一个初步的了解。读到这里我们可以对本文开头的第二个问题进行回答了,哦!!!,原来 HTTP 在整个网络通信(TCP/IP 协议族)中属于应用层的一个协议,用于和传输层进行通信。
那么到底什么是 HTTP?
我们平时感受到 HTTP 比较直观的是两个场景
- 在我们游览器地址栏啪输入“www.jackwaiting.com”,啪,一个界面出来了。
- 在我们编写软件程序的时候,拿到后台的一个接口。例如:“https://www.jackwaiting.com?xxx=“xxx” ” 然后对这个 HTTP 请求做一系列的描述,什么请求方法咯,GET/POST , 请求行,请求 Body,返回码,XXXX 一大堆,对吧?
定义:
HTTP 是超文本传输协议(HyperText Transfer Protocol)。
注意:Hyper 这里的“超”指的是“拓展”的意思,不是“超级”的意思。
超文本?
解释:再我们屏幕前看到的文本中,含有可以跳转到其它文本链接的文本。
怎么去理解呢,例如我们这篇博客,在开头定义了一个 “JackHttp 系列的介绍”的超链接,可以跳转到另外一个链接对吧?那么是不是就是说 “JackHttp 系列的介绍”就是超本文呢?可以这么说,但是,,,,,我们这整篇文章也可以说成是超文本,编写这篇博客的工具MarkDown 也能称之为超文本,甚至是显示的代码 html 也含有这种能力,也能称之为超文本,能明白吗?也就是小到一个网络请求的文本 “http://www.baidu.com” ,大到一个 HTML,凡是含有可以跳转到其它文本链接的文本,都能称之为超文本。
为什么定义 HTTP,其目的是什么?
我尽量用我的理解来解释清楚:两个陌生的机器要交换数据,就像我们人与人之间一样,我们需要“租房、购房、吃饭,购物上网”等等行为,“租房我们需要签订合同,购房不仅需要签订合同,风险比较大,还需要在政府备案网签,HTTPS?吃饭商家也会提供一个菜单,购物我们用户和淘宝其实也会签订《用户协议》《用户隐私协议》,有注意到吧?淘宝与商家也会遵循彼此签订的协议”。这些日常生活中的行为视乎都有一个协议再约束我们,如果哪一方不按照彼此的协议做事情,就会有对应的惩罚,表现在计算机里的就会给不同的端进行报错。
那么定义 HTTP 协议目的就是为了规定客户端和服务端 数据传输的格式 和 数据交互行为 ,定义好了 HTTP 协议,客户端与服务端之间沟通起来将会更加方便,省力,省带宽。
HTTP 工作原理
饶了这么大的圈,有点感觉了,哦!!!,客户端想和某服务器进行通信,需要给服务器发送一个超本文?

万丈高楼平地起! 我们按照 HTTP 协议说的方式在游览器中做一个简单的 HTTP 请求试试,在地址栏输入“http://jackwaiting.com”, 通过按 F12 追踪看看发送的是一个怎样的超文本。
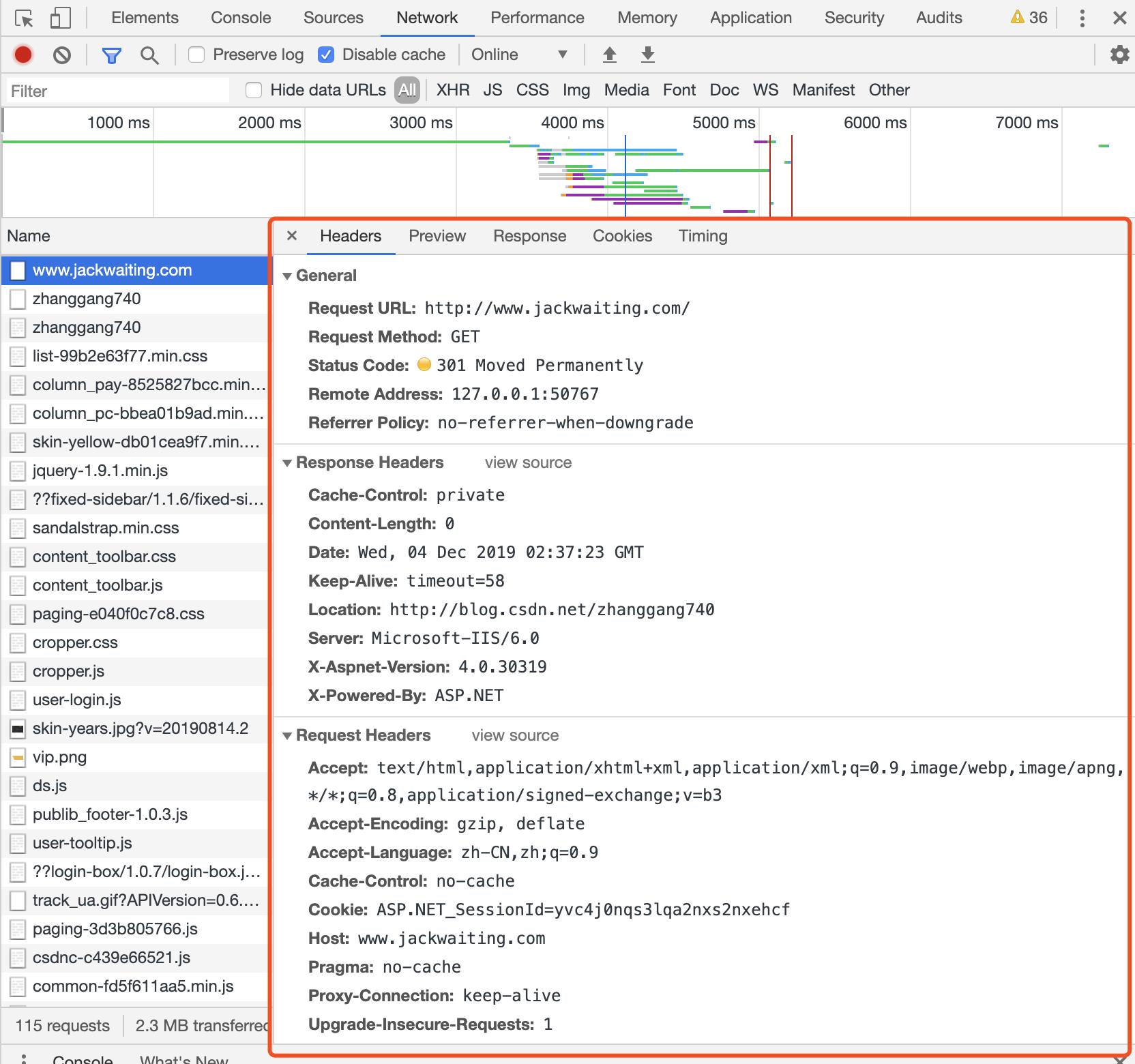
从这个图中,我们能挖出哪些信息呢,比较直观的:
- 发送一个超文本似乎需要包含 Headers、Preview、Response、Cookies、Timing
- 在 Headers 中还包含 General, Response Headers , Request Headers
- 观察地址栏发现会跳转到 “https://blog.csdn.net/zhanggang740”, 并不是我们输入的 “http://jackwaiting.com”, 细心点看你会发现在 Headers ->General 用一个黄色小圆球标记了一个 Status Code 301? 并且在 Headers -> Response Headers -> Location 中找到"https://blog.csdn.net/zhanggang740",此时我们隐隐的感觉到似乎跳转到了"https://blog.csdn.net/zhanggang740"。
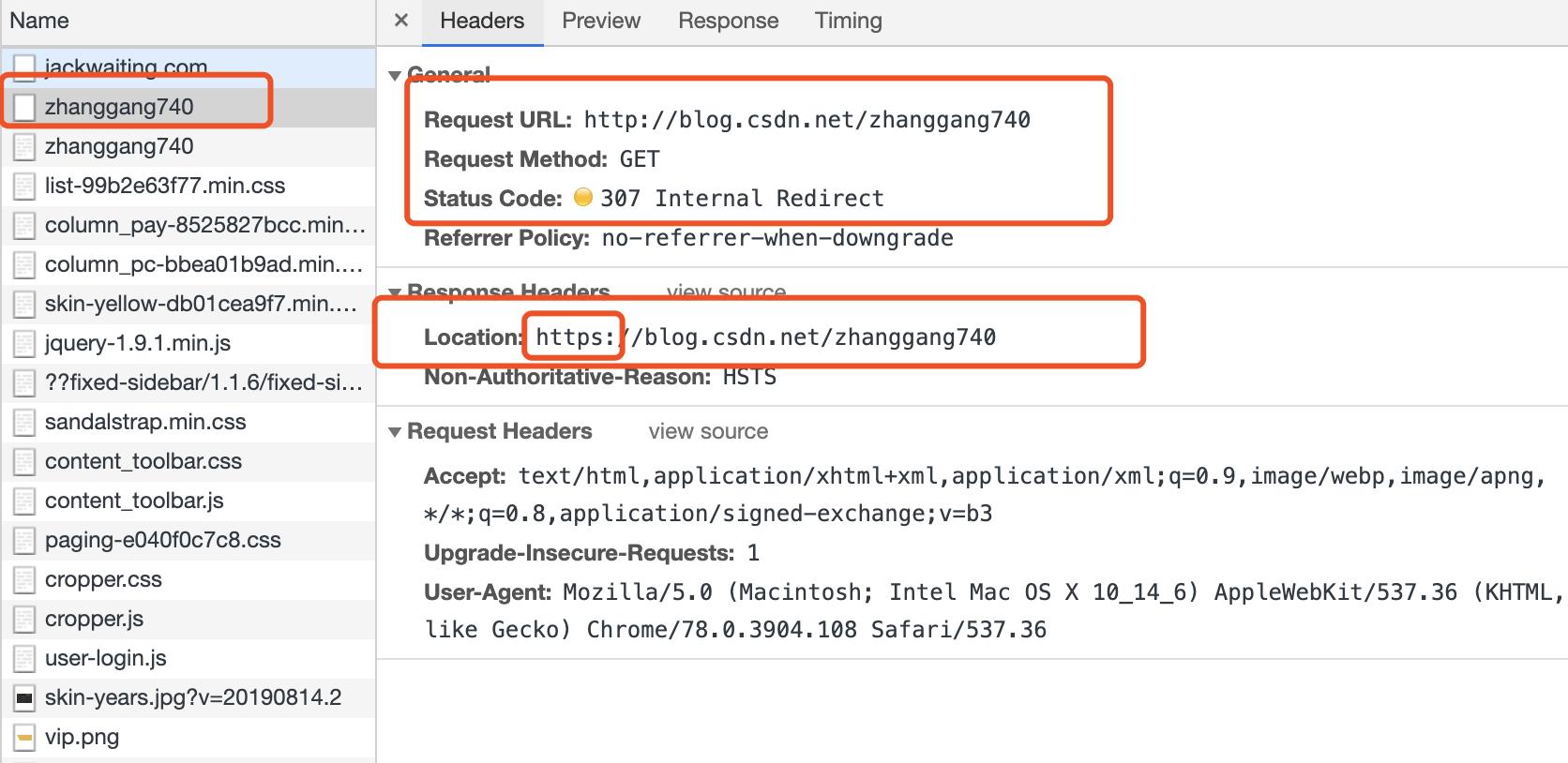
what fuck? 又来了个307?跳到了https? 还没有结束?四连问,我们在往下看。

咦,状态码变绿了?返回 200?
看到这里,如果此时你是一个 android 程序猿,似乎找到一丝熟悉感,这不就是平时收到服务器返回给我的响应码?但仔细一想平时我做网络请求时也重来没写过这么多的请求 Headers,也没有收到过什么 301,307 更不会察觉到还建立了 https 的连接,这很正常。
其实如果在我们 APP 中发送“http://jackwaiting.com”这个请求,同样会经历上面的所有过程,只是在 Android 中, okhttp 已经帮我们做了这些事情而已。
我简单的说一下,暂时你只需要了解即可,当 okhttp 的拦截器接收到“http://jackwaiting.com”请求到来时,会逐步依次调用如下拦截器
RetryAndFollowUpInterceptor
BridgeInterceptor
CacheInterceptor
ConnectInterceptor
CallServerInterceptor
在我们这个例子中 RetryAndFollowUpInterceptor 会对我们的重定向异常 301、307 进行拦截,重新再次发送请求,BridgeInterceptor 会帮我们补充请求过程中所需要的 Headers 信息
ConnectInterceptor 会去建立 TCP Connect、SSL 连接(HTTPS 连接),然后通过CallServerInterceptor 发射请求,直到接收到响应 200 的状态码,此次 HTTP 请求结束,大概是如下流程:
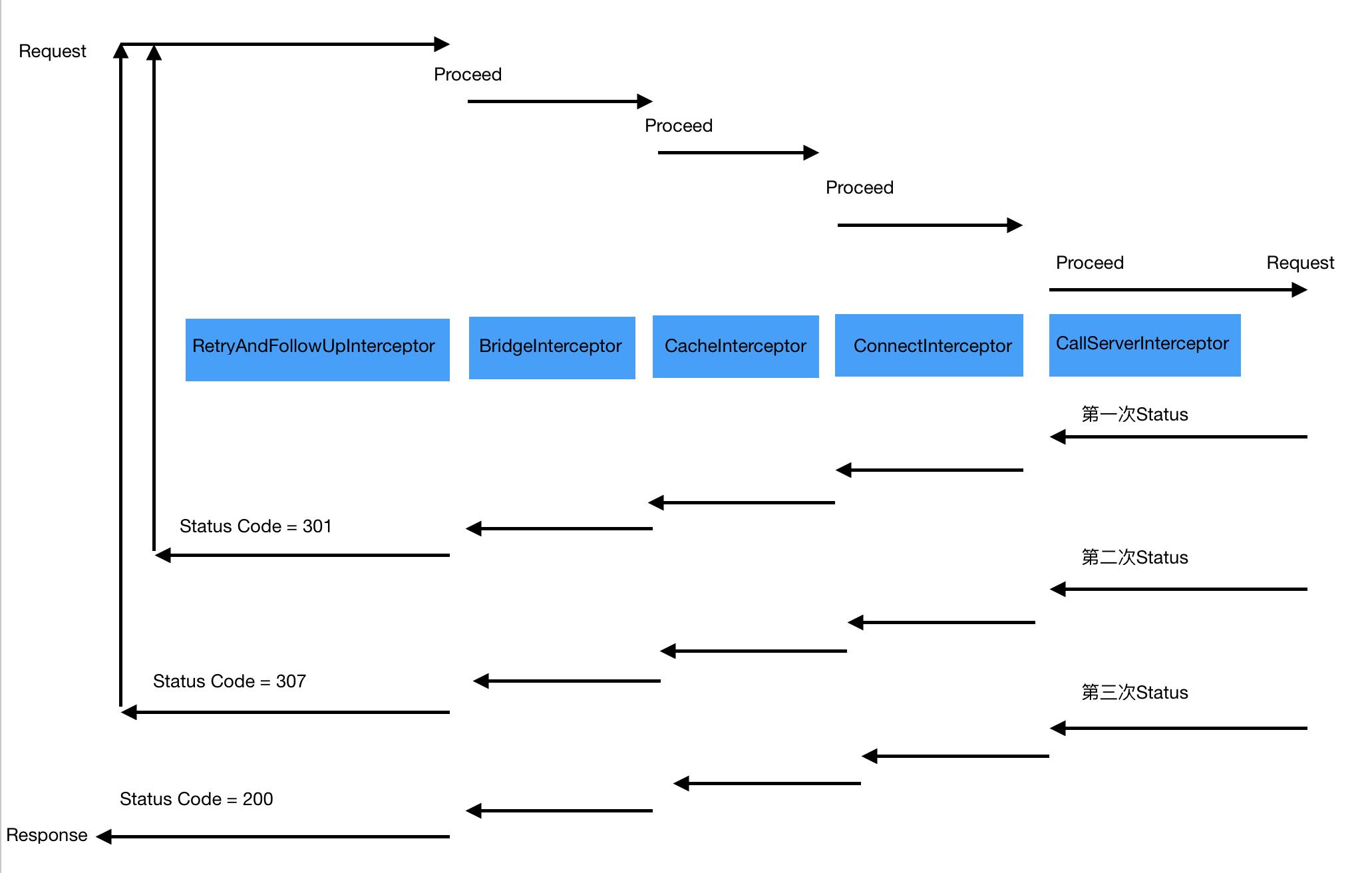
所以作为前端程序员可能只会感知到服务器返回的 200,中间的内容无法察觉,或者说不关心,那是因为 Okhttp 帮我们实现了,这里看不懂也没关系,后期会详解 Okhttp 的工作原理和源码。
搞明白了这个过程,在来分析上面的那几张图剩下的内容:
- Preview 是这个请求后服务器返回给我们内容预览,很直观的感觉到,这不是协议所要求的。
- Response 是服务器返回的 “https://blog.csdn.net/zhanggang740” HTML 文本以此来展示网页内容,是你,没得跑。
- Cookies 保存着一些属性值,暂时不知道是干嘛的
- Timing 记录的是一些连接时间,请求时间等。似乎也是一些可视化内容,我们不需要关心。
从这次请求我们似乎可以观察到客户端发送一个请,客户端还会返回一个响应,中间会有一些Header,Cookes 等信息,如下图
我们对上图再次进行拆分,了解其本质
- 客户端是如何把一个"http://jackwaiting.com" 转换成一个请求的,转换的标准是什么?
- 一个转换后的标准是如何发送到服务器的?
- 服务器返回的响应是怎样的标准?
- 响应标准怎样返回到客户端?
URL -> HTTP 报文
报文(message)是网络中交换与传输的数据单元,即站点一次性要发送的数据块。报文包含了将要发送的完整的数据信息,其长短很不一致,长度不限且可变。
格式标准
在理解格式标准前,我先简单说明一下,本文将使用 HTPP 1.1 的格式标准来讲解,原因如下:
- HTTP 发展至今,已经衍生出了多个版本,从 HTTP 0.9 -> HTTP 1.0 -> HTTP 1.1 -> SPDY 协议 -> HTTP 2.0 。其中 HTTP 1.0 由于默认是短连接,每次与服务器交互,都需要新开一个连接,至今基本已经被弃用了。(1.0 都弃用了,0.9 不用说啦吧)。
- SPDY 协议是 HTTP 2.0 的基础, HTTP 2.0 在市场上还没有完全普及,在部分手机的兼容性上还没有完全适配。
- HTTP 2.0 协议的格式和 HTTP 1.1 虽然完全不同了,但实际上 HTTP 2.0 并没有改变 HTTP 1.1 的语义,只是把原来 HTTP 1.1 的 Header 和 Body 部分用 Frame 重新封装了一层而已。
那么一个 HTTP 1.1 报文具体长什么样子?
Request = Request-Line ; Section 5.1
*(( general-header ; Section 4.5
| request-header ; Section 5.3
| entity-header ) CRLF) ; Section 7.1
CRLF
[ message-body ] ; Section 4.3
这是一个典型的请求报文,从报文格式中可以看出,一个 Request 请求包含 4 部分
- 请求行(Request - Line)
- 请求头 ( general-header| request-header| entity-header )
- 空行( CRLF)
- 请求体(message-body)
那么,这 4 个部分具体都包含哪些内容呢?
请求行(Request - Line)
常用的请求行包含 请求资源的方法,请求资源的路径(相对路径、绝对路径),使用的协议版本 3 个部分,如下:
1、Request-URI = "*" | absoluteURI | abs_path | authority
其中请求方法主要包含
GET:获取资源(不带Body)
POST:传输实体主体(带Body)
PUT:传输资源文件
DELETE:删除资源文件
HEAD:获得此次请求的报文首部
TRACE:追踪路径
CONNECT:保留
OPTIONS:询问支持的方法
例如我们本文的 URL “http://blog.csdn.net/zhanggang740” 转换成请求行就是这个样子,其中第一种更为常见。
第一种格式
GET /zhanggang740 HTTP/1.1
Host: blog.csdn.net
第二种
GET http://blog.csdn.net/zhanggang740 HTTP/1.1
Host: www.haust.edu.cn
请求头( Request-header)
我们接下来对一些重要的请求头做一些分享。
Host
请求资源所在的服务器。
Accept
Accept 代表客户端希望接受的数据类型。
常见的媒体格式类型如下:
| 媒体类型 | 格式 |
|---|---|
| text/html | HTML 格式 |
| text/plain | 纯文本格式 |
| text/xml | XML 格式 |
| image/gif | GIF 图片格式 |
| image/jpeg | JPG 图片格式 |
| image/png | PNG 图片格式 |
| application/xhtml+xml | XHTML 格式 |
| application/xml | XML 数据格式 |
| application/atom+xml | ATOM XML 聚合格式 |
| application/json | JSON 数据格式 |
| application/pdf | PDF 格式 |
| application/msword | WORD 文档格式 |
| application/octet-stream | 二进制流数据(如常见的文件下载) |
| application/x-www-form-urlencoded | 普通表单,Encoded URL 格式 ,只能传文本,不能传二进制数据 |
| multipart/form-data | 多部分形式,一版用于传输包含二进制内容的多项内容 |
跟Accept 相关的几个Header。
| Header | 说明 |
|---|---|
| Accept-Charset | 声明浏览器支持的字符集 |
| Accept-Encoding | 声明客户端支持的编码类型的 |
| Accept-Langulage | 声明客户端支持的语言 |
Referer
HTTP Referer 是 Header 的一部分,当客户端向服务器发送请求的时候,一般会带 Referer 告诉服务器该请求是从哪里链接过来的,服务器因此可以获得一些信息用于处理。
Referrer Policy
Referrer 用于记录这次请求的来源。
目前最新的 Referrer Policy 规定了五种 Referrer 策略:
-
No Referrer When Downgrade
- 仅当发生协议降级(如 HTTPS 页面引入 HTTP 资源,从 HTTPS 页面跳到 HTTP 等)时不发送 Referrer 信息。 Origin Only
-
发送只包含 Host 部分的 Referrer。启用这个规则,无论是否发生协议降级,
无论是本站链接还是站外链接,都会发送 Referrer 信息,但是只包含协议 + host 部分(不包含具体的路径及参数等信息)。
Origin When Cross-origin
-
仅在发生跨域访问时发送只包含 Host 的 Referrer,同域下还是完整的。
它与 Origin Only 的区别是多判断了是否 Cross-origin。需要注意的是协议、域名和端口都一致,才会被浏览器认为是同域。
Unsafe URL。
- 无论是否发生协议降级,无论是本站链接还是站外链接,统统都发送 Referrer 信息。正如其名,这是最宽松而最不安全的策略。 No Referrer :
- 任何情况下都不发送 Referrer 信息。
Pragma
Pragma 是 HTTP 1.1 之前版本的历史遗留字段,仅作为与 HTTP 的向后兼容而定义。
Origin
用于指明当前请求来自于哪个站点。
Cache-Control
Cache-Control 指定了请求和响应遵循的缓存机制。其中 Request Header 的 Cache-Control 包含如方式:
-
no-cache
- 不要读取缓存中的文件,要求向服务器重新请求。 no-store
- 请求和响应都禁止被缓存。 max-age
- 表示当访问此网页后的 max-age 秒内再次访问不会去服务器请求,其功能与 Expires 类似。只是 Expires 是根据某个特定日期值做比较。一但缓存者自身的时间不准确.则结果可能就是错误的。而 max-age 没有这种问题,所以使用过程中尽量优先使用 max-age。 max-stale
- 允许读取过期时间必须小于 max-stale 值的缓存对象。 min-fresh
- 接受其 max-age 生命期大于其当前时间跟 min-fresh 值之和的缓存对象。 only-if-cached
- 告知缓存者,我希望内容来自缓存,我并不关心被缓存响应,是否是新鲜的。 no-transform
- 告知代理,不要更改媒体类型。
Connection
HTTP Connection 允许在请求处理结束之后将 TCP 连接保持在打开状态,以便为未来的HTTP 请求重用现存的连接。
-
keep-alive
- 开启 HTTP 持久连接,HTTP 1.1 默认值。 close
- 关闭 HTTP 持久连接,HTTP 1.0 默认值。 timeout
- 连接多久后关闭,关闭后,有请求,需要重新建立连接。
User-Agent
User-Agent 首部包含了一个特征字符串,用来让网络协议的对端来识别发起请求的用户代理软件的应用类型、操作系统、软件开发商、版本号。
空行(CRLF)
特别要注意:Request Head 后面必须有一个单独的空白行 CLRF (Carriage-Return Line-Feed回车换行\\r\\n),否则格式会非法,或被服务器认为不完整,等待CRLF发送过去。
请求体(message-body)
具体需要发送请求的 body 内容。
返回响应
服务器返回的响应报文,原理基本和请求时一致,包含状态行、响应头部、空行和响应包体,其中状态行包含响应协议、状态码、描述 4 个部分组成。
我们重点关注响应头和响应码 2 个部分:
响应头部(Response Header)
Content-Type
代表服务端返回的数据类型,格式跟请求头 Accept 基本支持格式一致,就不详细介绍了。
Content-Encoding
服务器发送的数据使用的压缩格式。
Content-Length
服务器发送的数据的大小(单位:字节)。
Content-Language
服务器发送的数据使用的自然语言。
Location
配合状态码为 3XX 时请求重定向。
Server
服务器的基本信息,如如服务器应用程序软件的名称、版本。
Last-Modified
被请求的当前资源最后修改时间
Cache-Control(重点)
-
public
- 数据内容皆被储存起来,就连有密码保护的网页也储存,安全性很低。 private
- 数据内容只能被储存到私有的cache,仅对某个用户有效,不能共享。 no-cache
- 可以缓存,但是只有跟服务器验证了其有效后,才能返回给客户端。 no-store
- 请求和响应都禁止被缓存。 max-age
- 本响应包含的对象的过期时间。 max-stale
- 允许读取过期时间必须小于 max-stale 值的缓存对象。 must-revalidate
- 如果缓存过期了,会再次和原来的服务器确定是否为最新数据。 proxy-revalidate
- 与 must-revalidate 类似,区别在于:proxy-revalidate 要排除掉用户代理的缓存的。即其规则并不应用于用户代理的本地缓存上。 s-maxage:
- 与 max-age 的唯一区别 是, s-maxage仅仅应用于共享缓存.而不应用于用户代理的本地缓存。 一版情况下 s-maxage 的优先级要高于 max-age。 no-transform
- 告知代理,不要更改媒体类型。
响应码(状态码)
响应码大全
响应码大全份上,当然,如果你懒得点,我也帮你罗列席常见的响应码。
| 状态码 | 原因短语 | 代表含义 | HTTP 版本 |
|---|---|---|---|
| 200 | OK (成功) | 请求成功 | HTTP/0.9 可用 |
| 301 | Moved Permanently(永久移动) | 该状态码表示所请求的 URI 资源路径已经改变,新的 URL 会在响应的Location:头字段里找到. | HTTP/0.9 可用 |
| 307 | Temporary Redirect(临时重定向) | 服务器发送该响应用来引导客户端使用相同的方法访问另外一个 URI 来获取想要获取的资源.新的 URL 会在响应的 Location :头字段里找到.与 302 状态码有相同的语义,且前后两次访问必须使用相同的方法 (GET POST). | HTTP/1.1 可用 |
| 404 | Not Found | (未找到) 服务器找不到所请求的资源.由于经常发生此种情况,所以该状态码在上网时是非常常见的. | HTTP/0.9 可用 |
| 500 | Internal Server Error | (内部服务器错误) 服务器遇到未知的无法解决的问题. | HTTP/0.9 可用 |
对拆分问题进行解答:
-
客户端是如何把一个 “http://jackwaiting.com” 转换成一个请求的,转换的标准是什么?
-
上面定义的报文就是我们我们 URL 转换成 Request 请求的标准,也称之为转换协议。
至于具体 http://jackwaiting.com 如何 转换成一个 报文,在 Android 中,okHttp 的拦截器做了工作,在 Request 请求发射之前, 对请求行,请求头(可选),空行,请求body(可选) 进行的纯代码拼接,本文主要疏通 HTTP 部分,okhttp 源码后续讲解。
一个转换后的标准是如何发送到服务器的?
- HTTP 在这个过程中其实什么都没做,仅仅只是提供了一个协议规范,保证我们的数据能正常的对接给 TCP,进行拆包传输。 服务器返回的响应是怎样的标准?
- 报文嘛(有没有发现解答越来越简单?) 响应标准怎样返回到客户端?
- 逆向思维嘛,你自己想。
总结一句话:
HTTP 定义的是一个客户端和服务器端通信的规范和标准,在整个网络通信中其实没有干具体的实事,只是让客户端与服务端之间沟通起来更加方便,省力,省带宽,就像是我们生活中的租房合同、购房合同,菜单 ^ . ^
以上是关于JackHttp -- 从原理来理解 HTTP的主要内容,如果未能解决你的问题,请参考以下文章