HashMap知识要点
Posted 那个天真的人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap知识要点相关的知识,希望对你有一定的参考价值。
序言
HashMap是java中非常实用的一种数据存储结构,它涉及到的知识点比较多,本篇主要对其要点进行一些总结。本文使用的jdk版本为1.8。
hashCode 和 equals
在Object类中,有 hashCode 和 equals 两个方法,这两个方法可以用于hash相关处理和对象的比较。查看源码,可以发现他们如下定义:
public native int hashCode();
public boolean equals(Object obj)
return (this == obj);
在java中,每个对象都可以有一个hashCode值,hashCode可以用于如HashMap这样的数据结构。equals用于两个对象的比较,默认实现为==比较。
这两个方法有如下一些规约:
1) 如果两个对象equals返回true,那么两个对象必须拥有相同的hashCode值
2) 如果两个对象的hashCode值相等,不代表他们执行equals也返回true
3) 如果两个对象equals返回false,此时对这两个对象的hashCode值无明确要求
HashMap基本结构
HashMap用于存储(key,value)这样的键值对,首先看下其内部存储结构,如下图所示:
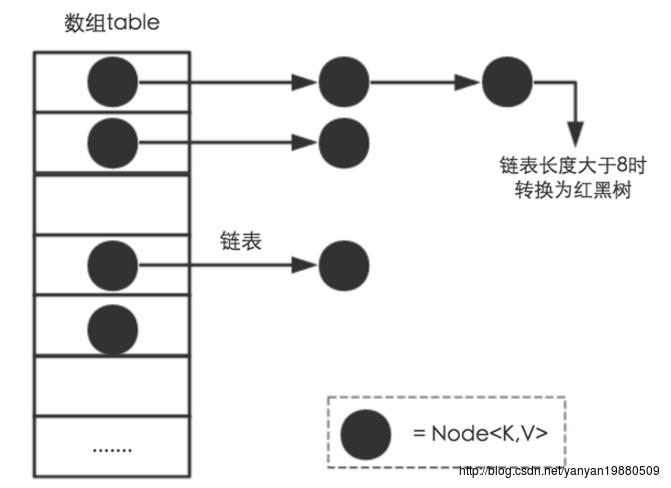
HashMap内部定义了一个 Node<K,V>[] table 变量,用于存储键值对(键值对使用Node进行封装),这里就会引出来一个问题,当我们put一个键值对的时候,是怎么确定它存储到table数组的哪个索引上的。
简单看下put方法的源码,如下:
public V put(K key, V value)
return putVal(hash(key), key, value, false, true);
static final int hash(Object key)
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict)
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 定位索引
tab[i] = newNode(hash, key, value, null);
...
首先,内部调用了hash(key)方法,计算我们传进去的key的hash值,而计算的方法如下所示:
(h = key.hashCode()) ^ (h >>> 16);
可能你会感到奇怪,为什么不是直接返回key.hashCode()?在这里,h>>>16表示把key的hash值右移16位,即得到其高16位值,然后再跟hash进行异或,这样做的目的是为了使得最终得出来的hash更加具有随机性。而最后计算数组索引的方式为:(n - 1) & hash,可以看到,hash值可能映射到数组中的任意一个索引上,相对随机公平。
由于多个对象有可能映射到同一个索引上,所以会出现碰撞的情况,也有人称为哈希冲突。当出现碰撞的时候,在jdk1.8之前,内部会把出现碰撞的Node节点串成一个链表,但有个问题就是如果冲突严重,这个链表可能会很长,影响到后面的查找。为了提高效率,HashMap内部定义了一个新变量:TREEIFY_THRESHOLD,当链表的长度大于这个阀值的时候,会调用treeifyBin方法把这个索引上的串转化为一棵红黑树,提升查找的效率。红黑树可以看成平衡二叉树的一种实现,可以保证树的高度均衡,不会出现一边倒的情况,当然,插入和删除元素的时候就会比较复杂了,但查询则会变快。
扩容
创建HashMap的时候,可以指定数组的初始大小和一个加载因子(loadFactor),默认初始大小为16,加载因子为0.75,当调用put方法的时候,如果size(键值对)>数组大小*加载因子,则会进行扩容,每次扩容都是成倍扩容,扩容的时候,要重新创建一个table数组,然后遍历旧数组中的每个索引,如果存储的值非空, 要对整条链(或者可能是一棵红黑树)每个节点进行重新hash定位。简单的伪算法如下:
for(int i=0; i<table.length; i++)
if(table[i] != null)
if(链表节点)
for(int j=0; j<size(链表); j++)
迁移节点(size[j])
else
// 迁移红黑树
可见如果HashMap数据量比较大的话,那么rehash一次成本还是比较高的,为了避免一直进行rehash,在创建HashMap的时候,我们通常指定一个比较合适的初始值。
成倍扩容的秘密
HashMap中有个构造方法如下:
public HashMap(int initialCapacity, float loadFactor)
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
当指定初始大小的时候,tableSizeFor会把初始大小调整为2的n次方,如initialCapacity=6,则
this.threshold=8,当第一次put的时候,这时候发现 threshold>0,则使用this.threshold创建table数组,所以table数组确保大小为2的n次方,这样的好处是 table.length-1 后再二进制化,就会得到如
00000….1111 这样的格式,而映射key到数组索引使用的正是: (n - 1) & hash,所以不管hash的值多大,都能够随机公平的进行映射。可以说这是一种把大数映射到小数范围的一种好方式。
值覆盖
我们都知道,当put了两个一样的key时,新的value值会覆盖旧的value值,那么HashMap是如何判断是同一个key的。查看putVal方法看到如下代码:
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))简单拆解就是:
1) 如果key1 == key2,则判断为同一个key
2) hash(key1)==hash(key2),并且 key1.equals(key2) == true,则判断为同一个key
此时的hash计算如下:
static final int hash(Object key)
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
HashMap支持key==null,hash(null)=0,所以key1==key2==null一样可以进行值覆盖。
迭代器
我们可以对HashMap中的所有key,或者value,甚至是键值对进行迭代,在迭代的过程中,需要注意的就是不可以随意添加删除HashMap中的内容,只可以通过Iterator的remove方法进行删除,举个简单的例子:
Map<String , Integer> map = new HashMap<String, Integer>();
map.put("a", 1);
map.put("b", 2);
map.put("c", 3);
map.put("d", 4);
Set<String> keySet = map.keySet();
Iterator<String> iterator = keySet.iterator();
while(iterator.hasNext())
String key = iterator.next();
map.remove(key);
代码执行的时候,会抛出:java.util.ConcurrentModificationException 这个异常,正确的删除方式如下所示:
Map<String , Integer> map = new HashMap<String, Integer>();
map.put("a", 1);
map.put("b", 2);
map.put("c", 3);
map.put("d", 4);
Set<String> keySet = map.keySet();
Iterator<String> iterator = keySet.iterator();
while(iterator.hasNext())
iterator.next(); // 此句代码不可少
iterator.remove(); //使用迭代器的方法进行安全删除
HashMap的内部维持了一个modCount变量,用于记录修改的次数,每次调用iterator时,都会创建一个HashIterator实例,同时记录HashMap当时的modCount值,在迭代的过程当中,如果发现HashIterator中的值与HashMaap中的modCount值不一致,则证明迭代过程HashMap结构被修改了,这时候则会抛出异常。
参考
https://zhuanlan.zhihu.com/p/21673805
以上是关于HashMap知识要点的主要内容,如果未能解决你的问题,请参考以下文章