信息,我找到了这些规律
Posted 没头发的米糊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了信息,我找到了这些规律相关的知识,希望对你有一定的参考价值。

中国专业IT社区CSDN创立于1999年,是目前中国最大、最受欢迎的开发者平台。作者对CSDN博客用户中排名前200位的33万多篇文章的基础信息数据进行分析,得出了一些有意思的结论,并绘制了一些图表。
目的与数据概况
通过分析CSDN排行榜中作者总榜前200名作者文章的基础信息,可以得到一系列有意思的结论,如当前最受欢迎的技术门类、如何写好技术类博客等。
本次数据样本共332491条文章数据,分别收集了这些文章的标题、撰写时间、链接、阅读量、收藏量、点赞量、评论量、标签以及文章长度。
统计结果
首先,给出本次分析出的所有规律与图表。
| 付费文章所占比例 | |
|
| 横轴为所有拥有付费专栏作者的编号,纵轴为付费文章占其所有文章数的比例。可以看出,拥有付费文章的作者数量并不多,但他们的付费文章比例呈均匀分布。 |
| 作者文章数目 | |
|
| 横轴为文章数量排名,纵轴为每个作者文章数目。可以看出除少数文章数目极大的作者外,其余作者文章数量都在5000篇以下。 |
| 数量 VS 质量 | |
|
| 横轴为文章数量,纵轴为对应的平均文章质量。可以看出质量在5000篇以上的作者,其平均文章质量都很低。在5000篇以下的作者,其文章质量相对较高,比较受到欢迎。 |
| 数量 VS 字数 | |
|
| 横轴为文章数量,纵轴为对应的平均文章字数。可以看出虽然数量与字数并没有数量与质量那么大的关联,但总体还是呈现数量越少、字数越多、内容越丰富的趋势。而发文数量很多的作者多半是在水文。 |
| 标签设置 | |
|
| 横轴为标签数,纵轴为文章数量。可以看出绝大多数文章并没有认真设置标签。标签是内容搜索、推送的重要依据,文章标签设置不到位会导致平台相关度推送精度下降,从而影响文章的阅读量。 |
| 标签数 VS 文章阅读数据 | |
|
| 横轴为标签数,纵轴为文章平均阅读数据。可以看出虽然没有明显关联,但存在标签数越多文章阅读数据越好的趋势。说明标签的确可以优化平台相关度推送。 |
| 十大热门标签 | |
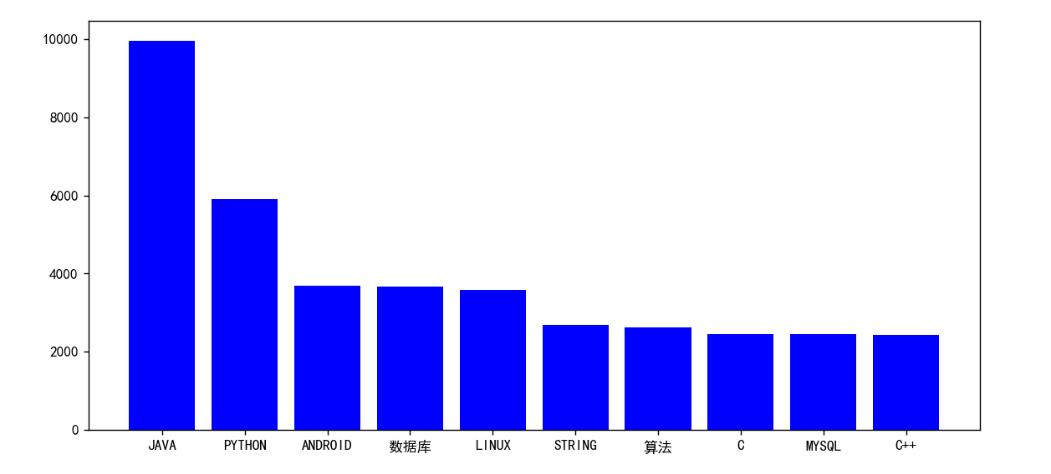
| 横轴为标签,纵轴为文章数。这个柱状图表示了当前最热门技术及其热度。
| |
| 标签词云 | |
|
| |



爬虫思路
首先进行数据的批量爬取。由于本次数据量较大,涉及环境较复杂,因此采用多线程、分批爬取的思路。
一.准备复用函数代码
首先准备一个复用函数get_data用于从指定链接获取数据。
def get_data(url):
head = "User-Agent": "Mozilla/5.0"
r = requests.get(url, headers=head)
r.encoding = r.apparent_encoding
return r |
通过这个函数,我们可以从指定的url获取数据,从而为下一步撰写爬虫代码减少工作量。
二.爬取前200名的作者信息

CSDN网站上提供了一个页面用于查看作者排行榜。
但值得注意的是,这个页面是动态页面,它做了下拉分页。也就是通过直接请求该页面拿不到任何数据,而且它最多显示100个。
因此我到浏览器的检查窗口中监视了页面的网络请求情况,找到了专门获取作者总榜的接口。地址如下:
https://blog.csdn.net/phoenix/web/blog/all-rank
通过这个地址后加query请求,就可以按分页拿到作者数据。经过实测该接口可以拿到前200名作者的基础数据。
page = 0
request = get_data("https://blog.csdn.net/phoenix/web/blog/all-rank?page=" + str(page) + "&pageSize=200")
rawData = json.loads(request.text)['data']['allRankListItem']
userData = []
articleData =
for item in rawData:
newItem = 'nickName': item['nickName'],
'hotRankScore': item['hotRankScore'],
'level': item['level'],
'fansCount': item['fansCount'],
'diggCount': item['diggCount'],
'vip': item['vip'],
'userName': item['userName']
userData.append(newItem)
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
with open('userInfo' + str(page) + '.json', 'w') as f:
f.write(json.dumps(userData, ensure_ascii=False)) |
后面的操作就简单了,通过如上代码即可将对我们有用的作者数据拿到手,并且写到json文件中。

在拿到所有作者数据后,接下来我们就开始爬取文章数据。

以第一名作者的主页为例,我们可以看到整个主页包含了他的所有博客。经过反复测验,可以发现除了第一页其他分页全部采用url进行:
因此可以直接使用requests库请求整页数据,然后用bs4解析。
def get_user_articles(user):
index = 0
articles = []
print("作者:" + user['nickName'])
while True:
index = index + 1
html_raw_data = get_data("https://blog.csdn.net/" + user['userName'] + "/article/list/" + str(index))
soup = BeautifulSoup(html_raw_data.text, 'html.parser')
soup = soup.select(".article-list")
if len(soup) > 0:
article_index = 0
soup = soup[0].select("div.article-item-box")
for article in soup:
article_index = article_index + 1
print(user['nickName'] + ":" + str(index) + "/" + str(article_index))
articleDict = 'title': article.select("h4 a")[0].text[3:].strip(),
'time': article.select(".info-box")[0].select(".date")[0].text.strip(),
'link': article.select("h4 a")[0]['href'], "bad": True
articleDict['info'] = get_article_info((articleDict['link']))
articleDict["bad"] = False
articles.append(articleDict)
else:
break
with open(user['userName'] + '.json', 'w', encoding="utf-8") as f:
f.write(json.dumps(articles, ensure_ascii=False)) |
因此可以写出如上函数。该函数可以通过给定作者的userName获取它的全部文章信息,同时还会进一步点进每个文章,获取到文章的内容和详细信息。获取文章详细信息的函数如下:
def get_article_info(url):
article_info =
raw_data = get_data(url)
soup = BeautifulSoup(raw_data.text, 'html.parser')
readCount = soup.select(".bar-content")[0].select(".read-count")
if len(readCount) > 0:
article_info['read-count'] = int(soup.select(".bar-content")[0].select(".read-count")[0].text.strip())
else:
article_info['read-count'] = 0
article_info['get-collection'] = int(
soup.select(".toolbox-list")[0].select("#get-collection")[0].text.strip())
article_info['likes'] = int(
soup.select(".toolbox-list")[0].select("#is-like")[0].select("#spanCount")[0].text.strip())
article_info['comments'] = int(
soup.select(".toolbox-list")[0].select(".tool-item-comment")[0].select(".count")[0].text.strip())
tag_box = soup.select(".tags-box")[0].select(".label:nth-of-type(2) ~ .tag-link")
tag_box = [item.text.strip() for item in tag_box]
article_info['tags'] = tag_box
if len(soup.select(".column-mask")) > 0:
article_info['type'] = 'NonFree'
return article_info
else:
article_info['type'] = 'Free'
article_info['length'] = len(soup.select("#article_content")[0].text)
return article_info |
通过上面一系列操作,就可以顺利地拿到一个作者所有文章的信息。
写完这些函数后,我们开始编写主要的多线程爬取代码:
userIndex = 10
while True:
user = userData[userIndex]
length = len(threading.enumerate())
if userIndex < len(userData) and length <= 10:
userIndex = userIndex + 1
try:
threading.Thread(target=get_user_articles, name=user['nickName'], args=(user, )).start()
except Exception:
print(user['nickName'] + "异常中断")
pass |
使用如上图所示的多线程程序可以保证每时每刻都有10个作者的信息正在被爬取。经过测试,线程数继续增加就可能会被CSDN拒绝连接,因此10个并发是极限值。
最后,我们得到了一系列的json文件,这些文件记录了每个作者的所有文章基础信息。
统计思路
一.数据导入
首先,将爬到的数据统一放置在一个文件夹中:
放在同一个文件夹中的目的是,方便后续使用Python将这些数据通过I/O流导入到字典中进行分析。
同时考虑到具体到个人的文章数据可能存在隐私问题和个例问题,因此在导入数据时,干脆直接去除对应性,将每个作者看作等同的个体,分析他们的数据分布特征而非个体的具体特征。
| for root, dirs, files in os.walk("G:\\Python大数据分析课程大作业\\data"): |
通过如上所示的代码即可完成这一步的操作。这时,我们顺利统计出了所有文章的条数,并且将所有文章按作者分类放入了articleData中。
二.数据分析
在爬虫过程中一共遇到如下两种可能存在的问题:
- 爬到的数据存在问题,做上了bad标记
- 爬到的文章属于付费专栏文章,无法查看到具体内容
对于这两种和其他数据存在明显差异的数据,需要提前进行特殊对待处理。
首先针对付费专栏文章进行处理:
nonFreeWriters = []
for writer in articleData:
articles = []
for article in writer:
if article["info"]["type"] != "Free":
nonFreeWriters.append(writer)
break
print(len(nonFreeWriters)) noneFreeRatios = []
for writer in nonFreeWriters:
nonFreeArticles = []
for article in writer:
if article["info"]["type"] != "Free":
nonFreeArticles.append(article)
noneFreeRatios.append(len(nonFreeArticles) / len(writer))
noneFreeRatios.sort(reverse=True)
plt.bar(range(len(noneFreeRatios)), noneFreeRatios)
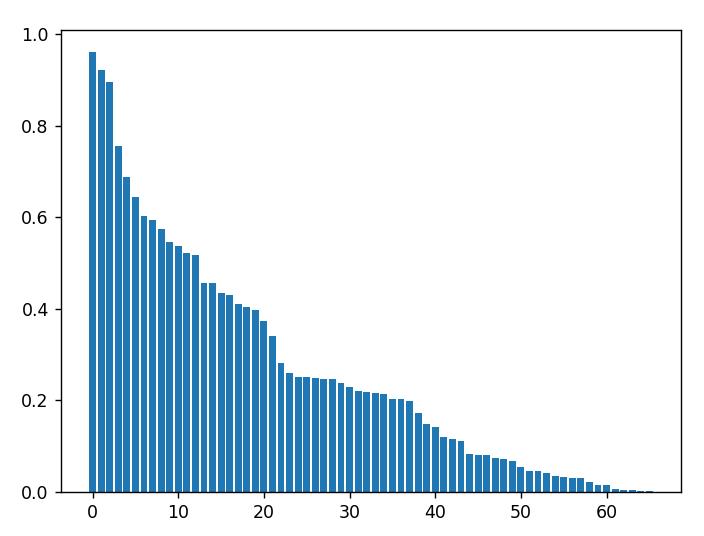
plt.show() ------------------------------------------------------------------------- >> 66 |

通过以上统计,我们可以了解到在200名作者中,仅有66名作者拥有付费文章。我们顺带将他们的付费文章数占其总文章数的比例也统计出来,绘制成柱状图,结果如下:
可以看到,比例基本服从均匀分布。付费文章较少的作者可能只有一两篇付费文章,而付费文章较多的作者这一比例数值可以达到90%以上。
在分析完付费专栏文章后,开始详细分析非付费文章:
首先我想要统计出所有作者非付费文章的数量及分布情况。
#找出所有非付费文章
freeArticleData = []
for writer in articleData:
articles = []
for article in writer:
if article["bad"] is False and article["info"]["type"] == "Free":
articles.append(article)
freeArticleData.append(articles)
writerArticleCounts = []
for articles in freeArticleData:
writerArticleCounts.append(len(articles))
writerArticleCounts.sort(reverse=True)
print(writerArticleCounts)
plt.bar(range(len(writerArticleCounts)), writerArticleCounts)
plt.show() |

通过导出的图表,我们可以看到除了个别文章数量非常多的作者外,其余作者的文章数量基本分布在0到5000篇之间。文章最少的作者仅有67篇,而文章最多的作者拥有10523篇文章。
既然这些作者的文章数量如此参错不齐,而他们都能登上作者排行榜,那么他们的文章质量应该也会有很大的差异。于是我们从不同维度来评价这些文章的质量:
可以认为一篇文章的质量由阅读量、点赞量、收藏量、评论量来反馈。因此,给出下列公式:
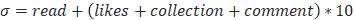
该公式用于评估一篇文章的质量,点赞、收藏和评论属于更高级别的质量体现量,因此在这里乘上系数10。该公式得出的值越大则说明文章越受欢迎、质量越高。
freeArticleDataMark = []
for i in range(len(freeArticleData)):
count = len(freeArticleData[i])
averageMark = 0
for article in freeArticleData[i]:
averageMark = averageMark + article["info"]["read-count"] + article["info"]["get-collection"] * 10 + article["info"]["likes"] * 10 + article["info"]["comments"] * 10
freeArticleDataMark.append(averageMark / count)
freeArticleDataAnalysis = zip(writerArticleCounts, freeArticleDataMark)
freeArticleDataAnalysis = sorted(freeArticleDataAnalysis, key=lambda x: x[0], reverse=True)
writerArticleCounts_sorted = [item[0] for item in freeArticleDataAnalysis]
freeArticleDataMark_sorted = [item[1] for item in freeArticleDataAnalysis]
plt.scatter(writerArticleCounts_sorted, freeArticleDataMark_sorted)
plt.show() |
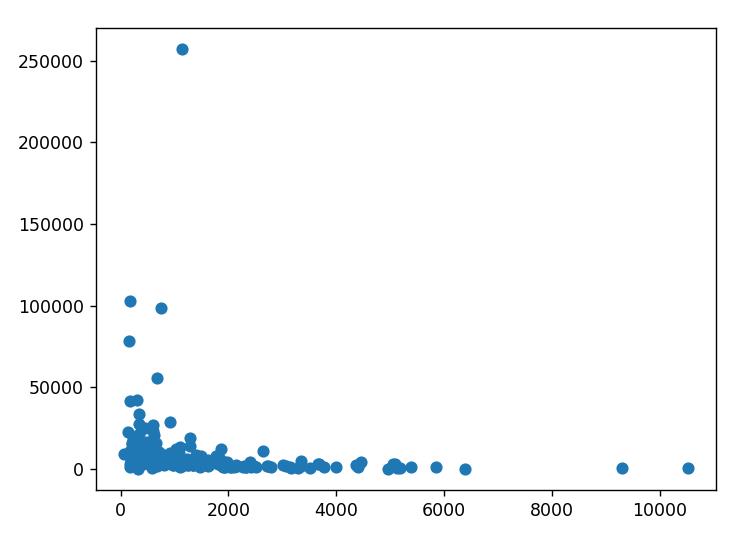
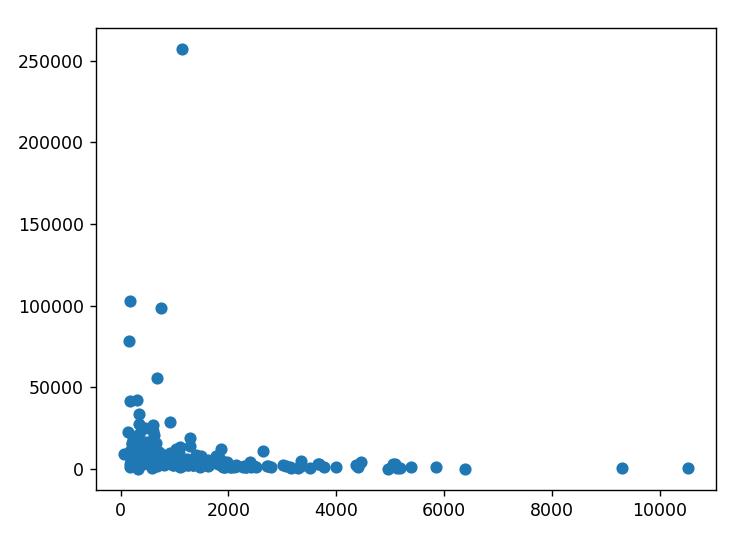
通过上述代码进行分析,我们将每个作者文章的平均质量求出,然后通过散点图绘制分布情况:
横轴为作者的文章数量,纵轴为作者文章的平均质量。可以看出,在文章数量较大(>3000)的情况下,其文章质量往往偏低。在文章数量较小时,文章质量往往都有一定提升。一天水一篇没有人看的文章,还是每周精耕一篇能使很多人收益的文章,这体现了一位作者是否对技术负责任的态度。
同样地,我们也可以对文章数量和文章平均长度的关系做类似的分析:
freeArticleDataLength = []
for i in range(len(freeArticleData)):
count = len(freeArticleData[i])
length = 0
for article in freeArticleData[i]:
length = length + article["info"]["length"]
freeArticleDataLength.append(length / count)
freeArticleDataAnalysis = zip(writerArticleCounts, freeArticleDataLength)
freeArticleDataAnalysis = sorted(freeArticleDataAnalysis, key=lambda x: x[0], reverse=True)
writerArticleCounts_sorted = [item[0] for item in freeArticleDataAnalysis]
freeArticleDataLength_sorted = [item[1] for item in freeArticleDataAnalysis]
plt.scatter(writerArticleCounts_sorted, freeArticleDataLength_sorted)
plt.show() |
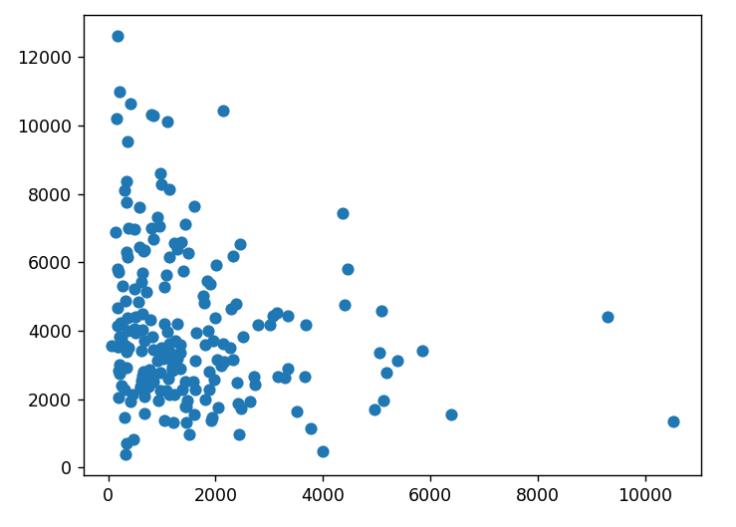
横轴为作者的文章数量,纵轴为作者文章的平均长度。可以看到,这两者的关系并不如刚才的那对关系紧密,但总的来说,还是呈现出文章越少,文章长度越长的趋势。
CSDN的博客包含一套标签系统,作者在上传文章时可以选择文章对应的标签。这些标签可以优化文章的搜索与推送,因此建议每个作者都仔细为文章配置标签。现在我们开始探究标签与文章质量表现的关系。
首先对CSDN博客文章标签数量进行统计:
freeArticleDataDict = dict()
for i in range(len(freeArticleData)):
for article in freeArticleData[i]:
freeArticleDataDict[len(article["info"]["tags"])] = freeArticleDataDict.get(len(article["info"]["tags"]), 0) + 1
freeArticleData = freeArticleDataDict.items()
freeArticleData = sorted(freeArticleData, key=lambda x: x[0],reverse=True)
ls1 = [item[0] for item in freeArticleData]
ls2 = [item[1] for item in freeArticleData]
plt.bar(ls1, ls2, fc='g')
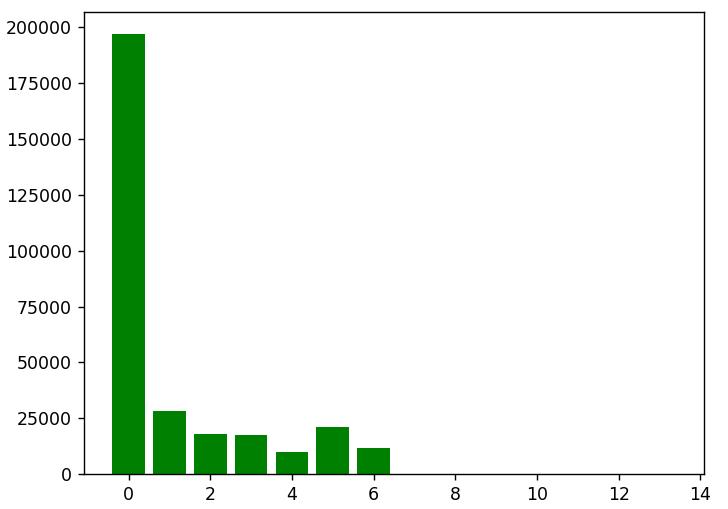
plt.show() |

横坐标为标签数量,纵坐标为对应的文章数量。可以看出,这些博客文章中绝大部分都缺少标签,仅有极少部分的文章合理地设置了标签。
接下来,探讨标签数量与文章反馈的质量数据的关系:
freeArticleDataMark = []
freeArticleTagsNum = []
for i in range(len(freeArticleData)):
averageMark = 0
for article in freeArticleData[i]:
averageMark = averageMark + article["info"]["read-count"] + article["info"]["get-collection"] * 10 + article["info"]["likes"] * 10 + article["info"]["comments"] * 10
freeArticleDataMark.append(averageMark)
freeArticleTagsNum.append(len(article["info"]["tags"]))
freeArticleDataAnalysis = zip(freeArticleTagsNum, freeArticleDataMark)
freeArticleDataDict = dict()
for item in range(14):
freeArticleDataDict[item] = []
for item in freeArticleDataAnalysis:
freeArticleDataDict[item[0]].append(item[1])
for item in freeArticleDataDict.keys():
freeArticleDataDict[item] = sum(freeArticleDataDict[item]) / len(freeArticleDataDict[item])
ls1 = [item for item in freeArticleDataDict.keys()]
ls2 = [item for item in freeArticleDataDict.values()]
plt.bar(ls1, ls2, fc='g')
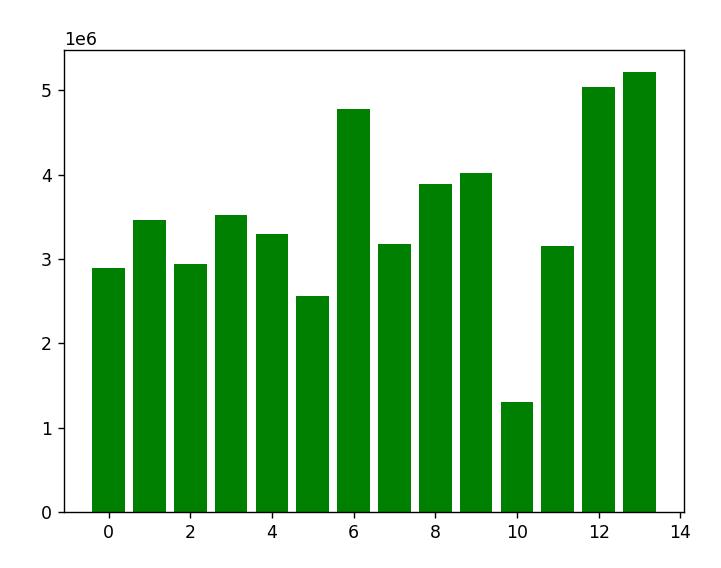
plt.show() |
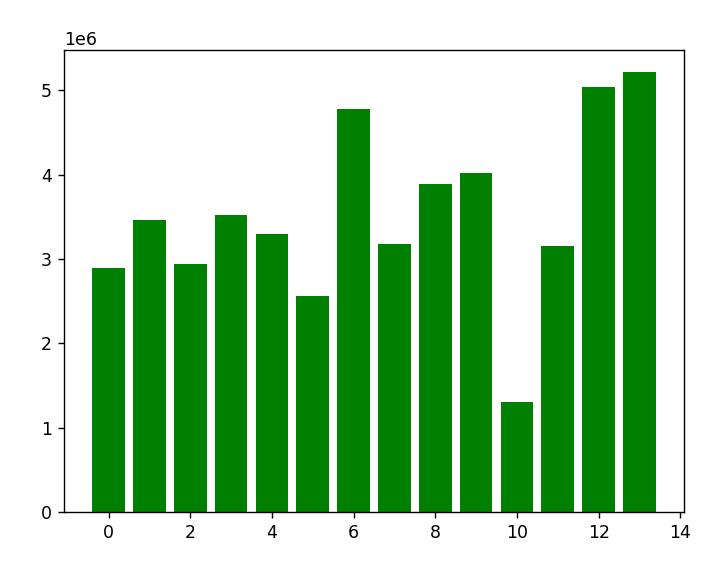
横坐标为文章标签数量,纵坐标为对应的平均文章质量数据,可以看到,随着标签数量增加,文章质量数据有明显的上升趋势。标签设置在6个左右可以得到最平衡的收益,而设置了很多标签的文章一般也是作者花了大心思打造的文章,也拥有相当高的质量数据。
最后,我们对标签的内容进行分析。
首先调出最火的十个标签:
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
freeArticleTags = dict()
for i in range(len(freeArticleData)):
for article in freeArticleData[i]:
for tag in article["info"]["tags"]:
tag = tag.upper()
freeArticleTags[tag] = freeArticleTags.get(tag, 0) + 1
freeArticleTags = freeArticleTags.items()
freeArticleTags = sorted(freeArticleTags, key=lambda x: x[1], reverse=True)
ls1 = [item[0] for item in freeArticleTags[:10]]
ls2 = [item[1] for item in freeArticleTags[:10]]
plt.bar(ls1, ls2, fc='b')
plt.show() |

以上是所统计的博客文章中使用最多的十个标签和它们的热度统计。可以看到排在前十位的分别是Java、Python、android、数据库、Linux、String、算法、C、mysql、C++。只涉及到当下主流的后端技术和客户端开发技术,这一定程度上体现了后端技术在目前依然具有不可抵挡的热度,一定程度上也与当下前端人才的稀缺问题呼应。
最后,对前1000个标签进行词云统计。
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
freeArticleTags = dict()
for i in range(len(freeArticleData)):
for article in freeArticleData[i]:
for tag in article["info"]["tags"]:
tag = tag.upper()
freeArticleTags[tag] = freeArticleTags.get(tag, 0) + 1
freeArticleTags = freeArticleTags.items()
freeArticleTags = sorted(freeArticleTags, key=lambda x: x[1], reverse=True)
ls1 = [item[0] for item in freeArticleTags[:10]]
ls2 = [item[1] for item in freeArticleTags[:10]]
plt.bar(ls1, ls2, fc='b')
plt.show() |

以上是词云统计的结果。在这张图里,可以看到截至2021年12月CSDN上前200名博客作者的技术分布。在这张图中可以看到主流的编程语言、操作系统、应用技术、开发术语,它代表着当下最新最热的技术集群,任何一门技术都值得被尊重。
后记
经过这次分析,我们得到了很多有关技术博客的结论。技术型博客秉承互联网开放、包容的原则,为所有想要学习技术、获取解决方案的人提供最直接、最有效的前人经验,是亿万开发者共同的精神财富。
通过分析这些优秀博客创作者的博客数据,可以发现卓越的质量永远是标志博客受欢迎程度的重要考量。巨大的水文数量也许会换来短暂的排名数字,但迟早会被人们所遗忘。
同时,在知识付费的当下,也出现了少量付费文章。它们倾注了作者大量的精力,或许不能被所有人共享,但也至少应该被尊重。
愿互联网继续保持开放、自由、共享的精神,愿我们的世界越来越好。
最后非常感谢合肥工业大学冷金麟老师开设的《Python玩转大数据》公选课,通过学习这门课,我也掌握了更多与Python相关的知识,为本次分析提供了技术支持。
以上是关于信息,我找到了这些规律的主要内容,如果未能解决你的问题,请参考以下文章