数据生成文本文献阅读笔记01
Posted 云才哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据生成文本文献阅读笔记01相关的知识,希望对你有一定的参考价值。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
数据生成文本
- Data-to-Text Generation with Content Selection and Planning
- 一、摘要(abstract)
- 二、引言(Introduction)
- 三、相关工作(Related Work)
- 四、问题阐述(Problem Formulation)
- 总结
Data-to-Text Generation with Content Selection and Planning
论文发表于2019年。
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
一、摘要(abstract)
摘要中提到由于大数据集和端到端神经网络的使用,data-to-text generation取得了很大的进步。但现有神经网络模型并没有在建模过程中明确生成的文本需要阐述什么内容以及应该以何种顺序来组织文本。
数据集类型:paired with descriptive documents(数据表与描述性文本对)
具体使用数据集合:ROTOWIRE dataset
介绍了他们的神经网络架构将整个任务分为两个工作:1、选择内容。2、组织排序。
这种神经网络架构包含了内容选择和规划,而不牺牲端到端训练。
二、引言(Introduction)
1.介绍Data-to-text generation
数据到文本生成广泛是指从非语言输入自动生成文本的任务。输入可以是各种形式的,包括记录数据库、电子表格、专家系统知识库、物理系统的模拟等。表1显示了包含NBA篮球比赛统计数据的数据库示例,以及相应的比赛摘要:

2、文本生成方法研究
传统方法:传统的data-to-text generation解决方案于1983开始,没有使用神经网络,而是直接基于内容选择和规划。(从data中选择特定的内容)在规划上直接确定句子的结构和词汇内容。
基于深度学习方法:最新基于深度学习的文本生成方法于2015年开始,区别于传统方法,不要明确地建模任何这些阶段,而是使用非常成功的编码器-解码器架构进行端到端方式的训练。
基于深度学习方法的缺陷:基于神经网络生成的文本在内容选择方面表现不佳,很难去维持句子间的一致性或者说内容的排序。其他的挑战包括避免冗余(内容重复)和忠实于输入(未登录词的处理,输出内容的真实性)。
3.文本生成方法创新
针对已有深度学习方法的缺陷,本文提出的创新方法将传统方法思想和深度学习方法相结合。即在深度学习建模时加入内容选择和规划来融入传统方法思想。
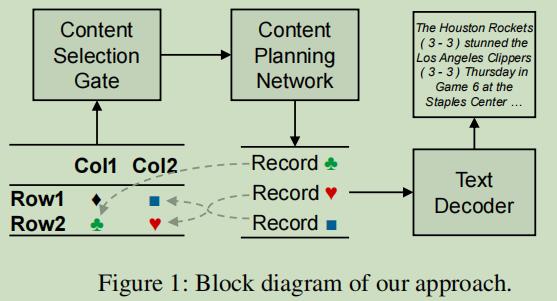
创新好处:
- 使解码器能够更加专注于句子规划和表面实现的任务
- 通过生成中间表示,它使数据到文档的生成过程更可解释
- 通过内容规划,介绍了生成文本的冗余(内容重复)并提高了准确度(真实性)
三、相关工作(Related Work)
早期工作:基于规则约束的内容选择和行文排序。
最近工作:基于端到端的神经网络模型训练生成文本。大多数类似于天气预报,NBA比赛概要均是考虑生成短文本或是一句话。而且目前的模型,没有发现其中包含了内容选择和规划机制,并生成了多句文档。
本文工作:类似于神经网络模型,利用数据和与之相对应的文本学习出一个文本生成器。
四、问题阐述(Problem Formulation)
1.输入和输出:
输入:表格(table)
输出:文本(document)
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
以上是关于数据生成文本文献阅读笔记01的主要内容,如果未能解决你的问题,请参考以下文章