吃透Redis:数据结构篇-全局Hash表
Posted 吃透Java
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吃透Redis:数据结构篇-全局Hash表相关的知识,希望对你有一定的参考价值。
文章目录
全局Hash表
为了实现从键到值的快速访问,Redis 使用了一个哈希表来保存所有键值对。

Hash 表应用如此广泛的一个重要原因,就是从理论上来说,它能以 O(1) 的复杂度快速查询数据。Hash 表通过 Hash 函数的计算,就能定位数据在表中的位置,紧接着可以对数据进行操作,这就使得数据操作非常快速。
那么我们该如何解决哈希冲突呢?可以考虑使用以下两种解决方案:
- 第一种方案,就是我接下来要给你介绍的链式哈希。这里你需要先知道,链式哈希的链不能太长,否则会降低 Hash 表性能。
- 第二种方案,就是当链式哈希的链长达到一定长度时,我们可以使用 rehash。不过,执行 rehash 本身开销比较大,所以就需要采用我稍后会给你介绍的渐进式 rehash 设计。
链式Hash
typedef struct dictEntry
void *key;
union
void *val;
uint64_t u64;
int64_t s64;
double d;
v;
struct dictEntry *next;
dictEntry;
那么为了实现链式哈希, Redis 在每个 dictEntry 的结构设计中,除了包含指向键和值的指针,还包含了指向下一个哈希项的指针。如下面的代码所示,*dictEntry 结构体中包含了指向另一个 dictEntry 结构的指针 next,这就是用来实现链式哈希的。
在 dictEntry 结构体中,键值对的值是由一个联合体 v 定义的。这个联合体 v 中包含了指向实际值的指针 *val,还包含了无符号的 64 位整数、有符号的 64 位整数,以及 double 类的值。
因为当值为整数或双精度浮点数时,由于其本身就是 64 位,就可以不用指针指向了,而是可以直接存在键值对的结构体中,这样就避免了再用一个指针,从而节省了内存空间。
如果不是整数或双精度浮点数时,*val 指针会指向 RedisObject。
RedisObject
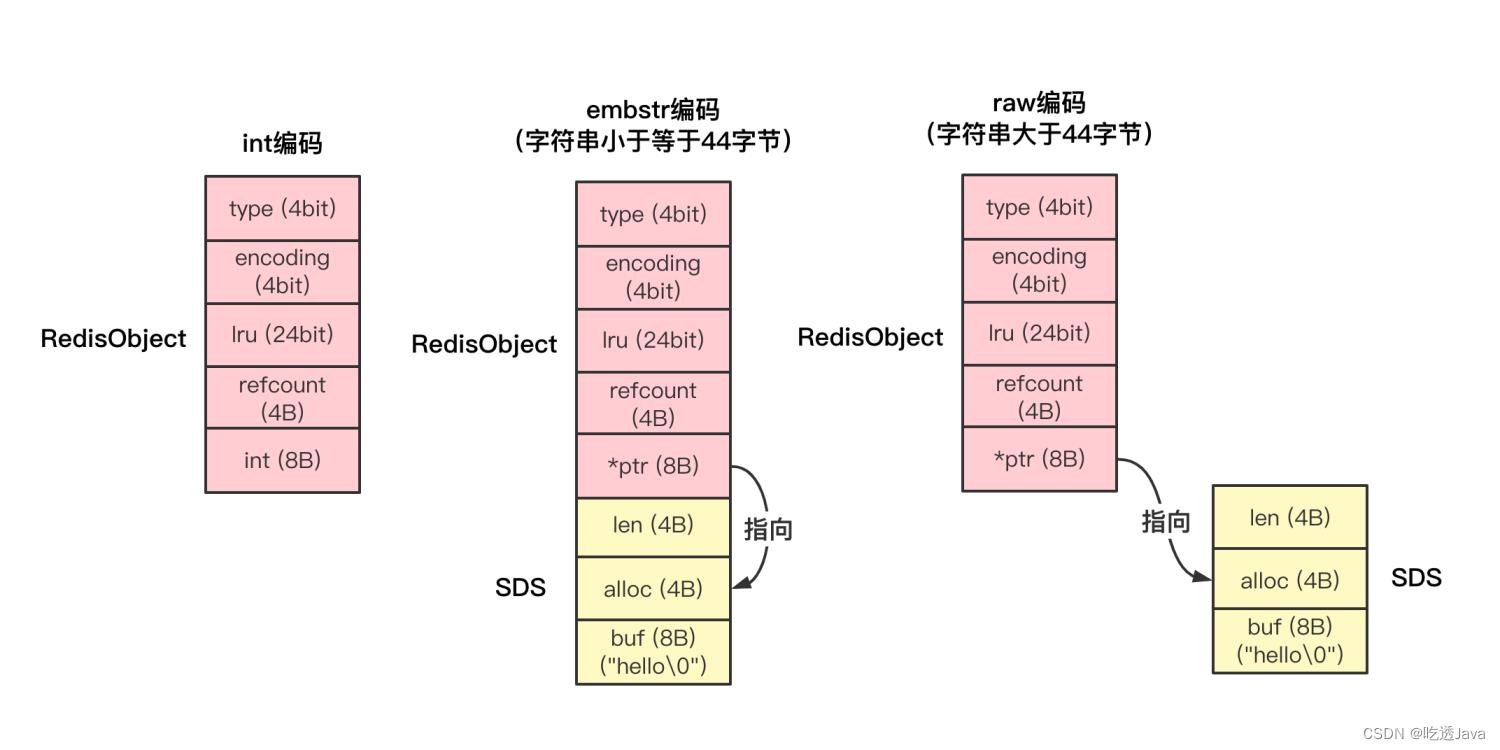
因为,Redis 的 key 是 String 类型,但 value 可以是很多类型(String/List/Hash/Set/ZSet等),所以 Redis 要想存储多种数据类型,就要设计一个通用的对象进行封装,这个对象就是 redisObject。结构体定义如下:
typedef struct redisObject
unsigned type:4; //redisObject的数据类型,4个bits
unsigned encoding:4; //redisObject的编码类型,4个bits
unsigned lru:LRU_BITS; //redisObject的LRU时间,LRU_BITS为24个bits
int refcount; //redisObject的引用计数,4个字节
void *ptr; //指向值的指针,8个字节
robj;
结构一共定义了 4 个元数据和一个指针:
- type:redisObject 的数据类型,面向用户的数据类型(String/List/Hash/Set/ZSet等)。占用 4 bit
- encoding:redisObject 的编码类型,是 Redis 内部实现各种数据类型所用的数据结构,每一种数据类型,可以对应不同的底层数据结构来实现(SDS/ziplist/intset/hashtable/skiplist等)。占用4bit
- lru:redisObject 的 LRU 时间。占用24bit
- refcount:redisObject 的引用计数。占用4个字节
- ptr:指向值的指针。占用8个字节
一方面,当保存的是 Long 类型整数时,RedisObject 中的指针就直接赋值为整数数据了,这样就不用额外的指针再指向整数了,节省了指针的空间开销。
另一方面,当保存的是字符串数据,并且字符串小于等于 44 字节时,RedisObject 中的元数据、指针和 SDS 是一块连续的内存区域,这样就可以避免内存碎片。这种布局方式也被称为 embstr 编码方式。
当然,当字符串大于 44 字节时,SDS 的数据量就开始变多了,Redis 就不再把 SDS 和 RedisObject 布局在一起了,而是会给 SDS 分配独立的空间,并用指针指向 SDS 结构。这种布局方式被称为 raw 编码模式。
关于 String 类型的实现,底层对应 3 种数据结构:
- long:整数存储(小于 10000,使用共享对象池存储,但有个前提:Redis 没有设置淘汰策略,详见 object.c 的 tryObjectEncoding 函数)
- rawstr:大于 44 字节,redisObject 和 SDS 分开存储,需分配 2 次内存
- embstr:小于 44 字节,嵌入式存储,redisObject 和 SDS 一起分配内存,只分配 1 次内存
SDS 判断是否使用嵌入式字符串的条件是 44 字节?
44是因为 N = 64 - 16(redisObject) - 3(sdshr8) - 1(\\0), N = 44 字节。那么为什么是64减呢,为什么不是别的,因为在目前的x86体系下,一般的缓存行大小是64字节,redis为了一次能加载完成,因此采用64自己作为embstr类型(保存redisObject)的最大长度。
rehash
Redis 又在 dict.h 文件中,定义了一个 dict 结构体。这个结构体中有一个数组(ht[2]),包含了两个 Hash 表 ht[0]和 ht[1]。dict 结构体的代码定义如下所示:
typedef struct dict
…
dictht ht[2]; //两个Hash表,交替使用,用于rehash操作
long rehashidx; //Hash表是否在进行rehash的标识,-1表示没有进行rehash
…
dict;
- 首先,Redis 准备了两个哈希表,用于 rehash 时交替保存数据。
- 其次,在正常服务请求阶段,所有的键值对写入哈希表 ht[0]。
- 接着,当进行 rehash 时,键值对被迁移到哈希表 ht[1]中。
- 最后,当迁移完成后,ht[0]的空间会被释放,并把 ht[1]的地址赋值给 ht[0],ht[1]的表大小设置为 0。这样一来,又回到了正常服务请求的阶段,ht[0]接收和服务请求,ht[1]作为下一次 rehash 时的迁移表。
1、触发 rehash 的条件?
负载因子:Hash 表当前承载的元素个数 / Hash 表当前设定的大小。
dict 在负载因子超过 1 时(used: bucket size >= 1),会触发 rehash。但如果 Redis 正在 RDB 或 AOF rewrite,为避免父进程大量写时复制,会暂时关闭触发 rehash。但这里有个例外,如果负载因子超过了 5(哈希冲突已非常严重),依旧会强制做 rehash(重点)
2、触发 rehash 的时候?
当我们往 Redis 中写入新的键值对或是修改键值对时,Redis 都会判断下是否需要进行 rehash
3、rehash 扩容扩多大?
如果当前表的已用空间大小为 size,那么就将表扩容到 size*2 的大小。
4、渐进式 rehash 的实现?
所谓「渐进式 rehash」是指,把很大块迁移数据的开销,平摊到多次小的操作中,目的是降低主线程的性能影响「全局哈希表」在触发渐进式 rehash 的情况有 2 个:
- 增删改查哈希表时:每次迁移 1 个哈希桶
- 定时 rehash:如果 dict 一直没有操作,无法渐进式迁移数据,那主线程会默认每间隔 100ms 执行一次迁移操作。这里一次会以 100 个桶为基本单位迁移数据,并限制如果一次操作耗时超时 1ms 就结束本次任务,待下次再次触发迁移
注意:定时 rehash 只会迁移全局哈希表中的数据,不会定时迁移 Hash/Set/Sorted Set 下的哈希表的数据,这些哈希表只会在操作数据时做实时的渐进式 rehash
总结
- Redis 中的 dict 数据结构,采用「链式哈希」的方式存储,当哈希冲突严重时,会开辟一个新的哈希表,翻倍扩容,并采用「渐进式 rehash」的方式迁移数据
- 所谓「渐进式 rehash」是指,把很大块迁移数据的开销,平摊到多次小的操作中,目的是降低主线程的性能影响。
- Redis 中凡是需要 O(1) 时间获取 k-v 数据的场景,都使用了 dict 这个数据结构,也就是说 dict 是 Redis 中重中之重的「底层数据结构」
- dict 封装好了友好的「增删改查」API,并在适当时机「自动扩容、缩容」,这给上层数据类型(Hash/Set/Sorted Set)、全局哈希表的实现提供了非常大的便利
- 全局哈希表」在触发渐进式 rehash 的情况有 2 个: - 增删改查哈希表时:每次迁移 1 个哈希桶(文章提到的 dict.c 中的 _dictRehashStep 函数) - 定时 rehash:如果 dict 一直没有操作,无法渐进式迁移数据,那主线程会默认每间隔 100ms 执行一次迁移操作。这里一次会以 100 个桶为基本单位迁移数据,并限制如果一次操作耗时超时 1ms 就结束本次任务,待下次再次触发迁移(文章没提到这个,详见 dict.c 的 dictRehashMilliseconds 函数) (注意:定时 rehash 只会迁移全局哈希表中的数据,不会定时迁移 Hash/Set/Sorted Set 下的哈希表的数据,这些哈希表只会在操作数据时做实时的渐进式 rehash)
- dict 在负载因子超过 1 时(used: bucket size >= 1),会触发 rehash。但如果 Redis 正在 RDB 或 AOF rewrite,为避免父进程大量写时复制,会暂时关闭触发 rehash。但这里有个例外,如果负载因子超过了 5(哈希冲突已非常严重),依旧会强制做 rehash(重点)
- dict 在 rehash 期间,查询旧哈希表找不到结果,还需要在新哈希表查询一次
以上是关于吃透Redis:数据结构篇-全局Hash表的主要内容,如果未能解决你的问题,请参考以下文章