python实现搜狗微信公众号数据爬取
Posted robot_sql
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python实现搜狗微信公众号数据爬取相关的知识,希望对你有一定的参考价值。
一、环境准备
Python版本:3.5
编辑器:Pycharm
数据库:mysql
二、python代码
目前该代码只是一个实现思路,由于搜狗验证码的问题,导致爬取的时候可能IP会被限制,一种思路是使用代理IP来避免验证码的问题,一种就是识别验证码(实现起来有难度),这份代码是将文章爬取下来以html格式存储在本地,如果你需要解析到数据库只需要解析本地的HTML文件即可,这一步比较简单,没做了,由于搜狗的网址结构有可能变动,所以有时候需要重新调整正则表达式。
下面是整个爬取的代码:
#!/usr/bin/env python
# coding=utf-8
import time
import os
import requests
import re
import urllib
from urllib import request
from lxml import etree
from bs4 import BeautifulSoup
import pymysql as mdb
import logging
import hashlib
class weichat_spider:
def __init__(self, ):
self.check = True
self.htmlPath = 'E:/A_crawling/data/raw/htmlPath/weichat/'
self.PicPath = 'E:/A_crawling/data/raw/htmlPath/weichat/'
self.headers = None
self.search_url = None
self.sublist = None
self.config = None
self.conn = None
# 从数据库查询公众号列表
def getSubList(self):
self.config = 'host': 'xxx.xxx.x.xx', 'port': 3306, 'user': 'root', 'passwd': '*****', 'db': '****', 'charset': 'utf8'
self.conn = mdb.connect(**self.config)
cursor = self.conn.cursor()
try:
sql = "select subEname,subName from subscription where status= 1 "
cursor.execute(sql)
temp = cursor.fetchall()
self.conn.commit()
return temp
except Exception as e:
logging.error(e)
self.conn.rollback()
finally:
cursor.close()
self.conn.close()
# 转换成哈希值
@staticmethod
def toHash(x):
m = hashlib.md5()
m.update(x.encode('utf-8'))
return m.hexdigest()
# 运行程序
def run(self):
self.sublist = self.getSubList()
for self.ename, self.name in self.sublist:
self.search_url = "http://weixin.sogou.com/weixin?type=1&s_from=input&query=%s&ie=utf8&_sug_=y&_sug_type_=" % self.name
self.headers = "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0", "Referer": self.search_url
print('开始抓取公众号[' + self.name + ']' + time.strftime('%Y-%m-%d') + '的文章' + ':')
self.get_list(self.search_url, self.ename)
# 获取被爬取公众号的url连接,并且将url传入爬取的函数
def get_list(self, search_url, ename):
# html = requests.get(search_url, headers=self.headers, verify=False).content
weichat_id = ename
html_catalog = requests.get(search_url, verify=False).text
selector = etree.HTML(html_catalog.encode("UTF-8"))
content = selector.xpath('/html/body/div[2]/div/div[4]/ul/li[1]/div/div[2]/p[1]/a')
for list_catalog in content:
list_catalog = list_catalog.attrib.get('href')
self.get_content(list_catalog, weichat_id)
# 获得公众号中文章的详情内容
def get_content(self, each, weichat_id):
# article = requests.get(each, headers=self.headers, verify=False).content
html_art_url = requests.get(each, verify=False).text
soup = BeautifulSoup(html_art_url, 'html.parser')
soup_url = soup.findAll("script")[7]
# 循环获取公众号文章URL
for list_art in soup_url:
list_art_url_s = re.findall(r'content_url(.*?),', list_art)
# 获取公众号文章
for list_art_url in list_art_url_s:
list_art_url = 'http://mp.weixin.qq.com' + list_art_url.replace('":"', '').replace('"', '').replace('amp;', '')
content = requests.get(list_art_url, verify=False)
art_hash_code = self.toHash(content.url)
# 以HTML格式保存文章到本地
htmlPath = self.htmlPath + weichat_id
if not os.path.isdir(htmlPath):
os.mkdir(htmlPath)
self.get_img_text(list_art_url, weichat_id, content, htmlPath + '/%s.html' % art_hash_code)
# 获取公众号图片和内容并且保存到本地文件夹
def get_img_text(self, list_art_url, weichat_id, r, out_path):
try:
# 打开保存路径的文件out_path
f = open(out_path, 'w', encoding='utf-8')
text = r.text
# 保存图片数据
reg = r'-src="(https://mmbiz.qpic.cn/.+?)" '
# print(reg)
pic_re = re.compile(reg)
html_art_url = requests.get(list_art_url, verify=False).text
pic_list = re.findall(pic_re, html_art_url)
for pic_url in pic_list:
print(pic_url)
pic_path = self.PicPath + weichat_id + '/' + self.toHash(list_art_url) + '/'
if not os.path.isdir(pic_path):
os.mkdir(pic_path)
pic_url_new = os.path.join(pic_path, '%s.jpeg' % self.toHash(pic_url))
urllib.request.urlretrieve(pic_url, pic_url_new)
# 替换data-src里面的路径,将图片换成本地路径,使其由JS加载的动态网页变成静态HTML,然后再解析保存在本地的HTML存储到数据库
pic_url_all = 'data-src="' + pic_url + '"'
rep_pic_url = self.toHash(list_art_url) + '/' + '%s.jpeg' % self.toHash(pic_url)
rep_pic_url_all = 'src="' + rep_pic_url + '"'
text = text.replace(pic_url_all, rep_pic_url_all)
# 替换完text里的数据后将数据写入并保存文件到本地
f.write(text)
f.flush()
f.close()
# 解析保存到本地的文章
self.explain_art(out_path)
except Exception as e:
logging.error('save file:[e=%s,out_path=%s]' % (e, out_path))
# 解析下载到本地的公众号文章并且尝试存入数据库
@staticmethod
def explain_art(local_art_url):
# content = requests.get(local_art_url, verify=False).text
htmlfile = open(local_art_url, 'r', encoding='UTF-8')
htmlpage = htmlfile.read()
content_html = BeautifulSoup(htmlpage, 'lxml')
selector = etree.HTML(content_html.encode("UTF-8"))
# 文章标题
art_title = selector.xpath('//*[@id="activity-name"]')[0].text
# 文章作者
art_author_list = selector.xpath('/html/body/div[1]/div/div[1]/div[1]/div[1]/em[2]')
if len(art_author_list) > 0:
art_author = art_author_list[0].text
# 文章发表时间
art_time = selector.xpath('//*[@id="post-date"]')[0].text
# 文章来源
art_source = selector.xpath('//*[@id="post-user"]')[0].text
# 文章正文内容
# art_connect = selector.xpath('//*[@id="activity-name"]')
art_connect = content_html.findAll('div', class_='rich_media_content')[0].contents
# print(art_connect)
if __name__ == '__main__':
# @version : 3.5
# @Author : robot_lei
# @Software: PyCharm Community Edition
print("""/*
*
* _oo8oo_
* o8888888o
* 88" . "88
* (| -_- |)
* 0\\ = /0
* ___/'==='\\___
* .' \\\\\\| |// '.
* / \\\\\\||| : |||// \\\\
* / _||||| -:- |||||_ \\\\
* | | \\\\\\\\ - // | |
* | \\_| ''\\---/'' |_/ |
* \\ .-\\__ '-' __/-. /
* ___'. .' /--.--\\ '. .'___
* ."" '< '.___\\_<|>_/___.' >' "".
* | | : `- \\`.:`\\ _ /`:.`/ -` : | |
* \\ \\ `-. \\_ __\\ /__ _/ .-` / /
* =====`-.____`.___ \\_____/ ___.`____.-`=====
* `=---=`
* ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
* 佛祖保佑 永无BUG
**/ """)
weichat_spider().run()以下为MYSQL的建表语句:
CREATE TABLE `subscription` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`subEname` varchar(45) DEFAULT NULL,--微信号
`subName` varchar(45) DEFAULT NULL,--公众号
`status` tinyint(1) DEFAULT '1' COMMENT '1默认爬取 0 不爬取',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4
-- 4 itpuber ITPUB 1 插入数据 爬取的是ITPUB三、爬取结果
下图就是爬取的页面保存在本地文档之中,打开可以看到文章页面都是正常的,图片保存在相应hash码的文件夹下面。
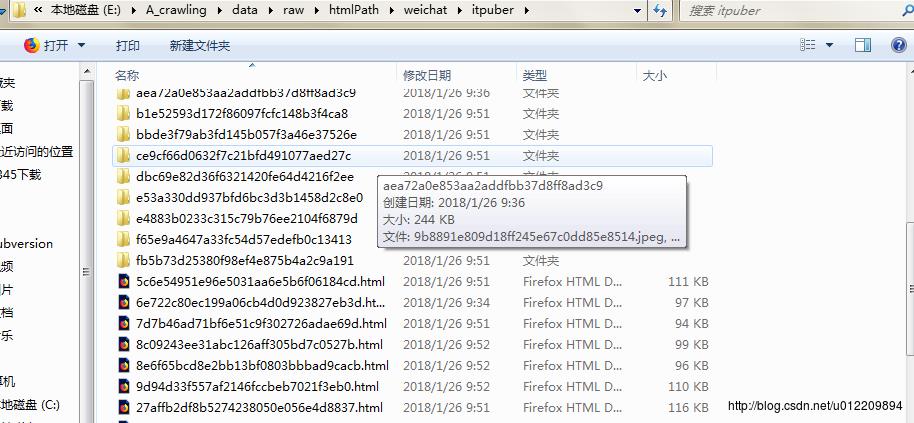
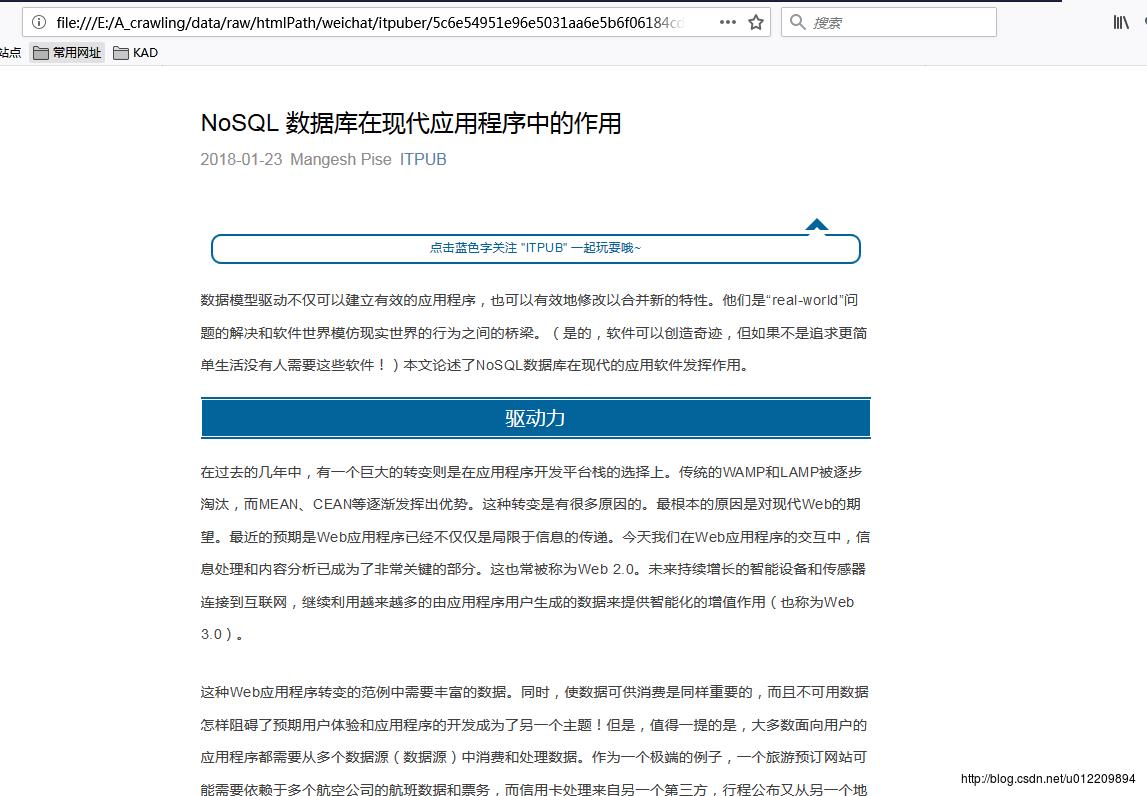
未完成问题:
1、验证码问题
2、未将下载下来的HTML文本解析进数据库中保存(目前没时间写,以后在补),有需要的也可以自行解析入库。
以上是关于python实现搜狗微信公众号数据爬取的主要内容,如果未能解决你的问题,请参考以下文章