OCR文字识别方法综述
Posted GoAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OCR文字识别方法综述相关的知识,希望对你有一定的参考价值。
✨写在前面:强烈推荐给大家一个优秀的人工智能学习网站,内容包括人工智能基础、机器学习、深度学习神经网络等,详细介绍各部分概念及实战教程,通俗易懂,非常适合人工智能领域初学者及研究者学习。➡️点击跳转到网站。
📝OCR文字识别技术介绍合集:
1️⃣OCR文字识别技术系列第一章:OCR文字识别技术总结(一)
2️⃣OCR文字识别技术系列第二章:OCR文字识别技术总结(二)
3️⃣OCR文字识别技术系列第三章:OCR文字识别技术总结(三)
4️⃣OCR文字识别技术系列第四章:OCR文字识别技术总结(四)
5️⃣OCR文字识别技术系列第五章:OCR文字识别技术总结(五)
📝OCR文字识别领域经典论文汇总:
OCR文字识别方法综述
摘 要:文字识别可以把海量非结构化数据转换为结构化数据,从而支撑各种创新的人工智能应用,是计算机视觉研究领域的分支之一,其任务是识别出图像中的文字内容,一般输入来自于文本检测得到的文本框截取出的图像文字区域。近几年来,基于深度学习的文字识别算法模型已取得不错成果,其过程无需进行特征处理且可以实现复杂场景文字识别,效果要优于传统文字识别方法,逐渐成为文字识别研究应用的主流方式。本文将主要介绍基于深度学习的文字识别技术综述,分类总结主流文字识别经典算法,讨论未来文字识别领域发展与研究趋势。
关键词:OCR,深度学习,场景识别,CTC
1.引言
文字是人类思想、知识和文化传承不可或缺的载体,也是人类信息交流和感知世界重要载体。互联网信息时代每天会产生大量的票据、表单、证件数据,这时需要利用文字识别技术进行提取录入,电子化数据对企业提升生产效率具有重要意义。文字识别技术(optical character recognition,OCR)是指运用光学技术和计算机技术对图像中的文字进行检测,然后识别出图像中的文字内容,是计算机视觉研究领域的分支之一[1]。其概念于1929年由德国科学家Tausheck最早提出并申请专利,经过近百年发展,OCR文字识别在各领域取得不错成果。文本识别的应用场景很多,有文档识别、路标识别、车牌识别、工业编号识别等,目前已经在医疗、教育等行业得到广泛应用,其综合数字图像处理、计算机图形学及人工智能等多方面的理论知识,日益成为人工智能领域关注的焦点。传统OCR识别技术虽然在印刷体字符特定场景已经可以达到很高的精度,然而在复杂场景中受光照、形状、模糊等问题导致识别精度不高。近几年来,随着深度学习成为机器学习和人工智能领域研究的最新趋势,基于深度学习的文字识别算法模型已取得不错成果,其过程无需进行特征处理且可以实现复杂场景文字识别,效果要优于传统文字识别方法,逐渐成为文字识别研究应用的主流方式。
2.基于深度学习文字识别研究现状
传统OCR文字识别是将文本行的字符识别看成一个多标签任务学习的过程。如图1所示,其识别过程为图像预处理(彩色图像灰度化、二值化处理、图像 变化角度检测、矫正处理等)、版面划分(直线检测、倾斜检测)、字符定位切分、字符 识别、版面恢复、后处理、校对等。传统文字识别一般首先需要文本区域定位,将定位后的倾斜文本进行矫正再分割出单个文字,然后使用人工特征HOG或者CNN特征,结合分类模型对单字进行识别,最后基于统计语言模型(如隐马尔科夫链,HMM)或者规则进行语义纠错,即语言规则后处理。传统OCR文字识别算法主要基于图像处理技术(如投影、膨胀、旋转等)和统计机器学习(Adaboot、SVM)实现图片文本内容提取[2],其主要应用于背景颜色单一、分辨率高的简单文档图像识别。

图1 传统文字识别方法流程
在复杂场景下,传统OCR识别精度很难满足实际应用需求,而基于深度学习OCR表现相较于传统方法更为出色[3]。基于深度学习的文字识别是利用模型算法能力,替换传统的手动方法,自动检测出文本的类别及位置信息,根据相应位置文本信息自动识别文本内容。现有多数深度学习识别算法包括图像校正、特征提取、序列预测等,其识别流程如图2所示。

图2 主流深度学习文字识别方法流程
2006 年 Hinton 提出“深度学习”概念开始[4],深度学习研究方法开始广泛应用于各个行业领域。随着近几年人工智能技术不断发展,基于深度学习的文字识别逐渐成为应用的主流技术,目前在文字识别领域已取得不错成果[5]。深度学习文字识别发展历程,如图3所示。

图3 文字识别技术发展历程
目前主流的深度学习文字识别算法有两种,分别是基于CTC[6]的算法和基于Attention算法,区别主要在解码阶段。前者是将编码产生的序列接入 CTC 进行解码,后者是把序列接入循环神经网络模块进行循环解码。此外,还有基于分割、基于Transformer及端到端等文字识别方法。

2.1 基于CTC的算法
连接主义的时序分类(connectionist temporal classification,CTC)机制通常被用在预测阶段,CTC 通过累加条件概率将 CNN 或 RNN 输出的特征转换为字符串序列。在文本识别技术中的应用可以解决时序类文本的对齐问题,即确保预测文本序列与实际文本序列顺序一致,长度相同。
作为经典文字识别算法,白翔团队等人在2016年提出一种文字识别算法CRNN[7],将卷积神经网络、循环神经网络与CTC损失函数结合,用于解决基于图像的序列识别问题,特别是场景文字识别问题。如图4所示,CRNN模型引入双向 LSTM(Long Short-Term Memory)[8]用来增强上下文建模,并通过CTC损失函数来实现端对端的不定长序列识别,其算法只需基本单词级别的标签和输入图片就可以实现模型训练,成为目前文字识别领域最流行框架之一。

图4 CRNN网络结构图
鉴于CRNN在文字识别领域取得不错成果,后人在其基础算法结构上进行改进,FaceBook公司提出改进的CTC算法Rosetta[9],其模型在CRNN基础上进行改进,模型由全卷积网网络和CTC组成,在英文数据集上识别表现较好。此外,Gao[10]等人使用CNN卷积替代LSTM,其参数更少,性能提升精度持平。以上两种算法在规则文本上都有很不错的效果,但由于网络设计的局限性,这类方法很难解决弯曲和旋转的不规则文本识别任务[11]。为了解决这类问题,部分算法研究人员在以上两类算法的基础上提出了一系列改进算法[12][13]。
2.2 基于Attention的方法
不规则文本场景识别是目前文本识别领域的主要研究方向。作为主流文字识别方法,基于Attention的方法可以实现不规则识别文本,其内容往往不在水平位置,且存在弯曲、遮挡、模糊等问题[14]。基于Attention的文字识别方法主要采用编码-解码网络结构,其主要输入图像经过卷积神经网络,用循环神经网络RNN进行序列处理,对目标数据以及相关数据赋予更大的权重,使得解码器的“注意力”集中对应到目标数据,获取信息细节,实现较长输入序列的合理向量表示。 在Attention方法出现前,RARE[15]算法提出了一种提出对不规则文本的校正方法,该方法具有自动矫正功能的鲁棒文本识别器,整个网络分为两个主要部分,一个空间变换网络STN(Spatial Transformer Network) 和一个基于Sequence2Squence的识别网络。不规则文本图像经过校正模块STN,由TPS(Thin-Plate-Spline)变换成一个水平方向的图像,该变换可以一定程度上校正弯曲、透射变换的文本,校正后送入序列识别网络进行解码。
在基于校正方法出现后,R2AM[16]算法首次Attention引入文本识别领域,该模型首先将输入图像通过递归卷积层提取编码后的图像特征,然后利用隐式学习到的字符级语言统计信息通过RNN解码输出字符。在解码过程中引入Attention 机制实现软特征选择,以更好地利用图像特征,更符合人类的直觉。基于校正的方法有较好的迁移性,除上述RARE这类基于Attention的方法外,STAR-Net[17]将校正模块应用到基于CTC的算法上,相比传统CRNN也有很好的提升。Shi[18]提出了一种基于Attention的编解码框架来识别文本。如图5所示,该算法通过卷积层进行特征提取,接入双向循环神经网络方式,能够从训练数据中学习隐藏在字符串中的字符级语言模型,可以实现规则文字识别。
综合文本校正模块及Attention方法,白翔团队等人[18]提出一种新的文本识别经典模型 ASTER。如图6所示,该算法采用编码与解码框架形式,先引入STN矫正网络模块对文字进行预处理,后结合Attention实现特征与标签信息的对齐工作。其中,整合矫正网络和识别网络成为一个端到端网络来训练,现已广泛应用于不规则场景文字识别。由于ASTER在解决不规则场景文本识别任务上表现出了良好的性能,但是基于校正的方法往往受到字符几何特征的限制,并且模型更容易被背景噪声影响。

图6 ASTER网络结构图
为克服上述问题,Luo等人[19]提出了多目标矫正注意力网络(multi-object rectified attention network,MORAN),如图7所示所示,其结构由多目标矫正网络和基于 Attention 机制的序列识别网络构成,其中矫正网络是一个像素级矫正网络,该网络不受几何约束,变换更加灵活,可以完美处理不规则文本识别问题。

图6 MORAN网络结构图
后续有大量算法在Attention领域进行探索和更新,例如SAR[20]将1D attention拓展到2D attention上,校正模块提到的RARE也是基于Attention的方法,实验证明基于Attention的方法相比CTC的方法有很好的精度提升。Cheng等人[21]提出了一种聚焦注意力网络FAN,针对在处理低像素/复杂的图像时,基于注意力机制的方法表现不佳,主要是由于注意力网络无法将这种特殊图像中字符的注意中心准确地集中到对应的目标区域的中心,可以通过聚焦网络来检测并矫正注意力中心,有效解决注意力偏移问题。
综上所述,虽然CRNN+CTC在长文本识别取得不错的效果,但只能解决一维的序列识别问题,且当文本行的形变较大时,CTC的识别效果将会受到很大的影响。而Seq2Seq+Attention的识别方式,虽然原则上能够解决二维的序列识别问题,但受限于RNN网络在长序列识别中的局限性,且seq2seq的串行机制导致在长序列文本识别和运行效率上的表现并不好[22]。为克服上述问题,2019年金连文团队等人[23]提出了基于交叉熵损失的序列识别算法ACE。如图7所示,ACE算法的解码方法不同于CTC和Attention,其监督信号实际上是一种弱监督,忽略标签中字符标注的对应关系,没有先后顺序信息,注重于字符出现的次数,在较低复杂度情况下实现与主流识别技术相当的效果。ACE 损失在时间复杂度和空间复杂度上要优于CTC损失,并且可以用于多行文字识别,从另一角度解决上述两种方法存在的问题。
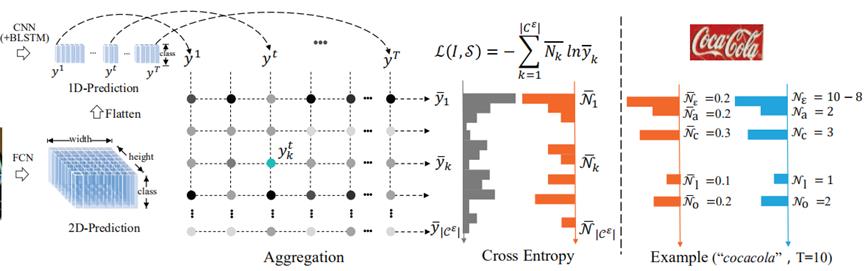
图7 ACE算法结构图图
2020年,Hu[24]等人又提出一种新的融合文本识别算法GTC, 将上述基于Attention和CTC两种方式进行融合,利用Attention对CTC的对齐进行监督和引导,有效解决了CRNN网络缺乏聚焦于局部区域能力的问题,GTC模型将提取到的特征分别传入CTC解码器和注意力指示器。同时加入GCN图卷积神经网络提高模型表达能力,实验效果优于上述几种方法。

基于Attention方法总结

2.3基于分割的方法
基于分割的方法是将文本行的各字符作为独立个体,相比与对整个文本行做矫正后识别,识别分割出的单个字符更加容易[25]。试图从输入的文本图像中定位每个字符位置,并应用字符分类器来获取识别结果,将复杂全局问题简化成局部问题解决,在不规则文本场景下有比较不错的效果,然而该方法需要字符级别的标注,数据获取上存在一定难度。Lyu[26]等人提出了一种用于单词识别的实例分词模型,该模型在其识别部分使用了基于 FCN的方法。文献[27]从二维角度考虑文本识别问题,设计字符注意FCN来解决文本识别问题,当文本弯曲或严重扭曲时,该方法对规则文本和非规则文本都具有较优的定位结果。
2022年,金连文[28]等人提出新的基于无分割的端到端文本识别算法,其结果采取全神经网络模型,将弱监督学习模块与上下文信息结合进行联合训练。其中针对提出新的弱监督学习方法,使网络能够仅使用转录本注释进行训练,可以避免字符分割注释,在手写文本数据集识别效果优于上述无分隔识别算法,结构如图8所示。

图8 无分隔识别算法结构图
2.4基于Transformer的方法
随着 Transformer 的快速发展,分类和检测领域验证 Transformer 在视觉任务中的有效性。比如在规则文本识别部分,CNN在长依赖建模上存在局限性,Transformer 结构恰好解决这一问题,它可以在特征提取器中关注全局信息,并且可以替换额外LSTM上下文建模模块。
Yu D等人在2020年提出一个新的端到端可训练框架算法SRN[29]。如图9所示,SRN由主干网、并行视觉提示模块(PVA提出并行注意力模块)、全局语义推理模块(GSRM)和视觉语义融合解码器(VSFD)四部分组成,可以将读取顺序用作查询,使得计算与时间无关,最终并行输出所有时间步长的对齐视觉特征。SRN算法利用Transformer的Encoder作为语义模块,将图片的视觉信息和语义信息做融合,在遮挡、模糊等不规则文本上具有不错识别效果。NRTR算法[30]提出使用完整的Transformer结构对输入图片进行编码和解码,使用简单的积层进行特征提取,在文本识别上验证Transformer结构的有效性。
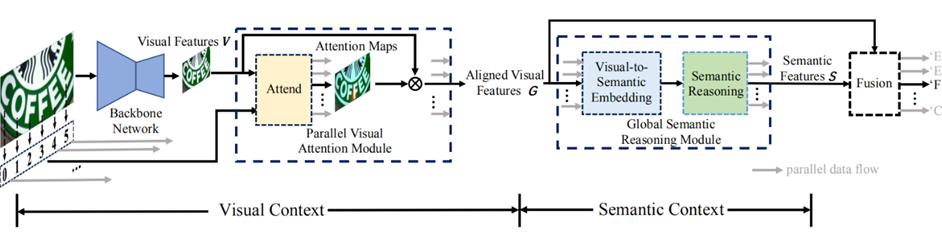
图9 SRN算法结构图
2.5 端到端识别方法
端到端的识别方法可以共享文本检测与识别的信息,并且可以对其进行联合优化,整体推理速度要比级联方式更快。端对端方式训练出来的模型可以学习到更丰富的图像特征,只需要一个网络,输入一张图片,同时输出检测和识别的结果,可以有效的节省时间。STN-OCR[31]网络将检测和识别集成,可以进行端到端的文本识别。该网络使用半监督的方式进行训练,无需标注文本位置信息,整个系统可进行端到端训练。基于端到端文字识别方法FOTS[32],可以快速文本定位网络,运用RoI Rotate模块实现检测和识别结合,文字识别速度快且效果好。Mask TextSpotter[33]利用简单且平滑的端到端学习过程,通过语义分割获得精确的文本检测和识别。此外,本方法在处理不规则形状的文本实例(例如,弯曲文本)方面优于之前的方法。ABCNet[34]网络是一个端到端的场景文本检测识别网络,该网络首次通过参数化的贝塞尔曲线自适应拟合任意形状文本,其计算成本可忽略,其中BezierAlign层可以准确提取卷积特征使识别精度显著提高,在检测多方向多尺度文本时更加平滑且速度快,可以实现实时文本识别,其结构如图10所示。

图10 ABCNet算法结构图
基于上述深度学习的规则文本、不规则文本、端到端等文字识别方法,本文对主流文字识别方法及各领域的代表性论文进行总结,如表1所示。
表1 主流文字识别方法总结
| 算法类别 | 主要思路 | 主要论文 | ||
| 传统算法 | 滑动窗口、字符提取、动态规划 | |||
| CTC | 基于CTC的方法,序列不对齐,快速识别 | CRNN,Rosetta | ||
| Attention | 基于attention的方法,应用于非常规文本 | RARE,DAN,PREN | ||
| CTC+Attention | 融合CTC和Attention思想 | GTC | ||
| Transformer | 基于transformer的方法 | SRN,NRTR,Master,ABINet | ||
| 校正 | 校正模块学习文本边界并校正成水平方向 | RARE,ASTER,SAR | ||
| 分割 | 基于分割的方法,提取字符位置再做分类 | TextScanner, Mask TextSpotter | ||
3.文字识别数据集及评价指标
文本识别其任务是识别出图像中的文字内容,一般输入来自于文本检测得到的文本框截取出的图像文字区域[35]。 根据实际场景不同,文本识别数据集一般可以根据待识别文本形状分为规则文本识别和不规则文本识别两大类,分类结果如图11所示。

图11 规则文本与不规则文本数据集分类
不同的识别算法一般通过上述两种公开数据集进行比较,目前较为通用的英文评估集合分类。规则文本识别主要指印刷字体、扫描文本等场景,认为文本大致处在水平线位置,其代表数据集主要有IC13[36]、SVT[37]、IIIT5K[38]等。不规则文本识别是出现在自然场景中,且由于文本曲率、方向、变形等方面差异巨大,文字往往不在水平位置,存在弯曲、遮挡、模糊等问题,其代表数据集有IC15 [39]、COCO-Text[40]、SVTP[41]、CUTE [42]等。针对合适的文字识别数据集,找到对应的识别方法应用其中是至关重要的。每种数据集都对应于不同的OCR识别处理方法,每种方法也都有适合的数据集。根据图像采集方式不同,字符数据集可分为三类:自然环境下采集的字符图像数据集、手写字符图像数据集、计算机不同字体合成的字符图像数据集,其中中文文字数据集 ICDAR2019-LSVT[43]、ICDAR2019-ReCTS[44]、CTW[45]、ShopSign[46]等;合成的文字数据集包括 Synth90K[47]、SynthText[48]、SynthAdd[49]等。
本文对常见文字识别数据集的信息进行总结和整理,包括中英文常见文字数据集如表2所示。

评价指标
文字识别目前用的最多的评价准则有词准确度 ( Accuracy ) 、字符准确度、编辑距离、归一化编辑距离、语境相关的评测方式等。上述评价指标的详细信息如图 所示。
编辑距离:
编辑距离是针对二个字符串(例如英文字)的差异程度的量化量测,量测方式是看至少需要多少次的处理才能将一个字符串变成另一个字符串。在莱文斯坦距离中,可以删除、加入、替换字符串中的任何一个字元,也是较常用的编辑距离定义,常常提到编辑距离时,指的就是莱文斯坦距离。
其他说明:
平均识别率:[ 1 - (编辑距离 / max(1, groundtruth字符数, predict字符数) ) ] * 100.0%
平均编辑距离:编辑距离的平均值,用来评估整体的检测和识别模型;
平均替换错误:编辑距离计算时的替换操作,用于评估识别模型对相似字符的区分能力;
平均多字错误:编辑距离计算时的删除操作,用来评估检测模型的误检和识别模型的多字错误;
平均漏字错误:编辑距离计算时的插入操作,用来评估检测模型的漏检和识别模型的少字错误;
关于编辑距离指标可参考:编辑距离算法(Edit Distance)
4.文字识别技术发展及研究趋势
目前,基于深度学习的文字识别技术发展较为成熟,在教育、医疗行业得到广泛应用,但由于目前开源数据集较为缺乏,导致识别算法提升受到一定限制[50]。在识别场景方面,人们对文字识别在复杂场景识别效果的要求越来越高;文字识别技术未来研究趋势主要体现在以下几个方面:
(1)复杂场景文字识别
深度学习在文字识别领域方面具有天然优势,虽然所能解决的问题越来越复杂,但是同样存在一定问题需要被解决,如对密集文本和不规则文本的检测性能仍远远低于检测水平文本的性能。尤其是在手写场景下识别,如手写数学公式识别、少数民族语言识别等研究具有重要意义[51][52]。其次,如何在自然场景、复杂场景(如字符变形、重叠)、多语种场景(一张同时含有多种文字)等进行文字检测与识别,解决字符定位及预处理问题,提升识别准确率效果,是文字识别未来研究热门方向[53]。
(2)零样本、少样本学习(Zero-shot[54]/Few-shot[55])
在文字识别过程中结合零样本学习或小样本学习算法,联合上下文语义信息,是文字识别技术未来发展的热门研究趋势之一。尤其是在古籍识别研究方面,通过在训练样本中不加入或者少加入相关识别字符,结合多种辅助信息,将视觉模型与上下文语义信息进行融合,实现用部分类别(如简体字)的样本训练识别,推广到识别新类别(如繁体字)样本,使机器达到识别未见过文字的效果。
(3)大规模数据集及字符集标注
数据集作为文字识别算法提升的关键,直接影响最终识别效果。目前文字识别领域开源的文字数据集比较匮乏。一方面,企业将相关业务数据作为隐私,导致无法公开;另一方面,在学术领域方向文字识别数据集受人工及技术条件限制,导致数据规模较小。因此,未来需要我们开源更多处理后的大规模文字数据集,一方面可以尝试通过数据增强相关算法进行数据增广;另一方面,可以通过GAN生成对抗网络[56]生成多种字体图像,提高识别算法模型的性能与泛化能力。
5.结论
本文将主要介绍基于深度学习的文字识别技术综述,分类总结主流文字识别经典算法,分别列举经典论文的思路和贡献。首先,本文介绍规则文本识别的基于CTC与基于Attention、Transformer及分割等方法,对端到端算法进行总结。最后,讨论文字识别领域发展与研究趋势。传统OCR发展至今,已经解决大部分简单场景且取得很好效果,但在一些复杂场景,传统OCR识别精度很难满足实际应用需求。基于深度学习的OCR表现相较于传统方法更为出色,随着近几年人工智能技术不断发展,基于深度学习的文字识别逐渐成为应用的主流技术,目前在文字识别领域已取得不错成果,其未来发展方向将逐步扩大到更多、更复杂的场景,结合多领域跨学科工作,使文字识别技术在人工智能应用更加成熟。作为深度学习的推动力,数据起到至关重要的作用,因此开源大规模数据集也是现阶段提升文字识别效果的重点。另外,在文字识别应用方面,需要我们引入更多轻量级模型,保证一定精度的同时提升模型训练速度,使其系统能够快速部署到服务器端。
参考文献
- 刘伟红.中文古籍数字化的现状与意义[J]. 图书与情报, 2009 (4): 134-137
- 姜维, 张重生, 殷绪成. 基于深度学习的场景文字检测综述[J].电子学报, 2019, 47(5): 1152.
- 刘艳菊,伊鑫海,李炎阁,张惠玉,刘彦忠.深度学习在场景文字识别技术中的应用综述[J].计算机工程与应用,2022,58(04):52-63.
- A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
- 金连文,钟卓耀等.深度学习在手写汉字识别应用综述[J].自动化学报2016,42(8):1125-1141.
- Graves, Alex, et al.Connectionist temporal classification: labelling unsegmented sequence data withrecurrent neural networks. In ICML, 2006.
- Shi B, Bai X,Yao C. An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition[J]. ieee transactions on pattern analysis & machine intelligence, 2016, 39(11):2298-2304.
- F. A. Gers, N. N. Schraudolph, and J. Schmidhuber. Learning precise timing with LSTM recurrent networks. JMLR,3:115–143, 2002.
- Fedor Borisyuk, Albert Gordo, and Viswanath Sivakumar. Rosetta: Large scale system for text detection and recognition in images. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 71–79. ACM, 2018.
- Gao, Yunze, et al. Reading scene text with attention convolutional sequence modeling. arXiv preprint arXiv:1709.04303, 2017.
- 王德青,吾守尔等.场景文字识别技术研究综述[J]. 计算机工程与应用, 2020, 56(18): 1-15.
- 牛小明, 毕可骏, 唐军.图文识别技术综述[J].中国体视学与图像分析, 2019, 25(3):241-256.
- 甘吉. 手写文字识别及相关问题算法研究[D].中国科学院大学(中国科学院计算机科学与技 术学院),2021.DOI:10.44196/d.cnki.gjskx.2021.000003.
- Shi B, Wang X, Lyu P, et al. Robust scene text recognition with automatic rectification[C]// Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 4168-4176.
- Lee C Y , Osindero S . Recursive Recurrent Nets with Attention Modeling for OCR in the Wild[C]// IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2016.
- Star-Net Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spa- tial transformer networks. In Advances in neural information processing systems, pages 2017–2025, 2015.
- Baoguang Shi, Mingkun Yang, XingGang Wang, Pengyuan Lyu, Xiang Bai, and Cong Yao. Aster: An attentional scene text recognizer with flexible rectification. IEEE transactions on pattern analysis and machine intelligence, 31(11):855–868, 2018.
- F. A. Gers, N. N. Schraudolph, and J. Schmidhuber. Learning precise timing with LSTM recurrent networks. JMLR,3:115–143, 2002.
- Luo C, Jin L, Sun Z. A multi-object rectified attention network for scene text recognition[J]. Pattern Recognition, 2019, 90: 109-118.
- Li H, Wang P, Shen C, et al. Show, attend and read: A simple and strong baseline for irregular text recognition[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 8610-8617.
- Cheng Z, Bai F, Xu Y, et al. Focusing attention: Towards accurate text recognition in natural images[C]//Proceedings of the IEEE international conference on computer vision. 2017: 5076-5084.
- Lee C Y , Osindero S . Recursive Recurrent Nets with Attention Modeling for OCR in the Wild[C]// IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2016.
- Xie Z, Huang Y, Zhu Y, et al. Aggregation cross-entropy for sequence recognition[C] //Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA, 2019: 6538-6547
- Hu W, Cai X, Hou J, et al. Gtc: Guided training of ctc towards efficient and accurate scene text recognition[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(07): 11005-11012.
- Raja S, Mondal A, Jawahar C V. Table structure recognition using top-down and bottom-up cues[C]//European Conference on Computer Vision. Springer, Cham, 2020: 70-86.
- P. Lyu, C. Yao, W. Wu, S. Yan, and X. Bai. Multi-oriented scene text detection via corner localization and region segmentation. In Proc. CVPR, pages 7553–7563, 2018.
- Liao M, Zhang J, Wan Z, et al. Scene text recognition from two-dimensional perspective[C] //Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 8714-8721.
- Peng D, Jin L, Ma W, et al. Recognition of Handwritten Chinese Text by Segmentation: A Segment-annotation-free Approach[J]. IEEE Transactions on Multimedia, 2022.
- Yu D, Li X, Zhang C, et al. Towards accurate scene text recognition with semantic reasoning networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 12113-12122.
- Sheng F, Chen Z, Xu B. NRTR: A no-recurrence sequence-to-sequence model for scene text recognition[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 781-786.
- Bartz C, Yang H, Meinel C. STN-OCR: A single neural network for text detection and text recognition[J]. arXiv preprint arXiv:1707.08831, 2017.
- Liu X, Liang D, Yan S, et al. Fots: Fast oriented text spotting with a unified network[C] //Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 5676-5685.
- Lyu P, Liao M, Yao C, et al. Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 67-83.
- Liu Y, Chen H, Shen C, et al. Abcnet: Real-time scene text spotting with adaptive bezier-curve network[C]//proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 9809-9818.
- 张华萍,黄辰.文字识别技术研究[J].物联网技术,2018,8(08):17-19.DOI:10.16667/j.issn.2095- 1302.2018.08.002.
- Karatzas D, Shafait F, Uchida S, et al. ICDAR 2013 robust reading competition[C]//2013 12th International Conference on Document Analysis and Recognition. IEEE, 2013: 1484-1493.
- Wang K, Babenko B, Belongie S. End-to-end scene text recognition[C]//2011 International conference on computer vision. IEEE, 2011: 1457-1464.
- Yasmeen U, Shah J H, Khan M A, et al. Text detection and classification from low quality natural images[J]. 2020.
- Karatzas D, Gomez-Bigorda L, Nicolaou A, et al. ICDAR 2015 competition on robust reading[C]// international conference on document analysis IEEE, 2015: 1156-1160.
- Veit A, Matera T, Neumann L, et al. Coco-text: Dataset and benchmark for text detection andrecognition in natural images[J]. arXiv preprint arXiv:1601.07140, 2016
- Phan T Q, Shivakumara P, Tian S, et al. Recognizing text with perspective distortion in naturalscenes[C]//Proceedings of the IEEE International Conference on Computer Vision. 2013: 569-576.
- Risnumawan A, Shivakumara P, Chan C S, et al. A robust arbitrary text detection system for natural scene images[J]. Expert Systems with Applications, 2014, 41(18): 8027-8048.
- Sun Y, Ni Z, Chng C K, et al. ICDAR 2019 competition on large-scale street view text with partial labeling-RRC-LSVT[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1557-1562.
- Zhang R, Zhou Y, Jiang Q, et al. Icdar 2019 robust reading challenge on reading chinese text onsignboard[C]//2019 international conference on document analysis and recognition (ICDAR). IEEE, 2019: 1577-1581.
- Yuan T L, Zhu Z, Xu K, et al. A large chinese text dataset in the wild[J]. Journal of Computer Science and Technology, 2019, 34(3): 509-521.
- Zhang C, Ding W, Peng G, et al. Street view text recognition with deep learning for urban sceneunderstanding in intelligent transportation systems[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(7): 4727-4743.
- Jaderberg M, Simonyan K, Vedaldi A, et al. Synthetic data and artificial neural networks for natural scene text recognition[J]. arXiv preprint arXiv:1406.2227, 2014.
- Gupta A, Vedaldi A, Zisserman A. Synthetic data for text localisation in natural images[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2315-2324.
- Li H, Wang P, Shen C, et al. Show, attend and read: A simple and strong baseline for irregular text recognition[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 8610-8617.
- 白文荣. 联机手写蒙古文字识别技术的研究[D].内蒙古大学,2007.
- 路燕. AI文字识别技术在城市规划档案数字化中的运用[J].科学技术创新,2022(14):54-57
- Chen X, Jin L, Zhu Y, et al. Text recognition in the wild: A survey[J]. ACM Computing Surveys (CSUR), 2021, 54(2): 1-35.
- Romera-Paredes B, Torr P. An embarrassingly simple approach to zero-shot learning[C] //International conference on machine learning. PMLR, 2015: 2152-2161.
- Sung F, Yang Y, Zhang L, et al. Learning to compare: Relation network for few-shot learning[C] //Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 1199-1208.
- Karras T, Laine S, Aittala M, et al. Analyzing and improving the image quality of stylegan[C] //Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 8110-8119.
场景文字检测与识别方法分类
1.场景文字检测方法分类:
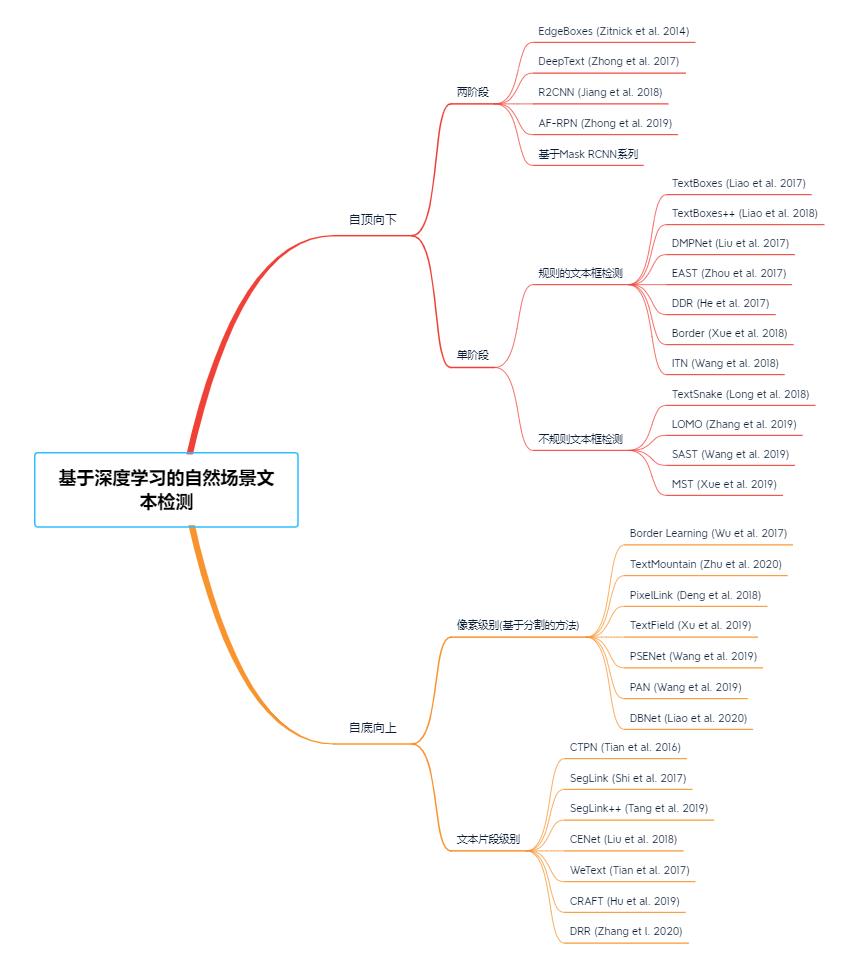
2.场景文字识别方法分类:

3.端到端自然场景检测和识别方法:

本文参考: 飞桨AI Studio - 人工智能学习与实训社区
以上是关于OCR文字识别方法综述的主要内容,如果未能解决你的问题,请参考以下文章