Pipeline大数据架构
Posted 王小雷-多面手
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pipeline大数据架构相关的知识,希望对你有一定的参考价值。
1.Pipeline大数据架构
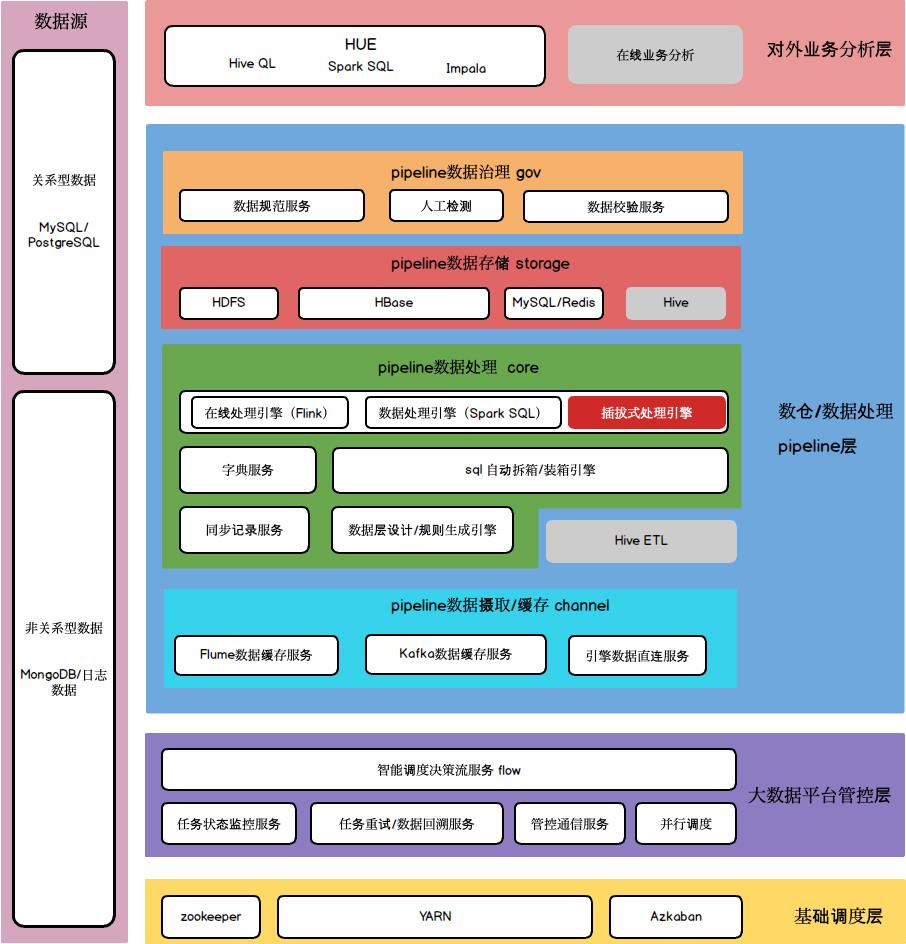
(create by 王小雷)
Pipeline大数据架构,面向大数据仓库和大数据处理平台。是基于lambda的大数据架构的变种,增加了企业级服务,而并非只是大数据组件的对切,是一种更落地的方案。
如同骨架之间使用软骨连接起来一样,是一个完整可执行的架构设计。形成Pipeline架构。
Pipeline大数据架构由一个源、四个层(1+4)组成。
2.数据源
数据源是泛指需要大数据平台处理的所有数据源。大多时候是企业的业务系统产生的,这部分一般都是在大数据平台之外,而且关系型数据为主。
2.1.关系型数据源
如mysql、PostgreSQL中的业务数据,这部分是绝多大企业要处理的数据。
2.2.非关系型数据源
如MongoDB数据、日志数据等。
3.基础调度层
大数据处理是集群执行的。那么就需要大数据应用的任务调度、资源调度。
其中有很多大数据组件具有调度能力。称为基础调度层。
3.1.Zookeeper
3.2.YARN
3.3.Azkaban
4.大数据平台管控层
管控层在基础调度层之上,上文是数仓/数据处理层,下文是基础调度层。旨在让集群资源、任务调度机制更加定制、自动、智能化。
比如一个很大的数据处理,需要两种通道Hive ETL或者Spark SQL都可以处理,但是根据文件大小和结构,百分之三十用Hive ETL,70%用Spark SQL处理。
让处理时间和资源占用达到整体较优。
4.1.智能调度决策流服务
数据处理是多种通道的,如Spark处理、Flink处理,但是根据数据的特点和业务要求,需要通过不同策略调用不同处理方式来处理数据。
4.2.任务状态监控服务
整个Pipeline任务执行时间、状态、结果都是需要监控服务来记录和报警的。
4.3.任务重试/数据回溯服务
某个单元数据处理出现问题、未通过数据校验等需要这部分数据重新计算或者回溯原始数据。
4.4.管控通信服务
集群管控信息收集后发送给大数据对应模块负责人。邮件为主,紧急可以短信。
4.5.并行调度服务
为了充分利用资源和任务特性,有些数据处理任务需要并行调度。
5.数据仓库/数据处理(离线处理/实时处理)层
Pipeline大数据架构核心层,数仓、数据湖泊、实时处理、批处理,也是lambda核心的变种,同样增了企业级可行性服务。
如字典服务,规则生成引擎等。
5.1.pipeline数据摄取/缓存
大数据系统外/内的待处理数据或者输出数据的大通道,一切数据的在大数据平台的进出由该模块负责。
如果细胞的细胞壁。也如同屠夫的钩子(按Q)。
5.1.1.Flume数据缓存服务
大多时候是接入Log日志,如数据库的write-ahead logging (WAL)、系统埋点日志数据等等,无侵入接入数据。
5.1.2.Kafka数据缓存服务
通常是来对接Flume,用Topic等连接,并分发到计算引擎或者沉淀到存储系统,或者暂时缓存数据。
5.1.3.引擎数据直连服务
引擎直连服务可能对业务系统有害,因为是侵入式直连,数据的抽取或者写入会对业务系统有很大影响。
但是,敏捷开发,或者刚开始建立大数据平台,这种方式来的最快。不需要更多大数据链路,抽过来数据直接处理。这先落地再优化的方法,何乐而不为呢(减少加班吧)。
5.2.Pipeline数据处理 core
5.2.1.在线处理引擎
Flink
5.2.2.离线处理引擎
Spark SQL
5.2.3.字典服务
业务系统有多个产品,多个库,它们根据业务不同,库、表、字段各不相同,需要大数据这边有一个字典服务,记录、汇总、跟踪业务系统数据字典。
为SQL自动拆箱/装箱引擎、数据层设计/规则生成引擎提供原料。
5.2.4.SQL自动化拆箱/装箱引擎
配合计算引擎,达到批量计算,如有1万张表需要抽取到大数据仓库,用Spark SQL实现,其中包括数据的特殊更改、全量、增量、流水、拉链等操作。
5.2.5.同步记录服务
多业务多库多表同步到数仓或者处理时候,增量同步记录服务。
5.2.6.数据层设计/规则生成引擎
业务分析师将业务数据与大数据开发团队对接。
将业务数据规则设计为大数据数据,偏向业务对接、分析。
5.2.7.Hive数据ETL服务
作为数据处理的工具,可做简单的ETL工作。
5.3.Pipeline数据存储
数仓存储根据层次、业务的不同可存储不同。原始数据,非规则化数据,超大文件可存储在HDFS上,冷数据做压缩处理。
HBase直接对接引擎计算后的数据沉淀。
Hive可存储不同层次的数据,但是更多时候是做数仓的管理工具,如外部数据HDFS、Hbase等外部表。
5.3.1.HDFS
5.3.1.HBase
5.3.1.MySQL、Redis
5.3.1.Hive
5.4.Pipeline数据治理
数据治理是在数据接入到大数据平台时做规范,如日期规范、脱敏、字段类型映射等等。
5.4.1.数据规范服务
5.4.2.人工检测
5.4.3.数据校验服务
6.对外业务分析层
6.1.HUE提供SQL查询功能,供业务分析部分使用
1HiveQL SparkSQL Impala
6.2.1.在线业务分析
6.2.1.组成 Restful/web服务
扫码关注

以上是关于Pipeline大数据架构的主要内容,如果未能解决你的问题,请参考以下文章