LinuxBPF学习笔记 - bpftrace开发[7]
Posted 宣之于口
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LinuxBPF学习笔记 - bpftrace开发[7]相关的知识,希望对你有一定的参考价值。
bpftrace是基于BPF和BCC构建的开源跟踪程序。 与BCC一样,bpftrace附带了许多性能工具和支持文档。 但是,它也提供了高级编程语言,允许创建功能强大的单行代码和简短的工具。 bpftrace是使用自定义单行代码和简短脚本的临时工具的理想选择,而BCC是复杂工具和守护程序的理想选择
BPFTRACE 组件
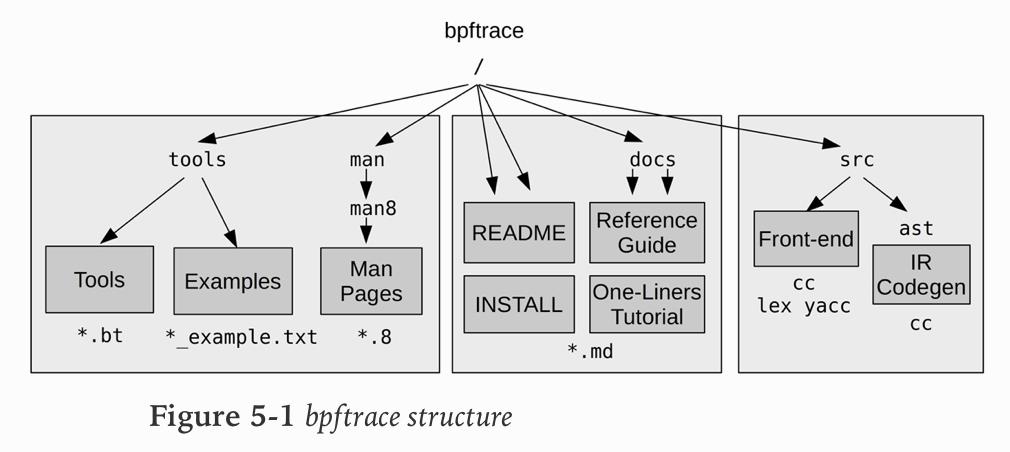
bpftrace包含有关工具,手册页和示例文件的文档,以及bpftrace编程教程(单行教程)和编程语言参考指南。 bpftrace工具的扩展名为.bt. 前端使用lex和yacc解析bpftrace编程语言,并使用Clang解析结构。 后端将bpftrace程序编译为LLVM中间表示,然后由LLVM库编译为BPF
一、运行
将执行程序,检测其定义的所有事件。 该程序将一直运行到Ctrl-C或显式调用exit()为止
1. one-liner
以-e参数运行的bpftrace程序称为one-liner
$ bpftrace -e program
2. 文件
可以将程序保存到文件并使用以下命令执行。.bt扩展名不是必需的,但有助于以后识别
$ bpftrace file.bt
也将文件设置为可执行文件(chmod a + x file.d)并像运行其他程序一样运行. 注意 bpftrace必须由root用户执行
$ sudo ./file.bt
二、程序结构
在文件顶部放置解释行
#!/usr/local/bin/bpftrace
bpftrace程序是一系列具有相关操作的探针(probes),当probes将执行相关的操作, 之前可以包含一个可选的过滤器表达式. 只有在过滤器表达式为true时,才会触发该操作
probes actions
// 可选的过滤器表达式
probes /filter/ actions
...
1. Probe
探针以探针类型名称开头,然后以冒号分隔的层次结构
type:identifier1[:identifier2[...]]
层次结构由探针类型定义,例如:
- kprobe探针类型检测内核函数调用,只需要一个标识符:内核函数名
- uprobe探针类型用于检测用户级别的函数调用,并且需要binary路径和函数名称
kprobe:vfs_read
uprobe:/bin/bash:readline
可以使用逗号分隔符指定多个探针以执行相同的操作. 有两种不需要额外标识符的特殊探针类型:bpftrace程序的开头和结尾均使用BEGIN和END触发
probe1,probe2,... actions
a. Probe 通配符
**示例:**将检测所有以vfs_开头的kprobes(内核函数)
kprobe:vfs_*
检测过多的探针可能会导致不必要的性能开销。 为了避免意外发生,bpftrace具有将启用的可调的最大探针数,可以通过BPFTRACE_MAX_PROBES环境变量(当前默认为5125)进行设置
您可以在使用bpftrace -l之前测试通配符
$ bpftrace -l 'kprobe:vfs_*'
kprobe:vfs_fallocate
kprobe:vfs_truncate
[...]
$ bpftrace -l 'kprobe:vfs_*' | wc -l
56
2. Filters
过滤器是布尔表达式,用于决定是否执行某项操作,例如:
# 仅当pid等于123时,才执行操作
/pid == 123/
# 等同于 pid != 0
/pid/
# 可以与布尔运算符(例如 &&)结合使用
/pid > 100 && pid < 1000/
3. Action
Action可以是单个语句,也可以是多个由分号分隔的语句
action one; action two; action three
语句使用类似于C语言,并且可以操纵变量并执行bpftrace函数调用. 将变量$x设置为42,然后使用printf()打印该变量
$x = 42; printf("$x is %d", $x);
到这里, 我们可以理解以下代码
// 单行, 打印 Hello World!
$ bpftrace -e 'BEGIN printf("Hello World!\\n") '
// 写作文件形式
#!/usr/local/bin/bpftrace
BEGIN
printf("Hello World!\\n");
三、变量
共有三种变量类型:built-ins, scratch, 和 maps
1. Built-in
内置变量是bpftrace预先定义和提供的,通常是只读信息源。 其中包括进程号的pid,进程名的comm,时间戳 (以纳秒为单位) 和curtask (当前线程的 task_struct 地址)
| 变量 | 含义 | 变量 | 含义 |
|---|---|---|---|
| pid | 进程ID | retval | 返回值 |
| tid | 线程ID | func | trace函数名 |
| uid | 用户ID | probe | probe的全名 |
| nsecs | 纳秒级时间戳 | kstack | 多行字符串的形式返回内核级堆栈跟踪 |
| cpu | 处理器ID | ustack | 多行字符串的形式返回用户级堆栈跟踪 |
| comm | process name | args | 参数 |
a. 位置参数
通过命令行传递给程序的,并且基于Shell脚本中使用的位置参数, $1表示第一个参数,$2表示第二个参数,以此类推
格式
bpftrace ./watchconn.bt 181
bpftrace -e 'program' 181
**示例1: **监视在命令行上传递的PID ./watchconn.bt 181
BEGIN
printf("Watching connect() calls by PID %d\\n", $1);
tracepoint:syscalls:sys_enter_connect
/pid == $1/
printf("PID %d called connect()\\n", $1);
示例2: 默认情况下,它们是整数。 如果将字符串用作参数,则必须通过str()调用对其进行访问
$ bpftrace -e 'BEGIN printf("Hello, %s!\\n", str($1)); ' Reader
2. Scratch
临时变量可用于临时计算,并具有$前缀。 他们的名称和类型是在他们第一次分配时设定的. 这些只能在分配了它们的操作块中使用。 如果在没有赋值的情况下引用变量,则bpftrace将出错
# 将$x声明为整数
$x = 1;
# 将$y声明为字符串
$y = "hello";
# 将$z声明为指向结构task_struct的指针
$z = (struct task_struct *)curtask;
3. Map
映射变量使用BPF map 存储对象,并具有@前缀。 它们可用于全局存储,在操作之间传递数据。
格式:
@name
@name[key]
@name[key1, key2[, ...]]
**示例1:**当probe1触发时,将1分配给@a,然后当probe2触发时,将@a分配给$x。 如果先触发probe1,然后触发probe2,则$x将设置为1,否则将设置为0(未初始化)
probe1 @a = 1;
probe2 $x = @a;
示例2: 将nsecs内置变量,分配给名为@start的映射,并且将tid(当前线程ID)设为键值, 时间戳为对应的值。 这样一来,线程就可以存储不会被其他线程覆盖的自定义时间戳
@start[tid] = nsecs;
示例3: 其中同时使用pid内置变量和$fd变量作为键
@path[pid, $fd] = str(arg0);
四、函数
1.内置函数
除了用于打印格式化输出的printf(),其他内置函数包括
printf(): 输出格式与C语言类似, %d等
printf("%16s %-6d\\n", comm, pid)
join(char *arr[]): 将带有空格字符的字符串数组连接起来并打印出来
$ bpftrace -e 'tracepoint:syscalls:sys_enter_execve join(args->argv); '
Attaching 1 probe...
ls -l
df -h
date
ls -l bashreadline.bt biolatency.bt biosnoop.bt bitesize.bt
str(char *): 从指针返回字符串
$ bpftrace -e 'ur:/bin/bash:readline printf("%s\\n", str(retval)); '
kstack(mode [, limit]) / ustack: 返回内核级/用户级堆栈
// 通过跟踪block:block_rq_insert跟踪点,显示导致创建块I/O的前三个内核框架
$ bpftrace -e 't:block:block_rq_insert @[kstack(3), comm] = count(); '
// mode参数允许堆栈输出采用不同的格式。 当前仅支持两种模式:bpftrace (默认模式) 和 perf,其生成的堆栈格式类似于Linux perf
$ bpftrace -e 'k:do_nanosleep printf("%s", ustack(perf)); '
ksym(), usym() : 将地址解析为其符号名称
$ bpftrace -e 'tracepoint:timer:hrtimer_start @[args->function] = count(); '
[...]
@[-1169114960]: 2517
@[-1169048384]: 8237”
// 这些是原始地址, 使用ksym()将它们转换为内核函数名称
$ bpftrace -e 'tracepoint:timer:hrtimer_start @[ksym(args->function)] = count(); '
[...]
@[it_real_fn]: 2269
@[hrtimer_wakeup]: 7714
@[tick_sched_timer]: 27092
system(format[, arguments ...]): 在shell上运行命令
$ bpftrace --unsafe -e 't:syscalls:sys_enter_nanosleep system("ps -p %d\\n", pid); '
Attaching 1 probe...
PID TTY TIME CMD
1148 ? 00:02:43 google_osconfig
PID TTY TIME CMD
1148 ? 00:02:43 google_osconfig
PID TTY TIME CMD
1148 ? 00:02:43 google_osconfig
2. Map 函数
map 也可以分配给特殊功能,这些以自定义方式存储和打印数据。
count(): 计数事件,在打印时将打印计数。 这使用了per-CPU map,@x成为类型计数的特殊对象
$ bpftrace -e 'tracepoint:block:* @[probe] = count(); '
Attaching 18 probes...
^C
@[tracepoint:block:block_rq_issue]: 1
@[tracepoint:block:block_rq_insert]: 1
@[tracepoint:block:block_dirty_buffer]: 24
[...]
// 使用interval 探针, 可以打印每个间隔的速率
$ bpftrace -e 'tracepoint:block:block_rq_i* @[probe] = count();
interval:s:1 print(@); clear(@); '
Attaching 3 probes...
@[tracepoint:block:block_rq_issue]: 1
@[tracepoint:block:block_rq_insert]: 1
@[tracepoint:block:block_rq_insert]: 6
@[tracepoint:block:block_rq_issue]: 8
[...]
sum(), avg(), min(), max(): 存储基本统计信息
@y = sum($x);
hist(int n): 将$x存储在
2
n
2^n
2n的直方图中,并且在打印时将打印存储区计数和ASCII直方图
$ bpftrace -e 'tracepoint:syscalls:sys_exit_read @ret = hist(args->ret); '
Attaching 1 probe...
^C
@ret:
(..., 0) 237 |@@@@@@@@@@@@@@ |
[0] 13 | |
[1] 859 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[2, 4) 57 |@@@ |
[4, 8) 5 | |
[...]
lhist(int n, int min, int max, int step): 这会将值存储为线性直方图
$ bpftrace -e 'tracepoint:syscalls:sys_exit_read @ret = lhist(args->ret, 0, 1000, 100); '
Attaching 1 probe...
^C
@ret:
(..., 0) 101 |@@@ |
[0, 100) 1569 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[100, 200) 5 | |
[200, 300) 0 | |
[...]
delete(): 从@start map中删除键是 tid 的键/值对
delete(@start[tid]);
clear(), zero(): 清空和置0
clear(@map)
zero(@map)
3. 示例
Timing vfs_read(): 该程序vfsread.bt,测量vfs_read()内核函数中的时间,并将时间打印为直方图(以微秒为单位)
程序一直运行到输入Ctrl-C ,然后打印此输出并终止。 该直方图被命名为"us",因为它可以打印输出名称,因此可以在输出中包含单位,给map赋予有意义的名称
#!/usr/local/bin/bpftrace
// this program times vfs_read()
// 通过使用kprobe检测其开始并将时间戳记存储在以线程ID为键的@start map中
kprobe:vfs_read
@start[tid] = nsecs;
// 使用kretprobe检测其结束并计算增量为vfs_read()内核函数的持续时间. 使用过滤器来确保记录了开始时间
kretprobe:vfs_read
/@start[tid]/
$duration_us = (nsecs - @start[tid]) / 1000;
@us = hist($duration_us);
delete(@start[tid]);
此脚本可以根据需要进行自定义. 这说明了bpftrace最有用的功能之一。 使用传统的系统工具(如iostat和vmstat),输出是固定的,无法轻松自定义。 但是用bpftrace,您可以将看到的指标进一步细分为多个部分,并通过其他探针的指标进行增强,直到获得所需的答案为止
@us[pid, comm] = hist($duration_us);
// output
@us[1847, gdbus]:
[1] 2 |@@@@@@@@@@ |
[2, 4) 10 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[4, 8) 10 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
@us[1630, ibus-daemon]:
[2, 4) 9 |@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[4, 8) 17 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[...]
五、Probe类型
1. tracepoint - 内核静态插桩
a. 格式
tracepoint_name是跟踪点的全名,包括冒号,它将冒号分隔成自己的类和事件名称的层次结构,例如net:netif_rx
tracepoint:tracepoint_name
b. 参数
跟踪点提供可通过内置args在bpftrace中访问的信息字段。
例如,net:netif_rx有一个称为len的字段,表示可以使用args -> len访问的数据包长度
如果您不熟悉bpftrace和跟踪,则系统调用跟踪点是很好的检测目标。 它们提供了广泛的内核资源使用范围,并具有文档齐全的API。例如: 检测read系统调用的开始和结束
syscalls:sys_enter_read
syscalls:sys_exit_read
对于sys_enter_read跟踪点, 可以使用 -l and -v 查看详情. 如下所示, 其参数应为args-> fd等
$ bpftrace -lv tracepoint:syscalls:sys_enter_read
tracepoint:syscalls:sys_enter_read
int __syscall_nr;
unsigned int fd;
char * buf;
size_t count;
使用示例:
$ bpftrace -e 'tracepoint:syscalls:sys_enter_read
printf("-> count() by %s PID %d\\n", comm, pid);
tracepoint:syscalls:sys_exit_read
printf("<- count() return %d, %s PID %d\\n", args->ret, comm, pid); '
2. usdt - 用户级静态插桩
a. 格式
usdt可以通过提供完整路径来检测可执行binaries或shared库。 probe_name是binary中的USDT探针名称
usdt:binary_path:probe_name
usdt:library_path:probe_name
usdt:binary_path:probe_namespace:probe_name
usdt:library_path:probe_namespace:probe_name
在不指定探针namespace的情况下,它的默认名称与binary或库的名称相同。 如果它有许多不同的探针,则必须有namespace。 一个示例是libjvm(JVM库)中的hotspot namespace 探针。 例如(完整库路径被截断)
usdt:/.../libjvm.so:hotspot:method__entry
b. 参数
USDT探针的任何参数都可以作为内置args的成员使用,可以使用-l列出binary中的可用探针
$ bpftrace -l 'usdt:/usr/local/cpython/python'
usdt:/usr/local/cpython/python:line
usdt:/usr/local/cpython/python:function__entry
[...]
3. kprobe, kretprobe - 内核动态插桩
a. 格式
kprobe表示函数的开始(入口),而kretprobe表示函数的结束(返回). function_name是内核函数名称。 例如,可以使用kprobe:vfs_read和kretprobe:vfs_read来检测vfs_read()内核函数。
kprobe:function_name
kretprobe:function_name
b. 参数
kprobe的参数: arg0, arg1, …, argN是函数的输入参数,为uint64。 如果它们是C结构的指针,则可以将它们强制转换为该struct.
kretprobe的参数:retval内置函数具有该函数的返回值。 retval始终是uint64; 如果这与该函数的返回类型不匹配,则需要将其强制转换为该类型。
c. 示例
例如,使用kretprobe将vfs_read()返回值(字节或错误值)汇总为直方图
$ bpftrace -e 'kretprobe:vfs_read @bytes = hist(retval); '
4. uprobe, uretprobe - 用户级动态插桩
a. 格式
uprobe表示函数的开始(入口),而uretprobe表示函数的结束(返回)
uprobe:binary_path:function_name
uprobe:library_path:function_name
uretprobe:binary_path:function_name
uretprobe:library_path:function_name
b. 参数
uprobe的参数: arg0, arg1, …, argN是函数的输入参数,为uint64。 如果它们是C结构的指针,则可以将它们强制转换为该struct.
uretprobe的参数: retval内置函数具有该函数的返回值。 retval始终是uint64; 如果这与该函数的返回类型不匹配,则需要将其强制转换为该类型
5. software, hardware
这些是预定义的软件和硬件事件
a. 格式
software:event_name:count
software:event_name:
hardware:event_name:count
hardware:event_name:
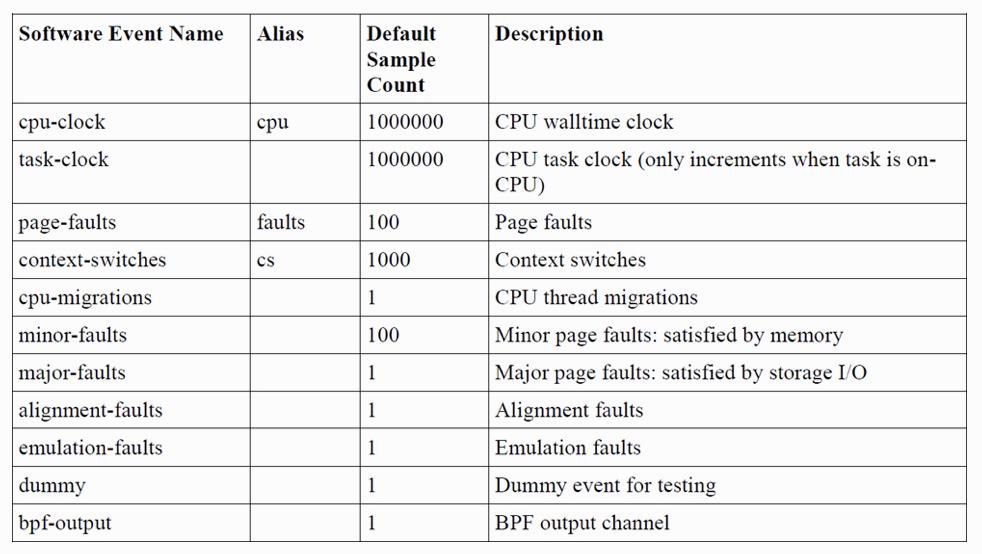
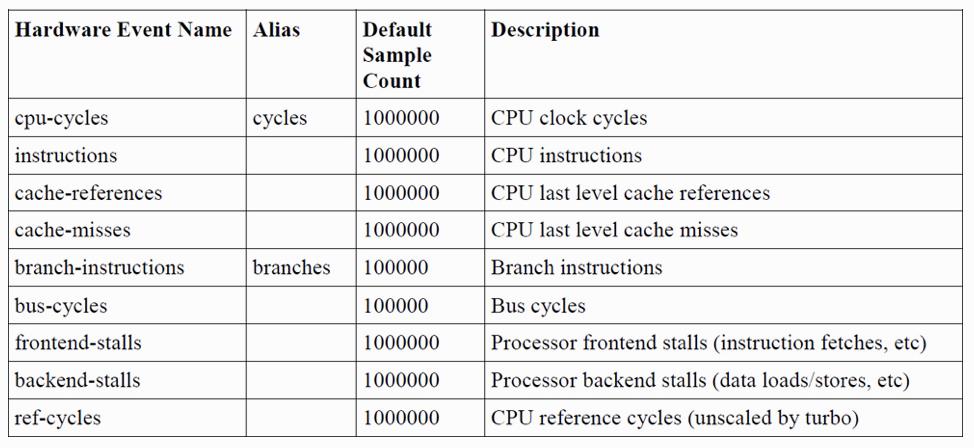
软件事件类似于跟踪点,但适用于基于计数的指标和基于样本的检测。 硬件事件是用于处理器级分析的PMC的选择。两种事件类型都可能发生得如此频繁,以至于对每个事件进行检测都会产生大量开销,从而降低系统性能。 通过使用采样和计数字段可以避免这种情况,该字段会触发探针在每个[count]个事件中触发一次。 如果未提供计数,则使用默认值
b. 可用的事件
软件
硬件
6. profile, interval
这些是基于计时器的事件
a. 格式
profile 文件类型会在所有CPU上触发,并且可用于采样CPU使用率。 interval 类型仅在一个CPU上触发,可用于打印基于间隔的输出
profile:hz:rate
profile:s:rate
profile:ms:rate
profile:us:rate
interval:s:rate
interval:ms:rate
六、Operators
1. 运算符
=, +, -, *, /, ++, --, &, |, ^, !
// 左移,右移
<<, >>
// 比较
+=, -=, *=, /=, %=, &=, ^=, <<=, >>=
2. 三元运算符
test ? true_statement : false_statement
示例: 计算绝对值
$abs = $x >= 0 ? $x : - $x;
3. IF
当前不支持else if语句。
if (test) true_statements
if (test) true_statements else false_statements
示例: 在IPv4和IPv6上执行不同动作的程序
if ($inet_family == $AF_INET)
// IPv4
...
else
// IPv6
...
4. Unrolled 循环
BPF在受限的环境中运行,在该环境中必须能够验证程序是否已结束,并且不会陷入无限循环中。 对于需要某些循环功能的程序,bpftrace通过unroll()支持展开循环.
unroll (count) statements
count是一个整数常量,最大为20。不支持将计数作为变量提供,因为必须在BPF编译阶段知道循环迭代的次数
以上是关于LinuxBPF学习笔记 - bpftrace开发[7]的主要内容,如果未能解决你的问题,请参考以下文章