openresty 使用 log_by_lua 发送日志到 syslog-ng
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了openresty 使用 log_by_lua 发送日志到 syslog-ng相关的知识,希望对你有一定的参考价值。
参考技术A 1. 安装opmgetp0pr0ck5/lua-resty-logger-socket
2. 使用
location lua_by_lua_block
log_by_lua_block
local logger = require "resty.logger.socket"
ngx.log(ngx.ERR, "Test Syslog: ", "call")
if not logger.initted() then
local ok, err = logger.init
host="syslog-ng-host",
port=514,
sock_type="udp",
flush_limit = 1,
--drop_limit = 5678
if not ok then
ngx.log(ngx.ERR, "failed to initialize the logger: ", err)
return
end
end
-- construct the custom access log message in
-- the Lua variable "msg"
local url = ngx.var.uri
local method = ngx.req.get_method()
local headers = ngx.req.raw_header(true)
-- tbl
local params_var = ngx.req.get_uri_args()
local client_ip = ngx.var.remote_addr
-- tbl
local user_agent = ngx.req.get_headers()["User-Agent"]
local referer = ngx.req.get_headers()["Referer"] or ""
local cookies = ngx.req.get_headers()["Cookie"]
local bytes, err = logger.log("test")
local bytes, err = logger.log(client_ip.." "..table.concat(params_var).." "..user_agent.." "..referer.." "..cookies.." "..url.." "..method)
if err then
ngx.log(ngx.ERR, "failed to log message: ", err)
return
end
3. log server
syslog-ng 其中启用 udp server 同时可以安装对应的后端storage
yum install-y syslog-ng
4. log 查询
syslog-ng server
tail - f /var/log/message
5. 参考资料
https://syslog-ng.org/
https://github.com/cloudflare/lua-resty-logger-socket
尹吉峰:使用 OpenResty 搭建高性能 Web 应用

2019 年 8 月 31 日,OpenResty 社区联合又拍云,举办 OpenResty × Open Talk 全国巡回沙龙·成都站,原贝壳找房基础架构部工程师尹吉峰在活动上做了《使用 OpenResty 搭建高性能 Web 应用 》的分享。
OpenResty x Open Talk 全国巡回沙龙是由 OpenResty 社区、又拍云发起,邀请业内资深的 OpenResty 技术专家,分享 OpenResty 实战经验,增进 OpenResty 使用者的交流与学习,推动 OpenResty 开源项目的发展。

尹吉峰,原贝壳找房基础架构部工程师,多语言爱好者,偏向异步和函数式编程,酷爱原型搭建,先后在贝壳使用 OpenResty 搭建了 WebBeacon、图片处理等服务。
以下是分享全文:
今天和大家介绍一个 OpenResty 比较小众的使用场景,使用 OpenResty 做 Web 框架写服务,希望能给大家带来一些新的东西。
为什么要做高性能服务
首先给高性能 Web 服务一个简单定义:QPS 过万的服务是高性能 Web 服务。我认为一个好服务绝对不是优化出来的,架构决定一个服务的基准,过早优化是万恶之源。
大家都知道如果做 Web,Web 只需要水平伸缩、扩展就行,那么为什么还要高性能呢?事实上有些服务是不适合水平伸缩的,比如有状态的服务。我盘点了过去几年使用过的服务,发现有状态的数据库服务的确很多:
统一集中式的缓存 Redis
高性能的队列 Kafka
传统的关系型数据库 MySQL、Postgres
新兴的非关系型数据库 MongoDB、Elasticsearch
Embedded 数据库,属于内嵌数据库,跟服务配置在一起的 SQLite3、H2、Boltdb
最新的时序数据库 InfluxDB、Prometheus 等
上面这些服务实际上都是有状态的,它的扩容、伸缩不是那么简单,一般是以 Sharding 的方式通过人工操作手动做伸缩。
而基础服务和平台服务是整个公司的服务所依赖的,一家公司的服务可能有成千上百台机器,但是基础服务应该只占很小的比例,所以我们对基础的通用服务有高性能需求,比如 Gateway 网关、Logging、Tracing等监控系统,以及公司级别的用户的 API、Session/Token校验,这类服务对性能有一定要求。
此外,水平扩展是有限度的,随着机器的增多,机器提供的容量、QPS 不是一个线性增长的过程。
高性能的好处,我认为有以下几个方面:
成本低,运维简单:伸缩容不敏感,一台机器可以扛多台机器的量;
便于流量分发:机器少可以便于流量分发,部署快意味着回滚快;面对完全不兼容,或者对极度的流量平滑迁移有需求的情况会用到红绿部署;
简化设计:应用内的缓存会更高效,按机器纬度可以做一些简单的 ABTest;
“程序员的自我修养”。
如何做高性能服务
绝大部分Web 应用实际上都是 IO 密集型服务,而非 CPU 的密集型服务。对 CPU 的性能,大家可能没有一个直观感受,这里给大家举个例子:π 秒约等于一个纳世纪,说的是人在观察世界的时候是以秒级的尺度。而 CPU 的是纳秒级别的尺度。对于 CPU 来说,3.14 秒相当于人类的一个世纪这么漫长,1 秒就相当于 CPU 的“33 年”。如果是 1-2个毫秒,我们觉得很快,但对于 CPU 实际上是它的“20 天左右”。
而这仅仅是单核,实际上还有多核的加持。面对这么强的 CPU 性能,怎么充分利用呢?这就有了 2000 年以来的新型编程模式:异步模型,也叫事件驱动模型。异步编程、事件驱动,是把阻塞的、慢的 IO 操作转化成了快的 CPU 操作,用通过 CPU 完全无阻塞的事件通知机制来驱动整个应用。
我自2012 年在手机搜狐网接触 Python Tornado 异步编程以来,用过多个语言和框架做异步编程。我认为同步模型就是“线程池+频繁的上下文切换+线程之间数据同步的大锁”,这意味着如果是同步模型,需要根据当前的 loading 去做系统的调优,根据目前的各个状况,一点一滴去做,实际上调优难度是非常大的。
而异步模型相当于一个高并发的状态,因为它是EventLoop,是在不停循环的。同时有两个请求过来,它可能同时会触发,如果其中一个请求操作 CPU 没有及时让出,就会影响另一个请求。它用潜在的时延换来更高的并发。高性能就相当于“异步+缓存”,即异步解决 IO 密集、缓存解决 CPU 密集的问题。
目前市面上主流的异步语言和框架包含:
C 和 C++,一般不会拿来写 Web 应用;
PHP(swoole),这个生态相对来说没有那么好;
Java,近些年借助 Spring Cloud、Gateway 又火了一把,但还是一个比较初级的状态,还是在那种 then/onError 结合子的状况下面去编程;
NodeJS,谈异步肯定离不开 JS 和 NodeJS,JS 生态是异步的生态,它没有同步的阻塞。从开始设计到现在,经过这么多年发展,从最开始回调,逐渐演化成为 Promise 类库的加持,再到 NodeJS 的 async/await、IO 这类方便用 generate 写异步代码的状态,async/await 的模型也是当前整个业界比较认可和推崇的写异步的方式;
Python,Python 经历了从最开始的 yield 做 generate,到 yield+send 做成协程的状态,再到 yield+from 加 generate 做流式的处理,到现在 3.x 版本的 asyncio 纳入官方库的过程;
Rust,Rust 是种新兴语言,它基于内存模型的特殊,选择了 pull 模型做异步的执行。它是在 1.39.0 的时候即今年 9 月份,async/await 这种模式才是一个 stable 的状态,一个async/await 的 MVP 最小可用的产品,而 tokio 作为官方 de-facto 的 runtime 是在 3-6 个月稳定,所以 2020 年上半年可能可以看到一波用 Rust 去写 Web 程序的浪潮;
Golang,是用 Goroutine 去做切换,不同于其他,它看起来是一个同步代码,实际上是在后面的 runtime 做异步调度的形式。
那为什么还要学 OpenResty 呢?这里首先是限定在 2015 年,今天要讲的实践大约是在 2015-2016 年做的,可能时间上没有这么新了。但在 2015 年,上述这些异步除了 JS,其他的成熟度没有那么高,所以 在当时 OpenResty 的确是很好的做异步的框架。
什么是 OpenResty
Nginx
Nginx 是一流的反向代理服务器,它有完善的异步开源生态,且在一线互联网公司已经成为标配,是已经引入的技术栈。因此在 OpenResty 基础上再引入一些东西是风险极低的事情,只是引进来一个 Module,就可以复用已有的学习成本。
此外,Nginx有天然的架构设计:
Event Driving
Master-Worker Model
URL Router,不用再选路由库,本身在 config 里就很高效
Processing Phases,关于对请求的处理流程这一点只有在使用 OpenResty 后才能感受到
Lua
Lua 是一个小巧灵活的编程语言,天生和 C 亲和,支持 Coroutine。除此之外它还有一个很高效的 LuaJIT 实现,提供了一个性能很好、很高的 FFI 接口,根据 Benchmark 这种方式比手写C 代码调 C 函数还要快。
OpenResty
OpenResty 是Nginx+Lua(JIT),它是两者完美的有机结合,把异步的Nginx 生态用 Lua 去驱动。Lua 本身不是一个异步生态,这里提一下春哥为什么要去做 OPM 和包管理,其实是因为 luarocks 是同步的生态,所以 OpenResty 很多包都是 lua-resty 开头的,表明它是异步的,能在 OpenResty 上使用。
OpenResty 应用实践:WebBeacon
WebBeacon 概述
Beacon 是一个埋点的服务,记录 http 请求,做后续的数据分析,从而计算出会话数量、访问时长、跳出率等一系列的数据。
dig.lianjia.com 是WebBeacon 服务的前端,它负责支持数据的搜集,不负责数据的处理和计算。它还负责接收 http 请求,返回 1×1 的 gif 图片;接收到了 http 请求后,会有一个内部的格式称作为 UAL(Universal Access Logging),这是统一全局的访问日志格式,把http 请求相关的信息落地推到 Kafka,就可以做实时或者离线的数据统计,这就是整个服务的概况。
我们接手时已经有一个版本,第一个版本是用 PHP 实现的,性能不是很好。它是 FastCGI + PHP Logging to file 直接接收到请求,PHP 写到文件里,再由 rsyslog imfile,file 的 input module 去读取日志文件,通过 Kafka 的 output module 去推到 Kafka 的一个状况。
举个例子,为什么 PHP 性能不高呢?根据 PHP 的请求模型,为了防止内存泄漏,你是不需要关注资源释放的。每个请求开始时打开日志文件,然后写入日志,请求结束时自动关闭,只要不是在 Extension 里初始化都会重复这个过程。在这个项目中,每次打开和关闭只是为了写一条日志进去,这就会使性能变得很差。
面临的挑战
重要程度很高,很长一段时间,整个链家网的大数据部门唯一生产资料就是源于此服务,如果没有这个服务,就没有后面所有数据统计计算和报表的输出,对于下游的依赖方,这个服务重要度相当高。
高吞吐状态,所有的 PC 站、M 站、安卓、iOS、小程序甚至内网服务都可以往这个服务上打,所以对吞吐有一个非常高的要求。
这个服务有业务,它要去到不同的地方取信息,再做一些转换,最后落地,肯定需要有一个灵活的编程的东西可以搞定它。
资源隔离性差,当时链家网的整个服务是一个混合部署的状态,只靠操作系统的隔离性在维持,所以会出现多个服务跑在同一台机器上的情况,对 CPU、内存、磁盘等有争用的状态。
坚持的原则
性能 Max,性能越高越好;
避免对磁盘的(硬)依赖,因为混合部署的原因,希望它能够在关键路径上甚至从头到尾能够避免对磁盘的依赖;
即刻响应用户,一个 WebBeacon 的服务,实际上核心是落数据,用户可以直接响应,不需要等,落数据可以放在后台做,不需要卡着用户的请求。我们希望有一个机制,能够拿到请求,直接返回一个请求,后面再做业务重的部分;
重构成本尽可能低,这个项目已经有第一版了,虽然是重构,但相当于重写了一版。我们希望它能在这个过程中耗时越短越好,在原有的基础上能够继承下来所有的功能点,同时有自己新的特点。
主体逻辑
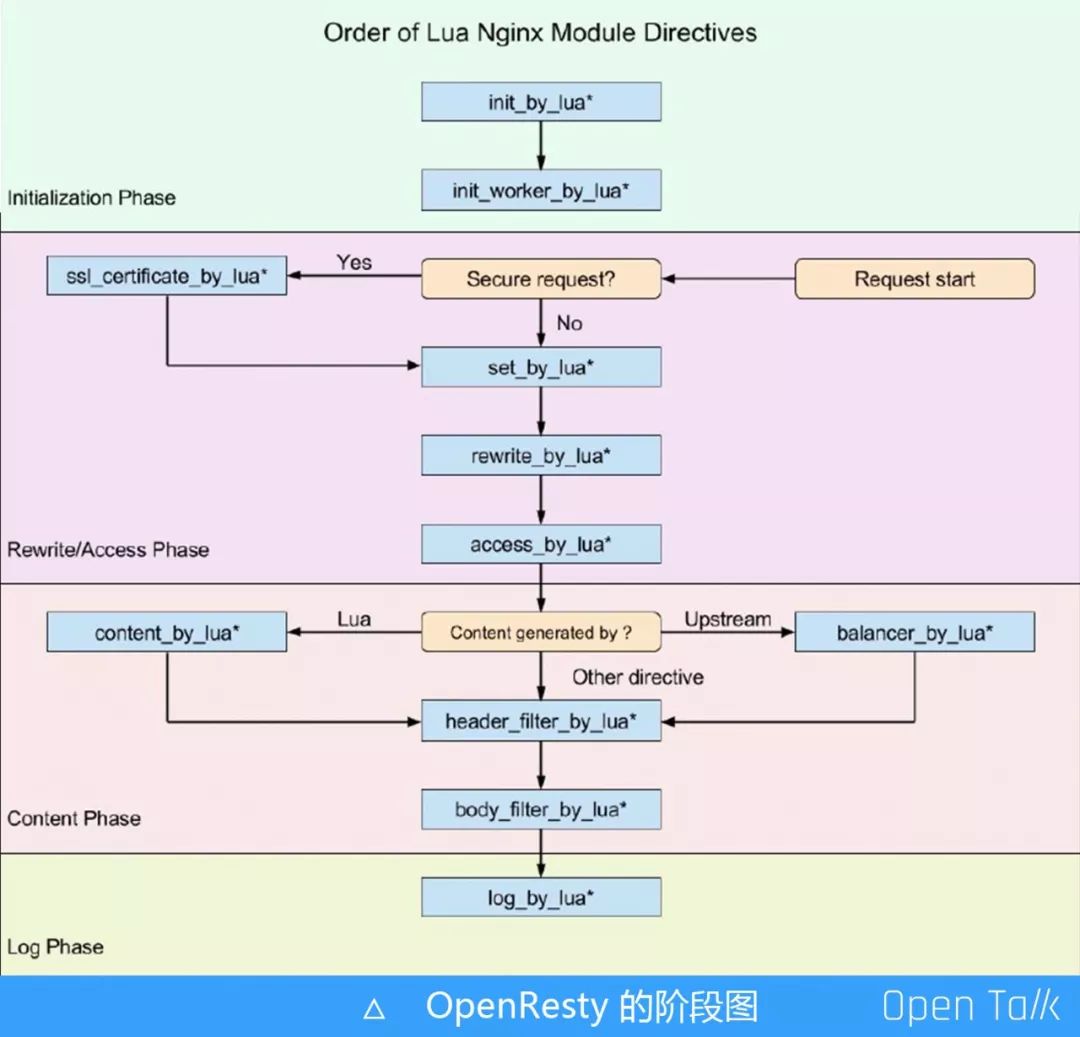
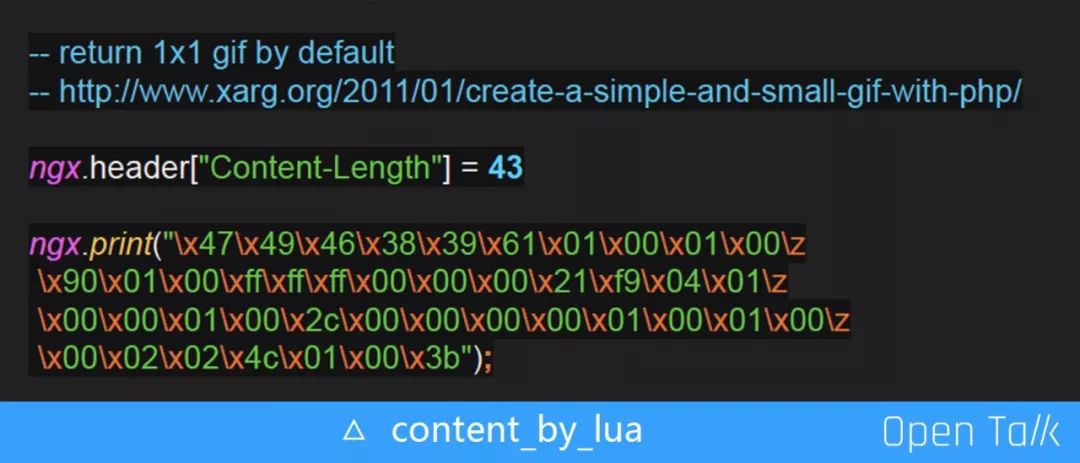
如上图,声明 Content-Length=43,如果不声明则默认是Chunked 模式在我们的场景里是没有意义的;\z 是 Lua5.2 Multiline String 的一种写法,它会把当前的换行和后面的空白字符全部截取掉,然后拼回去。
access_by_lua
我们在 access_by_lua 的过程中做了几件事情:
首先是解析 cookie,要去记录和下发一些 cookie,我们使用 cloudflare/lua-resty-cookie 的包去解析 cookie。
然后生成uuid 去标识设备 ID 或者请求 ID 等一系列这种随机的状态,我们用了 openssl 的 C.RAND_bytes,随机生成了 16 个 bytes、128 bit,然后用 C.ngx_hex_dump 转化,再一点一点切成 uuid 的状态。因为我们内部大量使用 uuid 的生成,所以这块希望它的性能越高越好。
除了uuid 还有 ssid,ssid 是 session ID,session 是记录会话的数量。在 WebBeacon 里,会话是指用户在 30 分钟内连续地访问。如果一个用户在 30 分钟内持续访问我们的服务,则认为它是一个会话的状态;超 30 分钟 cookie 过期了,会重新生成一个新的 cookie,即是一个新的会话。此外,这里的统计是不跨自然天的,比如晚上 11:40 分,一个用户进来,会只给他20 分钟的 cookie,从而保证不跨自然天。
除了以上这些,我们还有一个最重的业务逻辑。
手机端浏览器每次发请求都会有成本,我们做了设定,将手机端搜集的日志打包一起上传,把多条的埋点日志汇总,当用户按 home 键退出或放到后台时触发上报流程,以 POST 的形式去上报,POST 时同时做编码,加上 GZIP,它的流量损耗会很低。这意味着我们要去解析 body,去把一条上报上来的 POST 请求拆成 N 条不一样的埋点日志再落地。为此我们做了以下的事情:
限定 Max body,因为不希望落磁盘,所以设置了 64K 的大小。考虑到我们有 GZip,可能之前有 400k-500k 的状态,汇总搜集后应该是足够使用了;
客户端编码,服务端自然要去解码。通过 zlib 去解 Gzip,然后 decode URL,再做 json_decode,终于把一个请求拆成了 N 个,一个 list 下面包含 N 个请求的状况,把每一个 list item 重新编码成埋点日志再落回去;
用 table new,table.new(#list,0)->table.new(0,30)/table.clear,然后做 json_encode、ngx.escape_url 等操作,最后形成单条的日志;
假设在这个过程中出现任何问题就会做降级,用 log_escape 把一个 raw body 落到了日志里面,这样后期还是有能力去做找回。
header(body)_filter_by_lua
还有一个逻辑是搜集、汇总字段的过程。
为什么不在 access_by_lua 的时候一起做了?原因是我们在压测时发现在高并发压力的情况下,某个操作在 access_by_lua 阶段会发生 coredump。也有可能是我们用的方式不对,本身就不应该用在 access_by_lua 段,这块儿没有深究。
所以我们把一部分过滤阶段与当前请求没有太大关系的业务挪到了header_filter_by_lua 的过程中,我们有解X-Forwarded-For 去落 IP,有解lianjia_token 去落 ucid,链家里的 ucid是一个长串的数字。Lua 里面的数字有 51 位的精度,这意味着这块数字没办法落下来,于是我们使用 FFI 去 new 一个 64 位的 URL 的 number,并做一系列的变换,再通过打印截取的方式落出来想要的 20 多位的 ucid 的长度。
log_by_lua 备选方案
下面介绍最核心的一环即 log_by_lua 落日志的过程。
access_log 是 Nginx 原生内置的方式,这种方式不适用我们的场景,因为我们有 TB 级别的日志量,并且是混合部署,所以磁盘是争用的状态;最核心的一点是 Read 和 Write 是阻塞的操作系统调用,这会让它的性能急剧下降;
张德江写的 doujiang24/lua-resty-kafka 是另一个方式,这个其实我们并没有做调研,因为 kafka 的协议和特性太多太繁杂,这个方案当前特性和后续发展可能没法满足我们的需求。
我们最后选定了 cloudflare/lua-resty-looger-socket 的库,可以远程非阻塞地落日志。
rsyslog
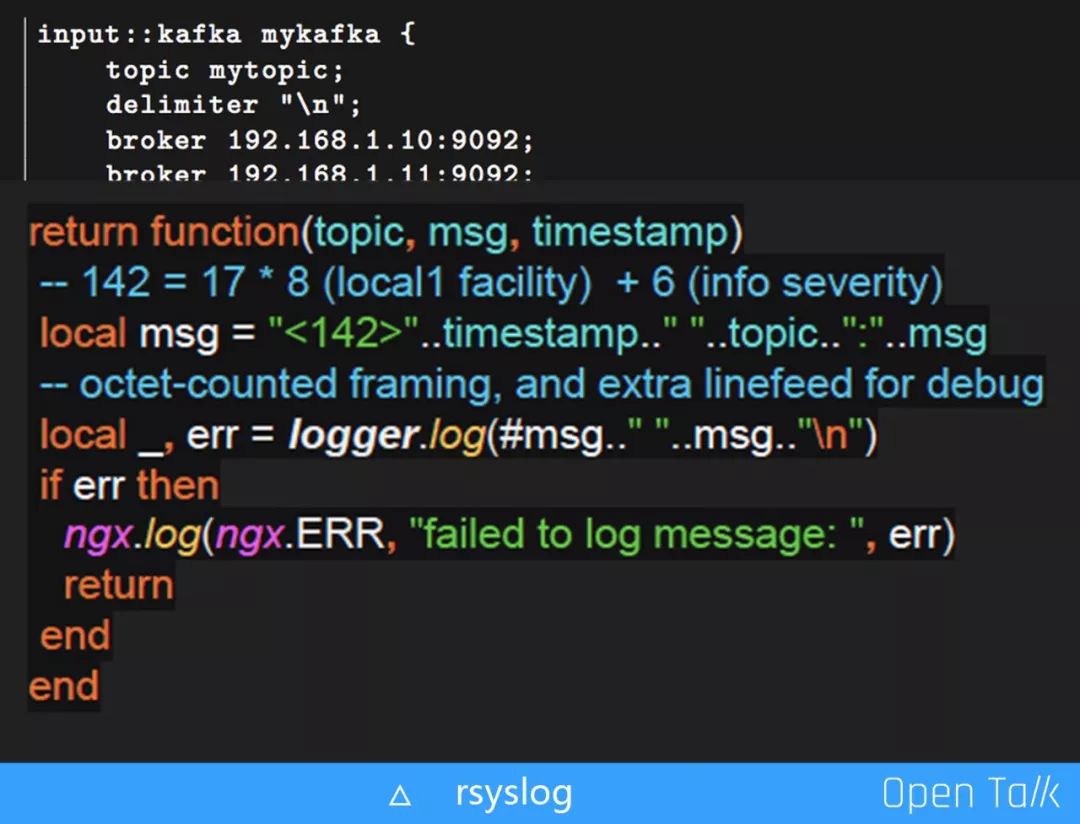
落日志的工具我们选择 rsyslog,实际上并没有做太多的技术选型,直接在原来的技术选型上做了定制和优化:
单条日志最大长度是 8k,超长的单条日志它会截断,这是 rsyslog 里面的规范,但是在它里面也可以做定制;
rsyslog 内部通过 Queue 传递消息,内部 Queue 用得非常重。我们选取了 Disk-Assisted Memory,它能在 Memory 爆掉时落地到磁盘做降级,保证它的可靠程度;
Parser 没有用新版本的 RFC,而是选用老版本的 RFC3164,是很简单的一个协议,如上图, local msg="<142>"..timestamp..""..topic..":"..msg 就是 RFC3164 的规范日志;
我们有一条日志落多条的需求,日志和日志之间要做切割,这里其实开启了 SupportOctetCountedFraming 的参数做切割,实际上就是在当前的 message 的头上再加上 message 的长度,通过一个基础的 RFC,加上额外的功能特性完成整个日志的落地;
用 imptcp 去建立 unix socket 的文件句柄,没有用 TCP、UDP,因为 unix socket 的损耗会更低。值得注意的是,cloudflare/lua-resty-looger-socket 的库不支持 dgram unix socket,目前 cloudflare 已经停止维护这个库了;
输出用了 omkafka 的 output module,开启了两个特殊的操作 :开启 dynaTopic 可以定制录入到制定 topic;开启 snappy 的压缩可以减轻传输流量;
额外开启两个 module:一个是 omfile,它接到 imptcp 传过来请求,在推 kafka 的同时落地到本地,这么做的原因是之前下游推送程序宕机导致 kafka 里的消息没有及时被拿走而造成数据的丢失,因此需要做重要数据的备份,再加上磁盘的依赖;另一个是 impstats,它是做监控,输出 Queue 容量、当前的消费状况等一系列数据。
部署方案
前面提到我们是混合部署的状况,线上会有准入的标准:tar 包+`run.sh`。我们预先编译好 OpenResty,把所有依赖静态地编译进去,在发布时把 OpenResty 的二进制文件拉到本地和 Lua 脚本混在一起,rsync 到固定的位置上再跑起来,使用 supervisord 或者 systemctl 做线上的daemon管理。
测试环境是自我维护的,这个项目可以分成两块,一块是 OpenResty,另一块是 rsyslog。可能你会把 OpenResty 的所有代码落到代码仓库,而忽略了实际上 rsyslog 的配置也是相当重要,所以其实应该把所有的项目相关的东西都落到代码仓库里。我们通过 Ansible 去做剩下的所有事情来管理测试环境。
性能数据
最终的性能数据如下图:
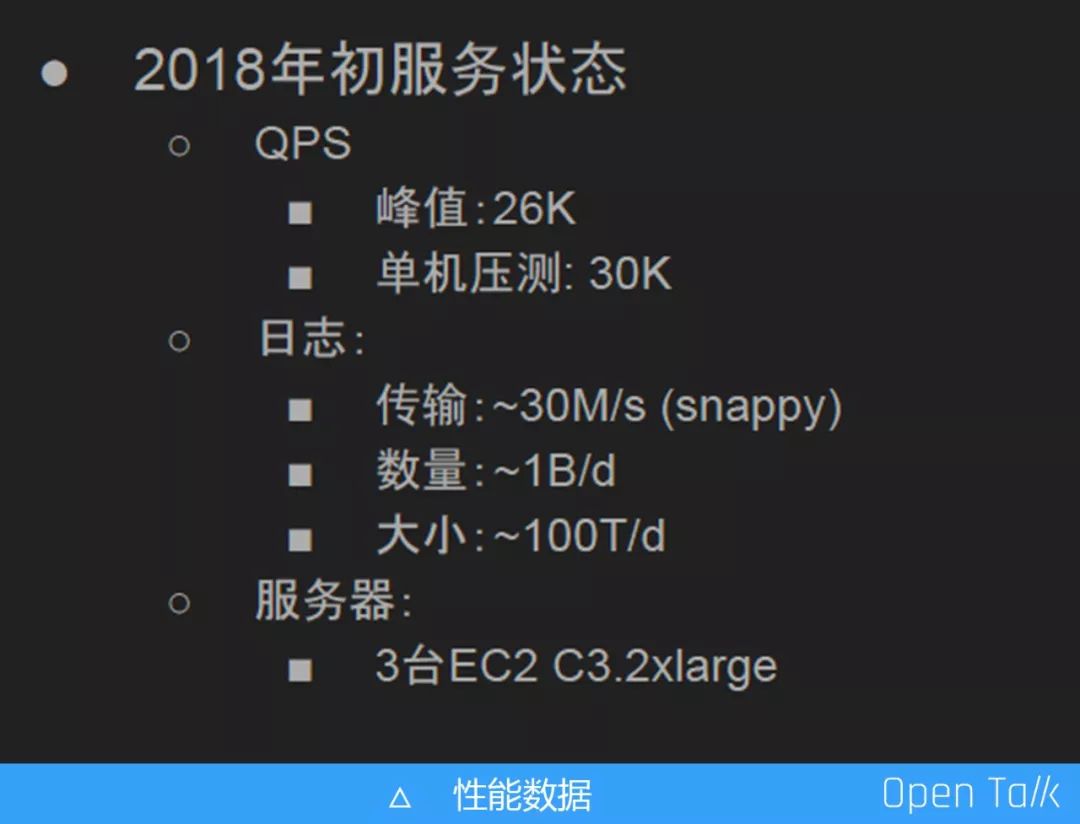
2018 年初我做了统计,QPS 峰值大概是 26000QPS,单机压测的峰值在 30000QPS,所以其实一台 OpenResty 的机器可以抗住整个埋点的流量。日志传输压缩之后大概有 30M,每天的日志落起来大概在 10 亿条左右。为了保证服务的可靠性,当时线上的服务器是三台 EC2 C3.2xlarg。
总结
总的来说,架构是第一位的,我们使用 OpenResty+rsyslog+Kafka 三款久经考验的组件构建出一个高性能的服务;
要保持边界,守住底线,比如不落磁盘,就要想尽一切办法不落磁盘,保证有极致的性能;
有时候你看起来很高性能,但是代码写起来还是会有很多坑,你可以通过火焰图等很多方式来避免。重要的是,你需要有意识地去把握性能的问题,从一点一滴的小事情做起。比如 NYI 的 not yet implement 方法要避免去使用;比如 table.new/table clear一次性预分配已知大小 table array 的操作,都要避免重复的、多次的动态扩充;ngx.now 的实现性能非常高,它是有缓存的,基本满足对时间精度的要求;uuid 的生成,从 libuuid 转换成一次性生成 16 字节数据;通过 shared dict 之类的减少 CPU 的操作等等,最后我们可以构建出一个高性能的 Web 服务。
以上是我今天的全部分享,谢谢大家!
快 来 找 又 小 拍

推 荐 阅 读
以上是关于openresty 使用 log_by_lua 发送日志到 syslog-ng的主要内容,如果未能解决你的问题,请参考以下文章
历时两年半,锤子科技给 OpenResty 的捐款终于到账了