关于网页数据抓取HXR,python写法,这个post的data要如何写?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于网页数据抓取HXR,python写法,这个post的data要如何写?相关的知识,希望对你有一定的参考价值。
我试图获取TopAccess打印机的total打印纸张数,请大神帮忙看下这个要怎么获取,谢谢
在 Python 中进行网页数据抓取时,如果需要发送 POST 请求,需要将需要提交的数据写在 post 的 data 字段中。具体写法如下:
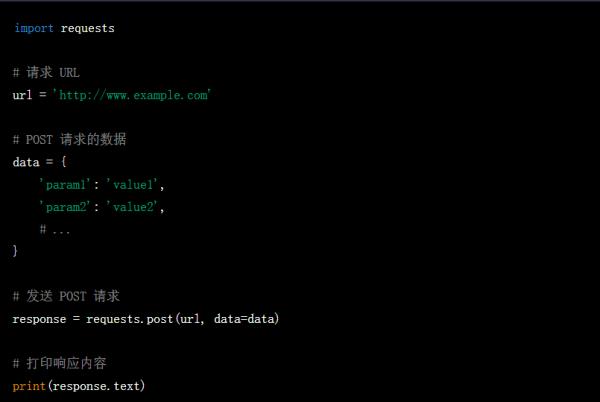
其中,data 参数的值是一个字典类型,里面包含需要提交的数据。根据实际需要修改参数名和参数值即可。
参考技术A你是说模拟数据包吗?
数据包模拟可以使用 requests 模块。格式如下图所示。如果再看不明白自己搜索 requests 的一般使用方式看看。

数据包发送后收到 response 数据包的解析部分大多数可以用 lxml 模块解析,使用的是 xpath。使用正则表达式提取也是可以的。
```python
import requests
# 目标 URL
url = 'https://example.com/api/submit'
# 要发送的数据
data =
'name': 'John Doe',
'email': 'johndoe@example.com',
'message': 'Hello, world!'
# 提交 POST 请求
response = requests.post(url, data=data)
# 输出响应结果
print(response.text)
```
在上述代码中,我们首先指定了目标 URL,然后创建了一个包含要发送的数据的字典。接下来,使用 `requests.post()` 函数提交 POST 请求,并将响应结果保存在变量 `response` 中。最后,我们可以使用 `response.text` 属性来访问响应内容,并在控制台中输出它。
需要注意的是,POST 数据的格式可能因不同的应用程序而异。有些应用程序可能使用 JSON 格式来传输数据,有些则使用表单形式提交数据等。因此,在构造 POST 请求时,需要根据具体的应用程序要求来设置相应的请求头、数据格式等。 参考技术C import requests
# 定义要发送的数据
data =
"key1": "value1",
"key2": "value2"
# 发送带有数据的 POST 请求
response = requests.post("http://www.example.com", data=data)
# 处理响应
if response.status_code == 200:
print("POST 请求成功!")
else:
print("POST 请求失败!")
在上面的示例中,我们首先定义了要发送的数据,然后使用 requests.post 方法发送了带有数据的 POST 请求。最后,我们使用响应状态码判断 POST 请求是否成功。
请注意,上面的示例代码仅供参考
如何用Python爬虫抓取网页内容?
比如新浪,QQ等
爬虫流程其实把网络爬虫抽象开来看,它无外乎包含如下几个步骤
模拟请求网页。模拟浏览器,打开目标网站。
获取数据。打开网站之后,就可以自动化的获取我们所需要的网站数据。
保存数据。拿到数据之后,需要持久化到本地文件或者数据库等存储设备中。
那么我们该如何使用 Python 来编写自己的爬虫程序呢,在这里我要重点介绍一个 Python 库:Requests。
Requests 使用
Requests 库是 Python 中发起 HTTP 请求的库,使用非常方便简单。
模拟发送 HTTP 请求
发送 GET 请求
当我们用浏览器打开豆瓣首页时,其实发送的最原始的请求就是 GET 请求
import requests
res = requests.get('http://www.douban.com')
print(res)
print(type(res))
>>>
<Response [200]>
<class 'requests.models.Response'> 参考技术A
首先,你要安装requests和BeautifulSoup4,然后执行如下代码.
from bs4 import BeautifulSoup
iurl = 'http://news.sina.com.cn/c/nd/2017-08-03/doc-ifyitapp0128744.shtml'
res = requests.get(iurl)
res.encoding = 'utf-8'
#print(len(res.text))
soup = BeautifulSoup(res.text,'html.parser')
#标题
H1 = soup.select('#artibodyTitle')[0].text
#来源
time_source = soup.select('.time-source')[0].text
#来源
origin = soup.select('#artibody p')[0].text.strip()
#原标题
oriTitle = soup.select('#artibody p')[1].text.strip()
#内容
raw_content = soup.select('#artibody p')[2:19]
content = []
for paragraph in raw_content:
content.append(paragraph.text.strip())
'@'.join(content)
#责任编辑
ae = soup.select('.article-editor')[0].text
这样就可以了
以上是关于关于网页数据抓取HXR,python写法,这个post的data要如何写?的主要内容,如果未能解决你的问题,请参考以下文章