,如何判别,是java自带的类/方法还是用户自己编程得到的.在命名方法上是不是可以区分出来.
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了,如何判别,是java自带的类/方法还是用户自己编程得到的.在命名方法上是不是可以区分出来.相关的知识,希望对你有一定的参考价值。
,如何判别,是java自带的类/方法还是用户自己编程得到的.在命名方法上是否可以区分出来.
参考技术A 准确的说是无法区别的, 因为用户可以重写javaAPI中的方法,所以无法判断,但一般情况下,如果用户遵循包名的命名规范, 不与javaAPI中的 包名冲突, 则可以通过 类的全路径名 来判断是否是 javaAPI中的类 参考技术B 我觉得 你可以通过包+ 类 来区别 。 你自己定义的包 你因该认得呀其他的就是自带的了 哈哈哈
不太准确哈
靠经验了 呵呵 参考技术C 不行,一个是需要你自己的积累,然后就是参看java的api了。 参考技术D 这咋能完全准确的区分了。要是我刻意的使用和官方取名相似的命名方式咋办。
R语言如何进行线性判别分析?
判别分析是一种有监督的训练方法。对于线性判别,先是将样本点投影到一维空间,也就是直线上,若效果不明显,就可以考虑增加一个维度,变成二维空间,如果还是不明显,就继续增加维度。
在R语言中,MASS软件包中的lda()是实现线性判别的核心函数。下面将通过一个简单实例来进行介绍。
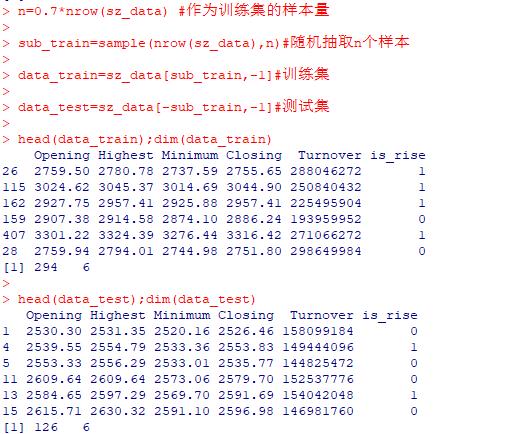
1 读取数据集。
sz_data=read.csv("sz_data.csv",head=T,encoding="utf-8")
head(sz_data);dim(sz_data) #查看数据的前几行和数据维度
2 进行数据预处理。在实际应用中,如果数据有缺失值,需要先按照一定的方法先对缺失值进行处理。这里我们直接划分训练集和测试集,并且随机抽取70%的样本作为训练集。
n=0.7*nrow(sz_data) #作为训练集的样本量
sub_train=sample(nrow(sz_data),n)#随机抽取n个样本
data_train=sz_data[sub_train,-1]#训练集
data_test=sz_data[-sub_train,-1]#测试集
head(data_train);dim(data_train)
head(data_test);dim(data_test)
3 线性判别分析。没有MASS安装包的要先安装MASS包。
fit_lda1=lda(is_rise~.,data_train) #判别分析公式
names(fit_lda1) #查看lda()可给出的输出项名称
fit_lda1$prior #查看本次执行过程中所使用的先验概率
fit_lda1$counts #查看数据集data_train中各类别的样本量
fit_lda1$means #查看各变量在每一类别中的均值
fit_lda1 #输出判别分析的各项结果
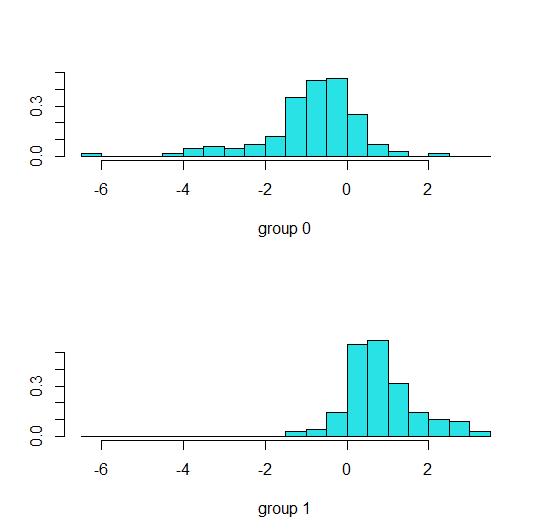
plot(fit_lda1) #判别规则可视
从运行结果可以看出,本次线性判别将样本点投射到了一维空间(LD1)。结果中展示了先验概率、各类别样本量,以及各变量在每一类别中的均值。
图形中展示了is_rise取值为0和1时,分布具有一定的差异性。

4 对测试集进行预测。
pre_lda1=predict(fit_lda1,data_test)
data_test$pre_rise=pre_lda1$class #输出类别预测结果
head(data_test) #查看含有预测结果的数据
5 验证模型准确性。
table(data_test$is_rise,pre_lda1$class) #生成is_rise的预测值和实际值的混淆矩阵
error_lda1=sum(pre_lda1$class!=data_test$is_rise)/nrow(data_test);error_lda1#计算错误率
混淆矩阵中,对角线上的数据是被准确判别了的。计算出的错误率在15%以下,具有较高的准确性。
以上是关于,如何判别,是java自带的类/方法还是用户自己编程得到的.在命名方法上是不是可以区分出来.的主要内容,如果未能解决你的问题,请参考以下文章