MySQL数据库复制后为何无法读取表中数据?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL数据库复制后为何无法读取表中数据?相关的知识,希望对你有一定的参考价值。
将其他机子上的一个mysql数据库复制到本机(data目录下),用show databases指令显示该数据库存在,用show tables指令显示该数据库中所有表均存在,但用select或desc指令读取表中数据则会提示该表不存在,问什么会有这种情况?
参考技术A如果从库上表 t 数据与主库不一致,导致复制错误,整个库的数据量很大,重做从库很慢,如何单独恢复这张表的数据?通常认为是不能修复单表数据的,因为涉及到各表状态不一致的问题。下面就列举备份单表恢复到从库会面临的问题以及解决办法:
场景 1
如果复制报错后,没有使用跳过错误、复制过滤等方法修复主从复制。主库数据一直在更新,从库数据停滞在报错状态(假设 GTID 为 aaaa:1-100)。
修复步骤:
在主库上备份表 t (假设备份快照 GTID 为 aaaa:1-10000);
恢复到从库;
启动复制。
这里的问题是复制起始位点是 aaaa:101,从库上表 t 的数据状态是领先其他表的。aaaa:101-10000 这些事务中只要有修改表 t 数据的事务,就会导致复制报错 ,比如主键冲突、记录不存在(而 aaaa:101 这个之前复制报错的事务必定是修改表 t 的事务)
解决办法:启动复制时跳过 aaaa:101-10000 这些事务中修改表 t 的事务。
正确的修复步骤:
1. 在主库上备份表 t (假设备份快照 GTID 为 aaaa:1-10000),恢复到从库;
2. 设置复制过滤,过滤表 t:
CHANGE REPLICATION FILTER REPLICATE_WILD_IGNORE_TABLE = ('db_name.t');3. 启动复制,回放到 aaaa:10000 时停止复制(此时从库上所有表的数据都在同一状态,是一致的);
START SLAVE UNTIL SQL_AFTER_GTIDS = 'aaaa:10000';4. 删除复制过滤,正常启动复制。
注意事项:这里要用 mysqldump --single-transaction --master-data=2,记录备份快照对应的 GTID
场景 2
如果复制报错后,使用跳过错误、复制过滤等办法修复了主从复制。主、从库数据一直在更新。
修复步骤:
在主库上备份表 t (假设备份快照 GTID为 aaaa:1-10000);
停止从库复制,GTID为 aaaa:1-20000;
恢复表 t 到从库;
启动复制。
这里的问题是复制起始位点是 aaaa:20001,aaaa:10000-20000 这些事务将不会在从库上回放,如果这里面有修改表 t 数据的事务,从库上将丢失这部分数据。
解决办法:从备份开始到启动复制,锁定表 t,保证 aaaa:10000-20000 中没有修改表 t 的事务。
正确修复步骤:
对表 t 加读锁;
在主库上备份表 t;
停止从库复制,恢复表 t;
启动复制;
解锁表 t。
如果是大表,这里可以用可传输表空间方式备份、恢复表,减少锁表时间。
那请问如何才能修改当前用户权限使其能查看数据库呢?我是初学者,求指教,谢谢。
本回答被提问者采纳MySQL索引为何选择B+树,干货整理
Redis主从复制
概念
Redis的主从复制概念和MySQL的主从复制大概类似。一台主机master,一台从机slaver。master主机数据更新后根据配置和策略,自动同步到slaver从机,Master以写为主,Slave以读为主。
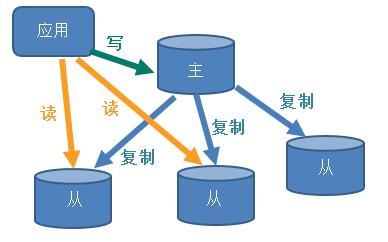
主要用途
-
读写分离:适用于读多写少的应用,增加多个从机,提高读的速度,提高程序并发 -
数据容灾恢复:从机复制主机的数据,相当于数据备份,如果主机数据丢失,那么可以通过从机存储的数据进行恢复。 -
高并发、高可用集群实现的基础:在高并发的场景下,就算主机挂了,从机可以进行主从切换,从机自动成为主机对外提供服务。
一主多从配置

环境准备
老哥太穷了,就用一台机器模拟三个机器。
-
第一步:将redis.conf复制3份,分别是redis6379.conf、redis6380.conf、redis6381.conf -
第二步:修改三个redis.conf文件里的port端口、pid文件名、日志文件名、rdb文件名 -
第三步:分别打开三个窗口模拟三台服务器,并开启redis服务。
查看当前3台机器主从角色
先用命令info replication看看3台机器目前的角色是什么。
# 三台机器都是这个状态
127.0.0.1:6379> info replication
# 角色是master主机
role:master
# 从机个数为0
connected_slaves:0
设置主从关系
这里注意,我们只设置从机就可以了,不用设置主机。我们选择6380和6381作为从机。6379作为主机。
# 6380 端口
127.0.0.1:6380> SLAVEOF 127.0.0.1 6379
# 6381 端口
127.0.0.1:6381> SLAVEOF 127.0.0.1 6379
# 6381 端口
127.0.0.1:6381> SLAVEOF 127.0.0.1 6379
再次查看3台机器目前角色
再次执行命令:info replication
# 主机
127.0.0.1:6379> info replication
role:master # 角色:主机
connected_slaves:2 #连接的从机个数,以及从机IP和端口
slave0:ip=127.0.0.1,port=6380,state=online,offset=98,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=98,lag=1
# 从机1
127.0.0.1:6380> info replication
role:slave # 角色:从机
master_host:127.0.0.1 # 主机的IP和端口
master_port:6379
# 从机2
127.0.0.1:6381> info replication
role:slave # 角色:从机
master_host:127.0.0.1 # 主机的IP和端口
master_port:6379
搭建成功,试验一把
-
全量复制:从机会把主机之前的数据全部都同步过来,大家可以在从机上get 某key试试。 -
增量复制:当主机新增数据时,从机会将该新增数据同步过来,大家可以在主机上执行命令set key value,然后在从机上get 该key,看是否能获取到。
读写分离
Redis的从机默认不允许进行写操作,大家可以在从机上执行命令set key value,会报错。
# 6380从机
127.0.0.1:6380> set k3 v3
(error) READONLY You can't write against a read only slave.
「呼,好累」,主从复制写的差不多了!!
主从复制原理
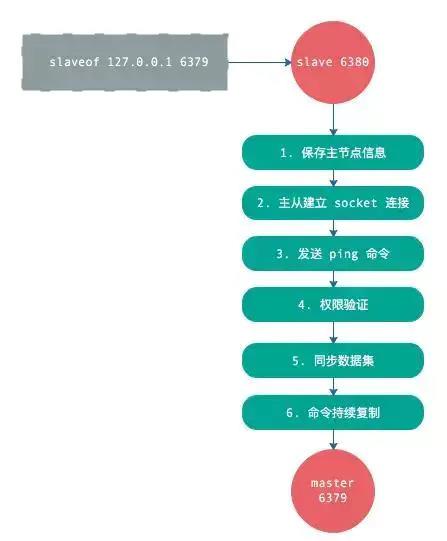
全量复制
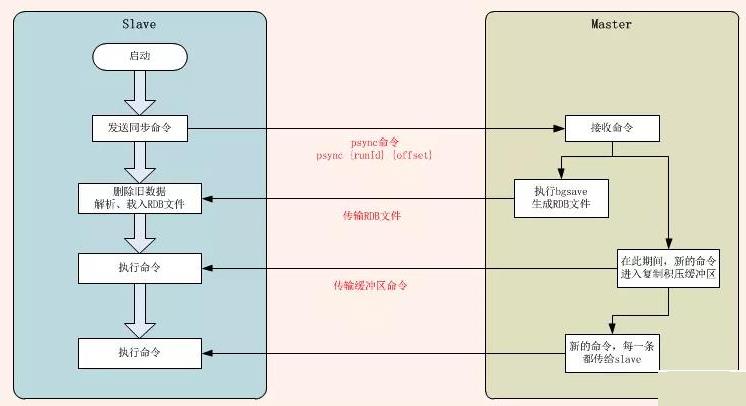
**「①」**slave发送psync,由于是第一次复制,不知道master的runid,自然也不知道offset,所以发送psync ? -1
**「②」**master收到请求,发送master的runid和offset给从节点。
**「③」**从节点slave保存master的信息
**「④」**主节点bgsave保存rdb文件
**「⑤」**主机点发送rdb文件
并且在**「④」和「⑤」**的这个过程中产生的数据,会写到复制缓冲区repl_back_buffer之中去。
**「⑥」**主节点发送上面两个步骤产生的buffer到从节点slave
**「⑦」**从节点清空原来的数据,如果它之前有数据,那么久会清空数据
**「⑧」**从节点slave把rdb文件的数据装载进自身。
全量复制的开销
**「①」**bgsave时间
**「②」**rdb文件网络传输时间
**「③」**从节点清空数据的
**「④」**从节点加载rdb的时间
**「⑤」**可能的aof重写时间,这是针对从节点,例如开启了aof之后,从节点添加buffer数据时候,可能需要aof重写
基于上面的原因,有的情况下不适合使用全量复制,例如网络抖动之后,从节点只需要传送一部分数据,不需要传送全部数据,redis2.8之后实现了部分复制功能
部分复制
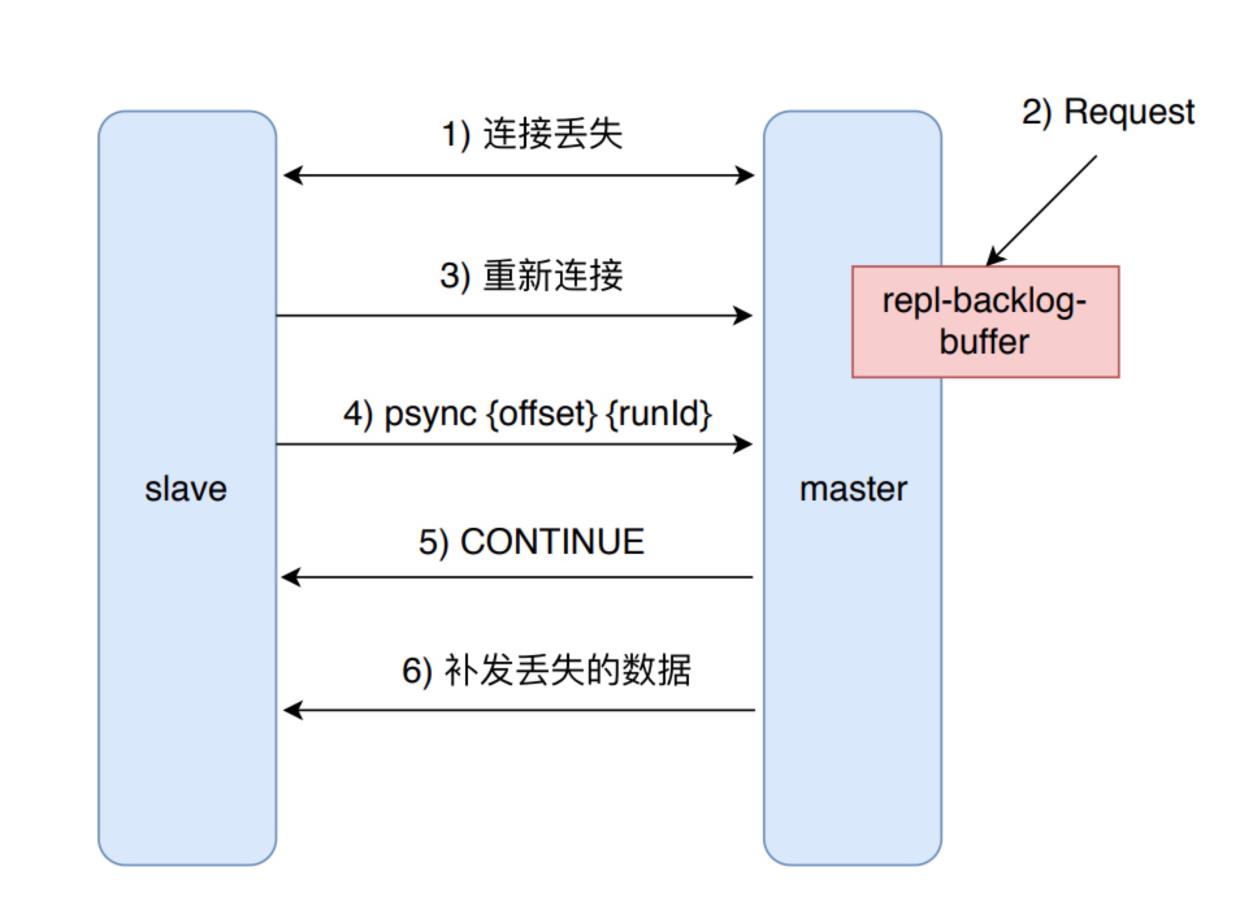
**「①」**假设发送网络抖动或者别的情况,暂时失去了连接
**「②」**这个时候,master还在继续往buffer里面写数据
**「③」**slave重新连接上了master
**「④」**slave向master发送自己的offset和runid
**「⑤」**master判断slave的offset是否在buffer的队列里面,如果是,那就返回continue给slave,否则需要进行全量复制(因为这说明已经错过了很多数据了)
**「⑥」**master发送从slave的offset开始到缓冲区队列结尾的数据给slave

总结:心得体会
既然选择这个行业,选择了做一个程序员,也就明白只有不断学习,积累实战经验才有资格往上走,拿高薪,为自己,为父母,为以后的家能有一定的经济保障。
学习时间都是自己挤出来的,短时间或许很难看到效果,一旦坚持下来了,必然会有所改变。不如好好想想自己为什么想进入这个行业,给自己内心一个答案。
面试大厂,最基本的就是夯实的基础,不然面试官随便一问你就凉了;其次会问一些技术原理,还会看你对知识掌握的广度,最重要的还是你的思路,这是面试官比较看重的。
最后,上面这些大厂面试真题都是非常好的学习资料,通过这些面试真题能够看看自己对技术知识掌握的大概情况,从而能够给自己定一个学习方向。包括上面分享到的学习指南,你都可以从学习指南里理顺学习路线,避免低效学习。
大厂Java架构核心笔记(适合中高级程序员阅读):
看看自己对技术知识掌握的大概情况,从而能够给自己定一个学习方向。包括上面分享到的学习指南,你都可以从学习指南里理顺学习路线,避免低效学习。
大厂Java架构核心笔记(适合中高级程序员阅读):
以上是关于MySQL数据库复制后为何无法读取表中数据?的主要内容,如果未能解决你的问题,请参考以下文章