机器阅读理解(Neural Machine Reading Comprehension)综述,相关方法及未来趋势
Posted 静待花开s0
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器阅读理解(Neural Machine Reading Comprehension)综述,相关方法及未来趋势相关的知识,希望对你有一定的参考价值。
Neural Machine Reading Comprehension:Methods and Trends
Author:Shanshan Liu , Xin Zhang , Sheng Zhang , Hui Wang , Weiming Zhang
PDF: https://arxiv.org/abs/1907.01118
0.写在前面:
机器阅读理解(MRC)需要机器回答基于给定上下文的问题,在过去几年里,随着各种深度学习技术的融合,它越来越受到关注。本文发表于2019年,主要从以下几个方面对该领域的研究进行了综述:(1)典型MRC任务的定义、差异和代表性数据集;(2)神经MRC的总体结构:主要模块和常用的方法;(3)新趋势:神经MRC的一些新兴领域及其面临的挑战。最后,考虑到迄今所取得的成就,调查还通过讨论有待解决的未决问题,展望了未来的前景。
总体结构图如下:
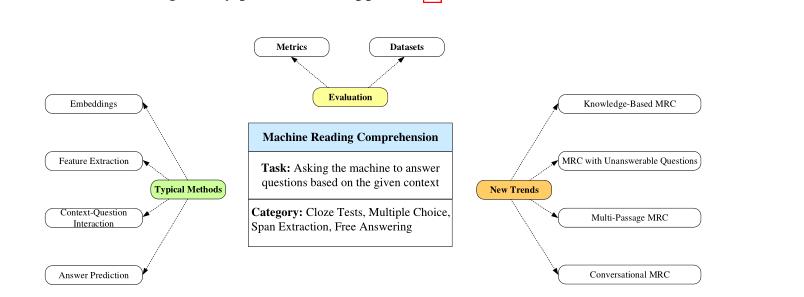
1. MRC任务简介:
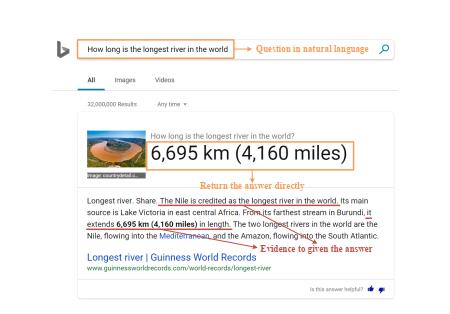
机器阅读理解(MRC)是一项通过让机器回答基于给定上下文的问题来测试机器理解自然语言的程度的任务,它有可能彻底改变人类和机器之间的互动方式。具有MRC技术的搜索引擎可以直接以自然语言返回用户提出的问题的正确答案,而不是返回一系列相关的web页面。
2. MRC分类及相关数据集:
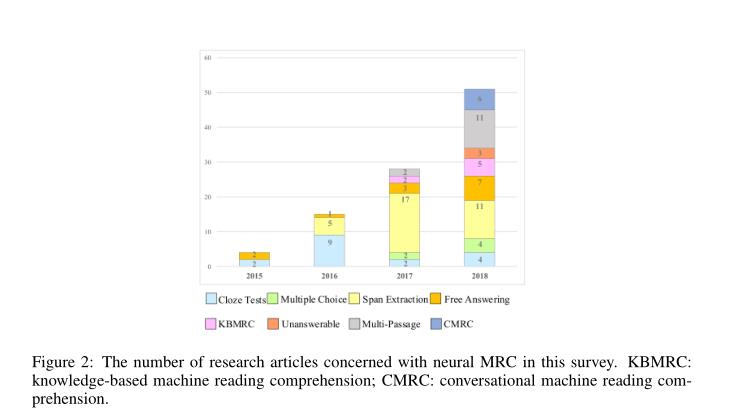
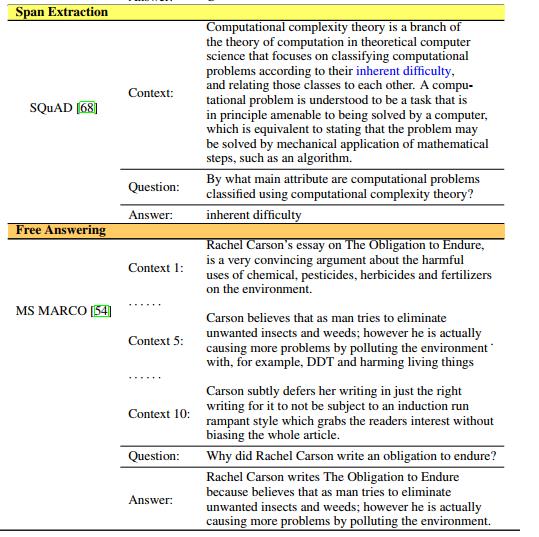
常见的MRC任务分为四种类型:cloze test, multiple choice, span extraction, free answer,相关研究随时间变化趋势如下图。
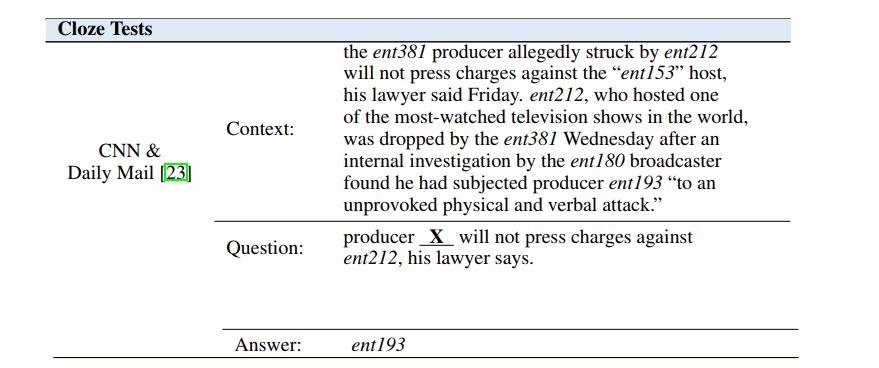
2.1 Cloze Tests
完形填空测试(Cloze test),也叫空白填空测试(gap-filling test),通常用于评估学生的语言能力的考试中。受此启发,这项任务被用来衡量机器理解自然语言的能力。在完形填空测试中,问题是通过从文章中删除一些单词或实体而产生的。为了回答问题,一个人被要求用缺失的项目填空。有些任务提供候选答案,但这是可选的。完形填空给阅读增加了障碍,需要理解上下文和词汇的使用,对机器阅读理解具有挑战性。

2.2 Multiple Choice
多项选择是另一个受语言能力考试启发的机器阅读理解题。它要求根据所提供的上下文从考生中选择正确的答案。与完形填空相比,多项选择题的答案不局限于上下文中的单词或实体,因此答案形式更加灵活,但本次任务要求考生提供答案。

2.3 Span Extraction
虽然完形填空和多项选择可以在一定程度上衡量机器理解自然语言的能力,但这些任务都有局限性。更具体地说,词汇或实体不足以回答问题。相反,需要一些完整的句子。而且,很多情况下都没有合适的答案。跨度提取任务可以克服这些弱点。给定上下文和问题,这个任务要求机器从相应的上下文中提取一段文本作为答案。

2.4 Free Answering
与完形填空和多项选择题相比,跨度提取任务在允许机器给出更灵活的答案方面取得了很大的进步,但这还不够,因为在限定的语境范围内给出答案仍然是不现实的。要回答这些问题,机器需要对文本的多个片段进行推理,并总结证据。在这四个任务中,自由回答是最复杂的,因为它的答题形式没有限制,更适合真实的应用场景。

2.5 MRC datasets

2.6 Comparison of Different Tasks
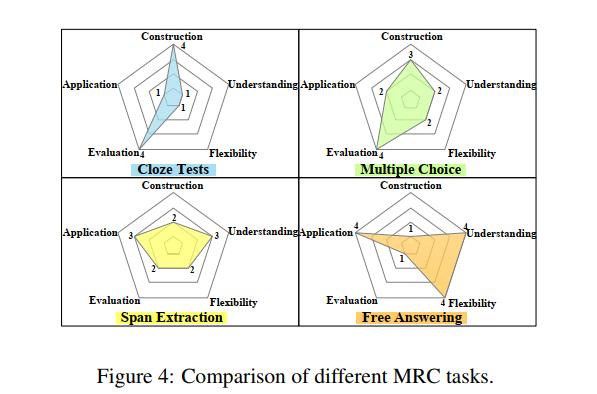
这五个维度的分数因不同的任务而不同。更具体地说,构建数据集和评估完形填空测试是最容易的。然而,由于答案形式在原始上下文中仅限于单个单词或名称实体,完形填空测试不能很好地测试机器的理解能力,也不符合实际应用。多项选择题会为每个问题提供考生的答案,这样即使答案不局限在原来的语境中,也可以很容易地进行评估。由于语言考试中的多项选择题很容易使用,因此构建数据集并不难。然而,候选答案导致了合成数据集和现实应用之间的差距。相反,跨度提取任务是一个适度的选择,数据集可以很容易地构建和评估。此外,在某种程度上,它们还可以测试机器对文本的理解能力。所有这些优点都有助于对这些任务进行大量的研究。跨度提取的缺点是将答案限制在原始上下文的子序列中,这与现实世界仍然有一些距离。自由回答的优势体现在理解、灵活和应用三个维度上,这些维度与实际应用最为接近。然而,任何事物都有两面性。由于答案形式的灵活性,构建数据集有些困难,如何有效地评估这些任务的性能仍然是一个挑战。
3. 神经MRC主要架构
神经MRC主要划分为四个模块,embeddings, feature extraction, context-question interaction 以及answer prediction 。
3.1 Embedding
嵌入模块是MRC系统的重要组成部分,通常放置在系统的开始部分,将输入的自然语言词编码成固定长度的向量,机器可以理解和处理这些向量。
3.1.1 传统单词表示
主要包括 one-hot 和Distributed Word Representation两种,one-hot使用二进制向量表示单词,它的大小与字典中的单词数相同。在这些向量中,一个位置是1表示对应单词,而其他所有位置都是0。作为一种早期的词汇表示方法,它可以在词汇量不是很大的情况下对词汇进行编码。然而,这种表示是稀疏的,会导致维度爆炸。Distributed Word Representation常见的有Word2Vec和GloVe[,对词之间的相关性具有很好的表示。
3.1.2 预训练的上下文相关的单词表示
预先用大型语料库进行训练,然后直接作为传统的词汇表征或根据特定任务进行微调。这是一种迁移学习,在包括机器阅读理解在内的一系列自然语言处理任务中表现出了良好的性能。即使是一个简单的神经网络模型也可以很好地使用这种预先训练好的单词表示方法进行答案预测。
常见的主要有CoVE,ELMo,GPT,BERT等。
3.2 Feature Extraction
特征提取所用的结构主要有CNN,RNN以及Transformer
3.3 Context-question interaction
主要分为单跳(one-hop)和多跳交互(multi-hop )
单跳交互是一种较浅的体系结构,其中上下文和问题之间的交互只计算一次。早期的上下文-查询交互在许多MRC系统中是一种单跳结构。与单跳交互相比,多跳交互要复杂得多;它试图通过多次计算上下文和问题之间的交互来模拟人类的重读现象。
3.4 Answer Prediction
针对四种不同的阅读理解任务,此处答案预测方法也分为四种与任务对应,Word Predictor,option selector, span extractor, and answer generator。
3.5 Additional Tricks
以上为一些典型的深度学习方法,但还有一些额外的技巧,如强化学习、答案排序器和句子选择器,这些都不能包含在通用MRC体系结构中。然而,这些技巧也有助于提高性能。
强化学习可以看作是MRC系统的一种改进方法,它不仅可以缩小优化目标与评估指标之间的差距,而且可以动态地决定是否停止推理。有了强化学习,即使某些状态是离散的,模型也可以被训练并提炼出更好的答案。使用答案排序器可以在一定程度上提高答案预测的准确性。句子选择器目标为找到回答一个问题所需的最小句子集,从而提高精度和效率。
4. 评估方法
对于不同的MRC任务,有不同的评估指标。在评估完形填空题和多项选择题时,最常用的衡量标准是准确率(Accuracy)。在跨度提取方面,使用精确匹配(EM)和F1-score来衡量模型的性能。由于自由回答题的答案不受原语境的限制,故广泛使用ROUGE-L和BLEU来评估。
5. 未来趋势
-
Knowledge-Based Machine Reading Comprehension

-
Machine Reading Comprehension with Unanswerable Questions

- Multi-Passage Machine Reading Comprehension

- Conversational Machine Reading Comprehension

6. 结语
目前的MRC模型虽然在某些给定的任务上已经超过了人类,但是还有很多的不足之处,如鲁棒性不足,可解释性差,推理能力的不足等等,表明机器并非具有真正的阅读理解能力,未来还将进行更加深入的研究探讨。
以上是关于机器阅读理解(Neural Machine Reading Comprehension)综述,相关方法及未来趋势的主要内容,如果未能解决你的问题,请参考以下文章