Hadoop HA——namenode无法启动问题解决
Posted yhao浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop HA——namenode无法启动问题解决相关的知识,希望对你有一定的参考价值。
今天按照之前《Hadoop2.6.0 + zookeeper集群环境搭建 》一文重新搭建了Hadoop2.7.2+zookeeper的HA,实现namenode挂掉后可以自动切换,总体来说还算比较顺利。搭建完成后一切正常!但是!第二天重新启动集群的时候出现问题:两个namenode有一个始终启动不了!,具体问题描述如下:
问题描述
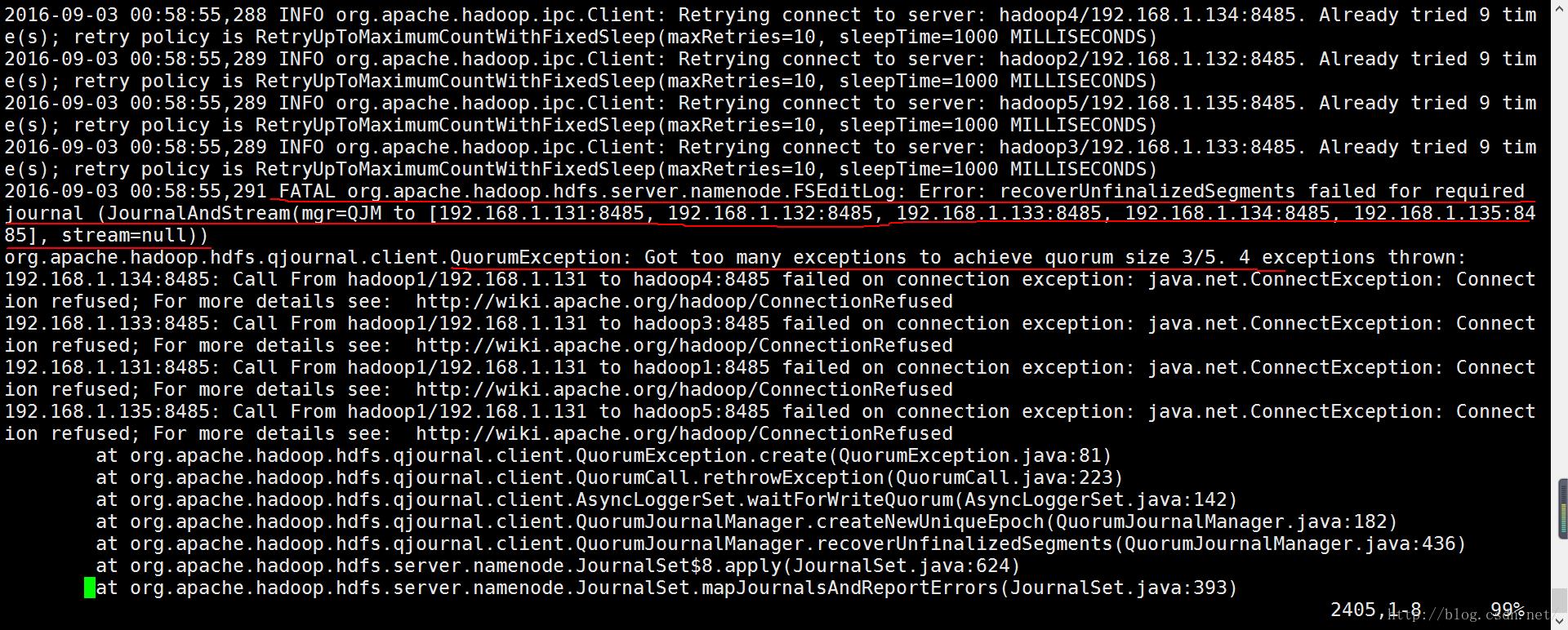
HA按照规划配置好,启动后,NameNode不能正常启动。刚启动的时候 jps 看到了NameNode,但是隔了一两分钟,再看NameNode就不见了。查看日志发现以下报错信息:
org.apache.hadoop.ipc.Client:Retrying connect to server
但是测试之后,发现下面2种情况:
- 先启动JournalNode,再启动Hdfs,NameNode可以启动并可以正常运行
- 使用start-dfs.sh启动,众多服务都启动了,隔两分钟NameNode会退出,再次hadoop-daemon.sh start namenode单独启动可以成功稳定运行NameNode。
再看NameNode的日志,不要嫌日志长,其实出错的蛛丝马迹都包含其中了,如下:


问题分析
看着日志很长,来分析一下,注意看日志中使用颜色突出的部分。
可以肯定NameNode不能正常运行,不是配置错了,而是不能连接上JournalNode、
查看JournalNode的日志没有问题,那么问题就在JournalNode的客户端NameNode。
2016-09-0300:58:46,256 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: hadoop2/192.168.1.132:8485. Already tried 0 time(s);retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000MILLISECONDS)
来分析上句的日志:
NameNode作为JournalNode的客户端发起连接请求,但是失败了,然后NameNode又向其他节点依次发起了请求都失败了,直至到了最大重试次数。
通过实验知道,先启动JournalNode或者再次启动NameNode就可以了,说明JournalNode并没有准备好,而NameNode已经用完了所有重试次数。
解决办法
修改core-site.xml中的ipc参数
<property>
<name>ipc.client.connect.max.retries</name>
<value>20</value>
<description>
Indicates the number of retries a clientwill make to establisha server connection.
</description>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>5000</value>
<description>
Indicates the number of milliseconds aclient will wait for before retrying to establish a server connection.
</description>
</property>
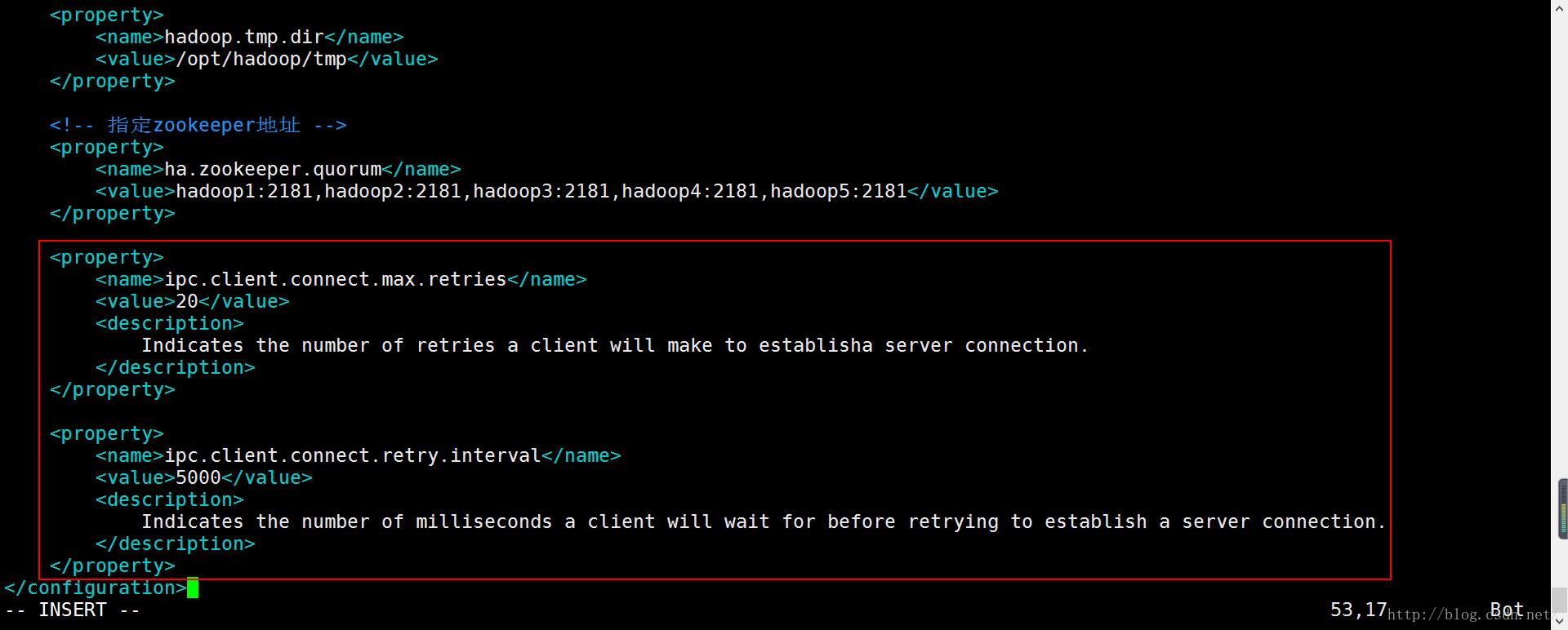
Namenode向JournalNode发起的ipc连接请求的重试间隔时间和重试次数,我的虚拟机集群实验大约需要2分钟,NameNode即可连接上JournalNode。连接后很稳定。
注意:仅对于这种由于服务没有启动完成造成连接超时的问题,都可以调整core-site.xml中的ipc参数来解决。如果目标服务本身没有启动成功,这边调整ipc参数是无效的。
结果


可以看到namenode已经正常启动了,并且比较稳定
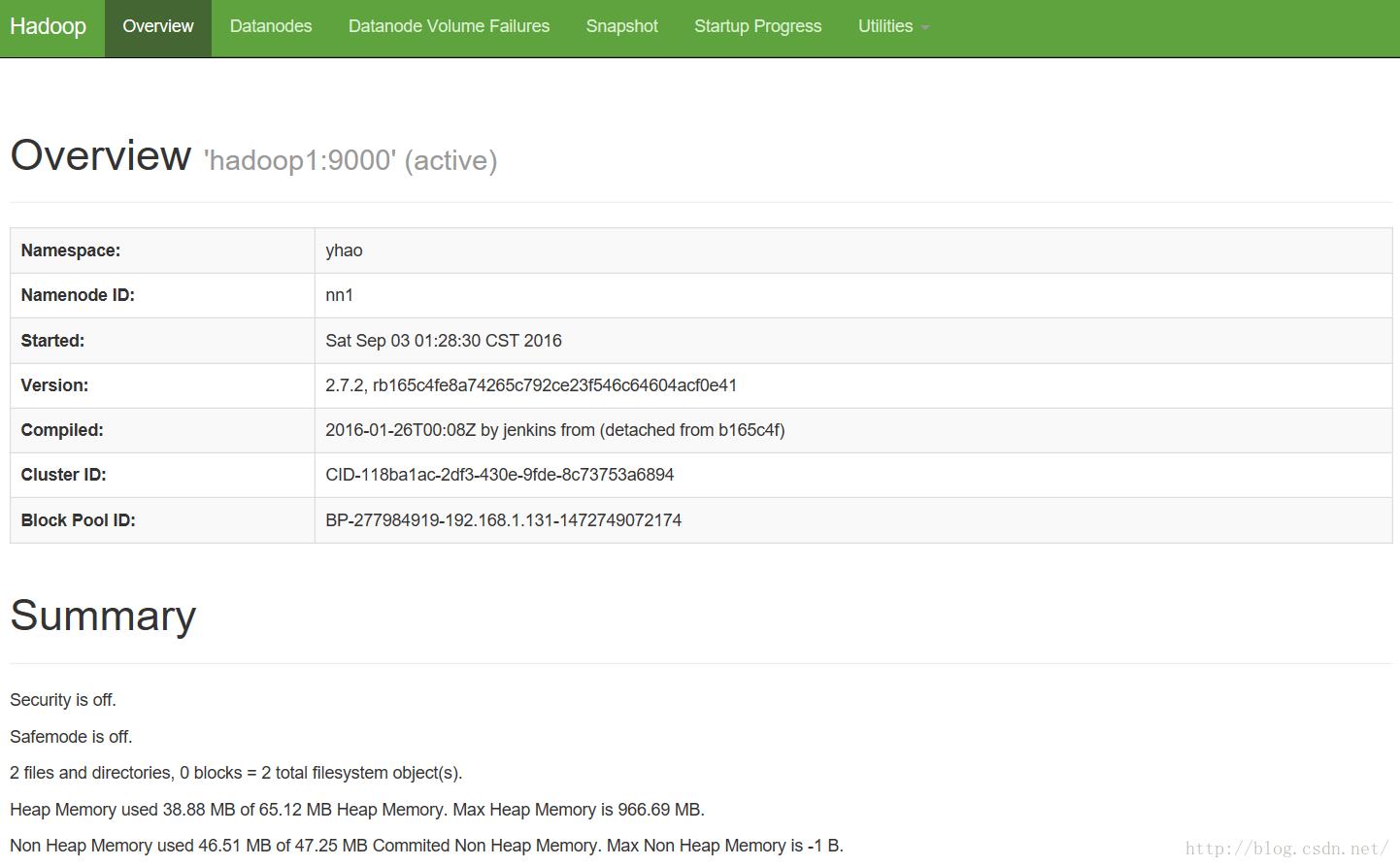
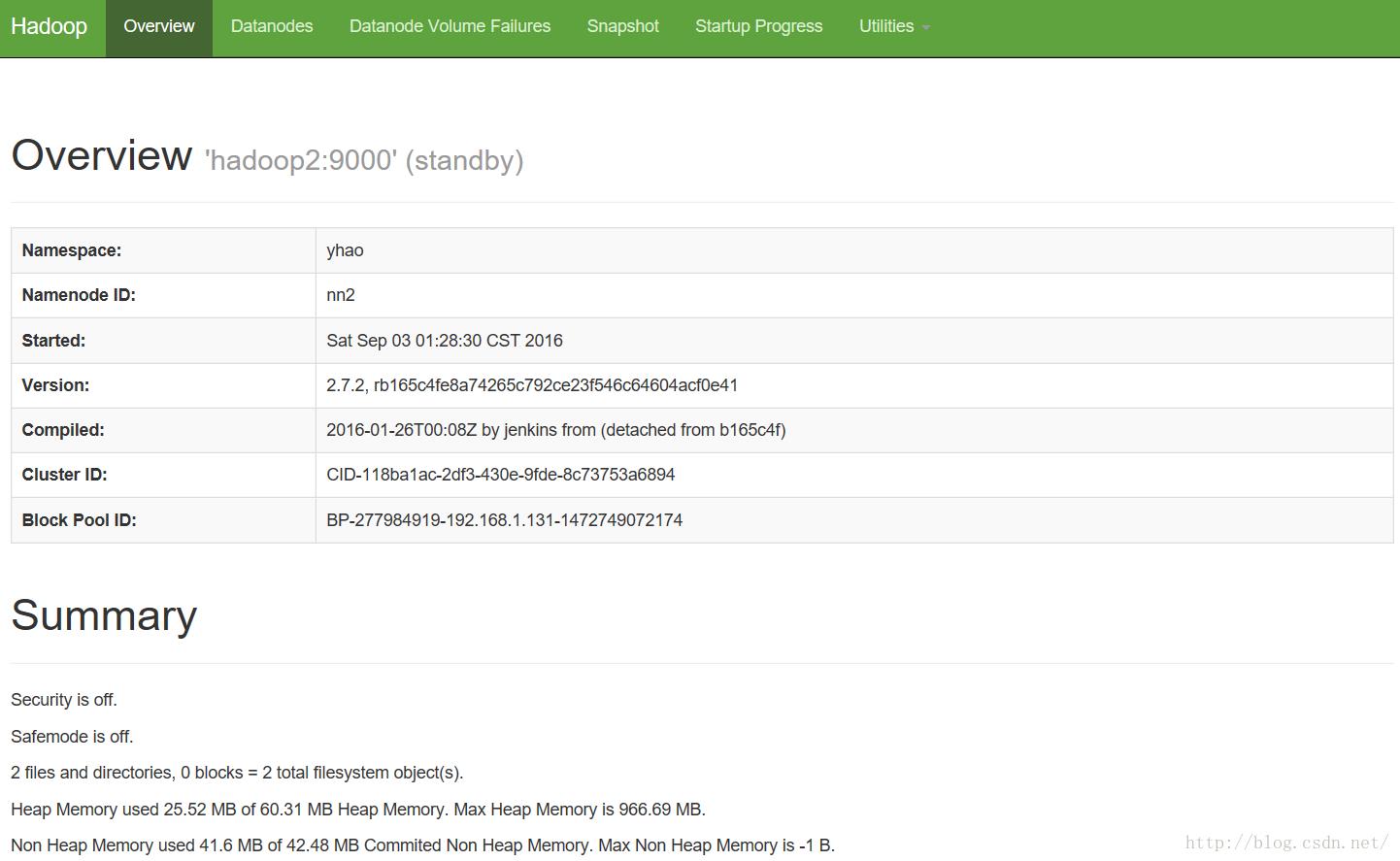
从界面上也能看到两个namenode都已启动,一个为active状态,一个为standby状态。
以上是关于Hadoop HA——namenode无法启动问题解决的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop HA集群 NameNode 无法自动故障转移(切换active)
Apache hadoop namenode ha和yarn ha ---HDFS高可用性