TerichDB架构简介
Posted Terark-CTO-雷鹏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TerichDB架构简介相关的知识,希望对你有一定的参考价值。
TerichDB是一款高性能和高压缩率的存储引擎,既可以单独作为数据库使用,也可以作为已有数据库的存储引擎使用(如mysql/MongoDB)
TerichDB的定位类似于WiredTiger、RocksDB或LevelDB
1. 为什么使用 TerichDB
- 高性能的同时具有高压缩率
- 高性能并非来自于时间空间的互换
- 时间和空间同时获得的缩减
- 延迟非常低并且很稳定
- 基于Schema定义,并具有丰富的数据类型
- 针对不同的数据类型进行了独特优化
- 支持单表多索引
- 使用列存储,支持列簇
2. 性能(不限内存)
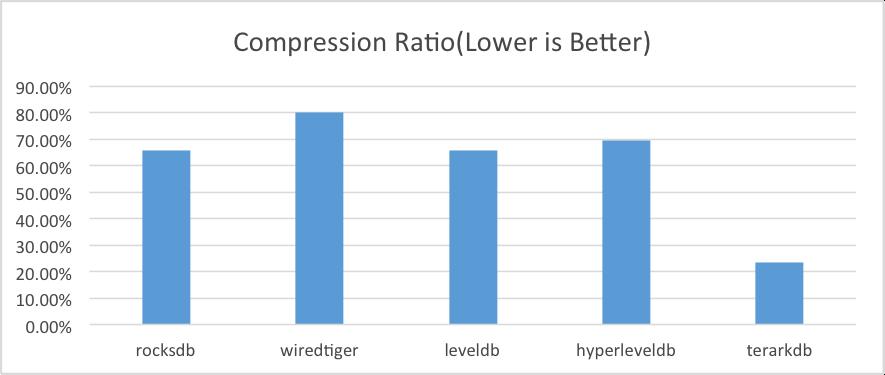
2.1. 压缩率
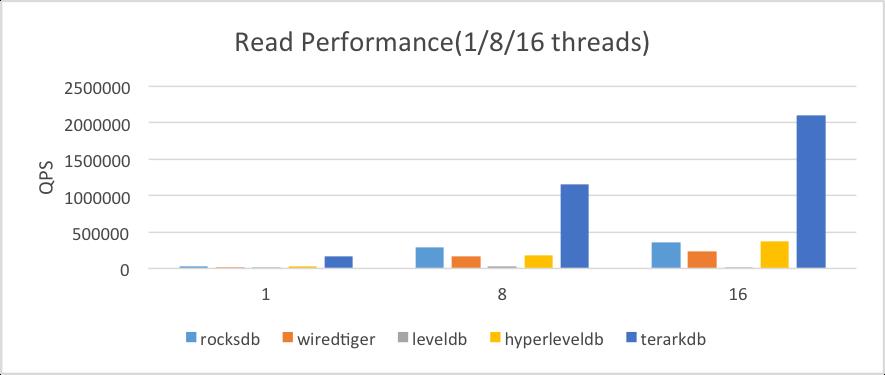
2.2. 读性能
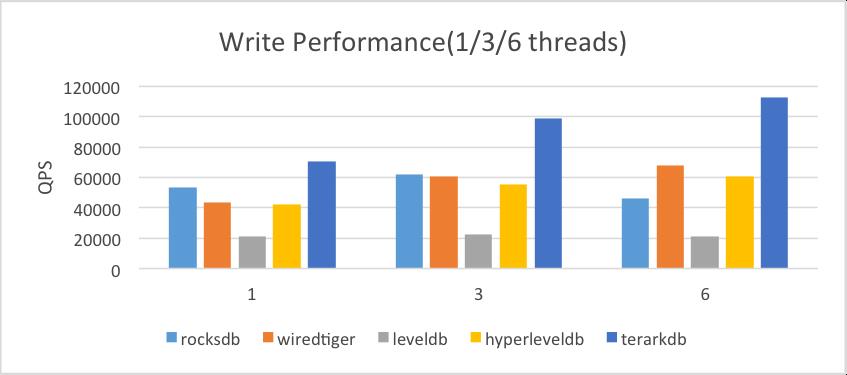
2.3. 写性能
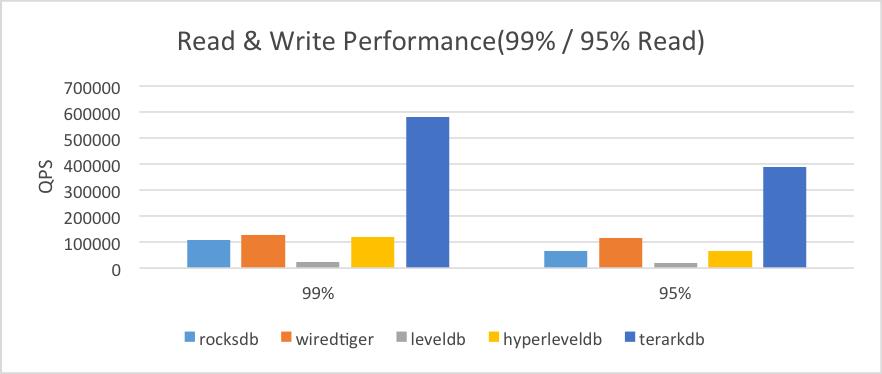
2.4 读写混合
3. 使用TerichDB
TerichDB有两种使用方式,第一种是作为单独的数据库或存储,第二种是作为其他数据库的存储引擎:
- 作为单独的数据库或存储
- 原生C++支持(同时正在集成Java、Python绑定)
- 这种方式能获得完整的TerichDB性能和特性
- 作为其他数据库的存储引擎(MongoDB, MySQL, FUSE等)
- 简洁易用的上层接口
- 能够获得大部分的TerichDB性能和特性
4. 索引压缩简介
TerichDB的数据索引使用了 Succinct 技术、Nested Succinct Trie数据结构,压缩率是B+树的3到5倍,并且针对不同类型的字段进行了单独的优化处理,同时用户也可以指定字段使用的压缩方式。
我们把自己 TerichDB 的索引压缩算法称为可检索索引压缩(Searchable Index Compression),TerichDB 的索引经过高度压缩的同时,可以被直接检索,而且无需事先解压。
由于整个索引结构会非常的小,默认情况下 TerichDB 会将所有的索引都加载到内存中,在高度压缩的索引上检索速度可以达到极快的速度。
5. 数据压缩简介
TerichDB的数据压缩方式,与传统的数据库也有很大的不同,我们把自己的压缩算法称为 可定点访问数据压缩(Seekable Data Compression) :
- 传统数据库压缩算法
- 将多条记录压缩到一个块(block)或者页(page)中
- 压缩后的数据存储于磁盘,解压后进入内存由数据库管理,会有OS Cache和Memory两份缓存(Double Cache)
- 压缩块越大,压缩率越高,但是读性能就越低,不可兼得
- TerichDB 压缩算法
- 直接通过RecordID查询数据,不需要额外的数据解压(即, 非块压缩)
- 可以处理更大的数据量,同时有更高的压缩率
- 不需要缓存未压缩的记录
- 利用空闲内存,充分发挥文件系统缓存的优势
- 拥有更高的读性能
同时,数据的压缩算法,还针对以下两种字段情况,进行了特殊处理
- 较小的字符串
- 使用Nested Succinct Trie数据结构进行压缩
- 具有非常高的压缩率
- 相对较低的读性能(依然比 块压缩 高很多)
- 较大的字符串
- 全局+局部字典压缩(lz77变种)
- 较高的压缩率,比gzip高,某些情况下比bzip2更高
- 极快的读性能(几乎是内存拷贝(
memcpy)的速度)
6. TerichDB 架构
TerichDB是一系列领先技术的结晶, 具有模块化、易扩展等特性,同时极大的降低了各种系统损耗。
6.1. 表结构
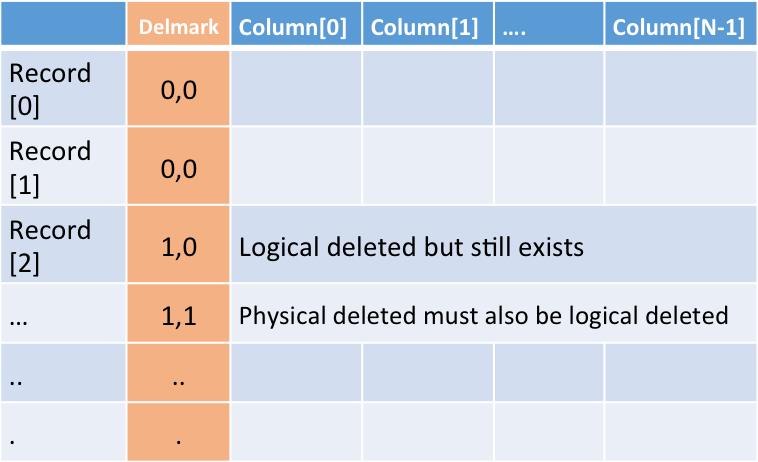
TerichDB中,最上层的逻辑层就是一个表(Table),从上图可以看出,逻辑上一个 Table 就是一个二维的表格,其中recordId是逻辑连续的,当某一行的数据被删除后,这个recordId还会继续存在。
第二列是删除标记,表示改行的删除状态,共有两个标记,分别是:(逻辑删除,物理删除), 如 (1, 0) 表示逻辑删除,物理上还没有删除。
虽然从逻辑上来说,recordId是连续的,但是实际上物理上每一个表都是”分段(segment)”的,每一段的结构都与上图一样。
逻辑编号和物理编号的映射是通过 rank select 实现的,这部分的性能损耗非常的小(小于1%,甚至小于0.1%)。
特殊情况下,如果没有做过删除,物理编号和逻辑编号是完全相同的,这种情况下映射带来性能损耗也就没有了。
6.2. Record Id不变性
RecordId是标示一个表中的一行数据用的,当RecordId的不变形被确保的情况下:
- 相同的RecordId永远取到同样的值
- 相同的Key(字段名)检索到的RecordId永远相同
- Segment的变动(合并、压缩、删除)不会影响RecordId
当然,我们可以配置RecordId的不变性声明周期:
- 永久性的:多次表重载后,依然不变
- 在对外服务的场景下有用,如固定的URL:http://host.com?id=3
- 表周期:每次表被重新加载后,被删除的 RecordId 将失去原有意义
- 节省 RecordId 数组的下标位置
- 轻微的提升性能
6.2. 段,索引和列组

未建立索引的列,会被存储在列组(Column Group)中,列组是在 Table Schema中提前定义好的。
常见的列组会使用我们的 可定位数据压缩(Seekable Data Compression) 算法进行压缩,同时定长的列组可以被定义为支持原地更新。
索引操作的过程:
- 如用户希望找到 name 为 AAA 的记录中,age的值,其中name字段已建立索引
- 根据 name 所在的索引,快速检索到数据 AAA,然后获得当前记录的 RecordId
- 根据RecordId和目标key(即age),直接获得最终这一个字段的数据
- 传统数据库此处需要提取完整的一行记录,然后再这条记录中寻找目标字段的值
- TerichDB 只需要根据 RecordId 获得目标字段的逻辑数组,直接以数组下标即可获得目标字段的值
索引操作的这两个操作过程,能实现的功能如下:
- 根据KEY获得逻辑的RecordId
- 精确搜索: 最快
- 范围搜索: 根据不同索引的迭代器实现
- 正则查询: 尽最大可能避免线性扫描
- 根据RecordId读取目标数据
- 读取整条记录
- 读取指定的几个字段
- 读取指定的列组(最快)
6.3. 段(Segment)
6.3.1. 可写(Writable) & 只读(Readonly) 段
TerichDB 的可写段(Writable Segment):
- 可以是正在写(Writing)或者冻结(Frozen)状态
- 目前的实现基于一个传统的数据库
- 不做压缩
- 比只读的段读取速度慢一些
TerichDB的只读段(Readonly)是我们的核心竞争力:
- 高性能同时具有高压缩率
- 稳定的延迟(没有慢查询,更优异的P99延迟)
- 不需要专有的缓存(自然解决double cache问题)
- 定长字段可以原地更新
6.3.2. 正在写(Writing) 和 冻结(Frozen) 段
- 正在写的段是由传统数据库实现的
- 当正在写的段,数据达到了预设的
segment size后,将会转变成冻结状态(Frozen) - 然后新的可写段会被创建,并且立即变成正在写的段
- 插入/更新/删除是是实时的,不会阻塞用户线程
- 当正在写的段,数据达到了预设的
- 冻结段
- 可以是一个只读的段(只读段总是冻结的)
- 可以是一个可写段(当等待压缩或者正在压缩时)
- 删除(或原地更新)是实时的
6.3.3. 正在写的段 (Writing Segment)
- 正在写的段是最新的可写段
- 新记录都会到这里来
- 正在写的段中的记录,可以被直接修改
- 热数据(尤其是被频繁更新的数据)通常都在正在写的段
- 写数据时索引是同步的(插入/更新/删除)
- 索引同步会降低插入速度
- 索引同步某些情况下可以禁用掉
- 如: 批量导入数据, 此时没有并发的读取操作, 禁用可以显著的提高性能
- 如果禁用了索引同步, 新插入的数据可能无法被任何索引搜索到,但是可以被 RecordId 访问
6.3.4. 冻结段 (Frozen Segment)
- 冻结段可以是一个只读段或者一个可写段
- 所有的数据都是只读(即便是被冻结的可写段)
- 对于原地更新的字段是例外
- 删除: 设置删除标记
- 更新: 设置逻辑删除标记,并且在正在写的段创建一个新的记录(即便是在可写段进行的更新操作)
- 物理删除
- 永久性的把逻辑删除的数据情况
- 需要重新构建只读段
6.3.5. 只读段 (Readonly Segment)
只读段的概述:
- 绝大多数的数据都会被存储于只读段中(比如 99% 的数据)
- 具有非常快的可检索索引压缩
- 具有非常快的可定位数据压缩(在8倍的压缩率的情形,达到 7GB/s)
- 由后台线程创建,不阻塞用户线程
- 更大的段具有更高的压缩率和性能
- 针对列存储进行了优化
如何会产生只读的段:
- 构建一个新的只读段,表示
- 将一个可写段压缩成一个只读段
- 清除逻辑删除了的记录
- 将多个只读段合并为同一个只读段
- 当一个正在写的段被冻结了
- 它会被转交给压缩队列
- 然后会被后台线程压缩成只读段
- 压缩通常会比插入更慢一些
- 同时会有很多线程在进行压缩
- 当压缩(或合并、清除)结束
- 原始的段会被压缩后的段代替,原始段同时被删除
- 将压缩过程中产生的更新和删除操作进行同步
- RecordId 不变性继续保持
6.3.6. 原地更新的列组 (In-place updatable column groups)
- 原则: Less pain, more gain
- 只适用于定长的列组
- 可以直接通过内存地址访问
- 可以以极低的损耗实现
- 对所有的段都生效(包括 只读段)
- 当一个段正在被压缩、合并或物理删除
- 暂时记录这个更新
- 当压缩或合并完成后,继续这个更新
- 不会阻塞用户线程
以上是关于TerichDB架构简介的主要内容,如果未能解决你的问题,请参考以下文章