JAVA解析XML文件
Posted 故意的是吧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JAVA解析XML文件相关的知识,希望对你有一定的参考价值。
.xml文件,树形结构
标准XML文档示例:
<?xml version="1.0" encoding="UTF-8"?>
<bookStore>
<book id="1">
<name>冰与火之歌</name>
<author>乔治马丁</author>
<year>2014</year>
<price>99</price>
</book>
<book id="2">
<name>秦腔</name>
<author>贾平凹</author>
<price>90</price>
</book>
</bookStore>Why?:
1、不同应用程序之间的通信问题(订票软件和支付软件);
2、不同平台间的通信(MAC和windows);
3、不同平台间共享数据(PC端和移动端)
JAVA读取XML(解析)
目的:
获取节点名、节点值、属性名、属性值。解析后JAVA程序能够得到XML文件的所有数据
四种方式:
DOM(官方)
SAX(官方)
DOM4J(需要导jar包)
JDOM(需要导jar包)
books.xml文件练习:
DOM解析
将xml文件全部加载到内存,然后逐个解析。
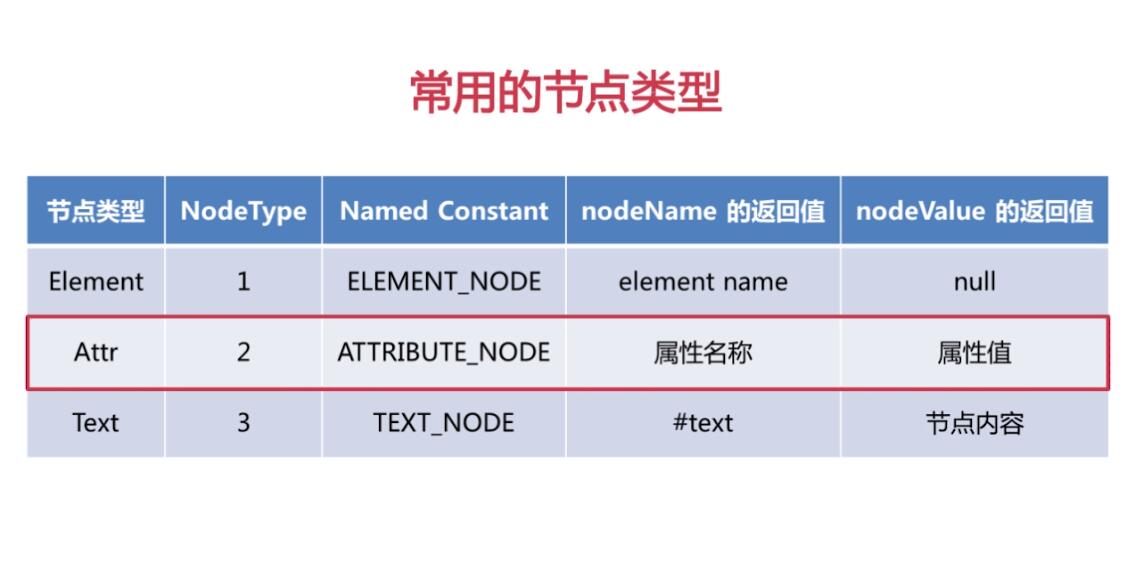
常用节点类型
解析方法:
package DomTest;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class DOMTest
public static void main(String[] args)
// 创建一个DocumentBuilderFactory对象
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
// 创建一个DocumentBuilder的对象
try
// 创建DocumentBuilder对象
DocumentBuilder db = dbf.newDocumentBuilder();
// 通过DocumentBuilder对象的parse方法加载books.xml文件
// 到当前项目下
Document document = db.parse("books.xml");
// 获取所有book节点的集合
NodeList bookList = document.getElementsByTagName("book");
//通过nodeList的getLength()方法获取bookLIst的长度
System.out.println("一共有:"+bookList.getLength()+"本书");
//便利各个book节点
for (int i = 0; i < bookList.getLength(); i++)
System.out.println("开始遍历第"+(i+1)+"本书");
//通过 item(i)获取一个book节点,nodeList
Node book=bookList.item(i);
//获取book的属性的集合
NamedNodeMap attrs=book.getAttributes();
System.out.println("第"+(i+1)+"本书共有"+attrs.getLength()+"个属性");
//便利book的属性
for (int j = 0; j < attrs.getLength(); j++)
//通过item()方法获取book节点的某一个属性
Node attr=attrs.item(j);
//获取属性名
System.out.println("属性名:"+attr.getNodeName());
//获取属性值
System.out.println("属性值:"+attr.getNodeValue());
System.out.println("结束遍历第"+(i+1)+"本书");
catch (SAXException e)
e.printStackTrace();
catch (IOException e)
e.printStackTrace();
catch (ParserConfigurationException e)
e.printStackTrace();
输出:
一共有:2本书
开始遍历第1本书
第1本书共有1个属性
属性名:id
属性值:1
结束遍历第1本书
开始遍历第2本书
第2本书共有1个属性
属性名:id
属性值:2
结束遍历第2本书
已知节点属性名称的情况下的遍历:
package DomTest;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class DOMTest
public static void main(String[] args)
// 创建一个DocumentBuilderFactory对象
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
// 创建一个DocumentBuilder的对象
try
// 创建DocumentBuilder对象
DocumentBuilder db = dbf.newDocumentBuilder();
// 通过DocumentBuilder对象的parse方法加载books.xml文件
// 到当前项目下
Document document = db.parse("books.xml");
// 获取所有book节点的集合
NodeList bookList = document.getElementsByTagName("book");
//通过nodeList的getLength()方法获取bookLIst的长度
System.out.println("一共有:"+bookList.getLength()+"本书");
//便利各个book节点
for (int i = 0; i < bookList.getLength(); i++)
System.out.println("++++++++++++开始遍历第"+(i+1)+"本书+++++++++++");
//方式一,不知道有多少节点,通过循环来遍历所有节点。
// //通过 item(i)获取一个book节点,nodeList
// Node book=bookList.item(i);
// //获取book的属性的集合
// NamedNodeMap attrs=book.getAttributes();
// System.out.println("第"+(i+1)+"本书共有"+attrs.getLength()+"个属性");
// //便利book的属性
// for (int j = 0; j < attrs.getLength(); j++)
// //通过item()方法获取book节点的某一个属性
// Node attr=attrs.item(j);
// //获取属性名
// System.out.println("属性名:"+attr.getNodeName());
// //获取属性值
// System.out.println("属性值:"+attr.getNodeValue());
//
//方式二,知道有且只有一个节点。并且知道属性的名称为“id”
//强制类型转换将book节点类型转换为Element类型
Element book =(Element) bookList.item(i);
//通过getAttribute(“id”)方法获取到属性的值
String attrValue=book.getAttribute("id");
System.out.println("id的属性的属性值为"+attrValue);
// //解析book节点的子节点,需要用到方式一中创建的book对象
// //获取子节点的集合
// NodeList childNodes=book.getChildNodes();
//
// //遍历childNodes获取每个子节点的节点名和节点值
// System.out.println("第"+(i+1)+"本书共有"+childNodes.getLength()+"个子节点");
//
System.out.println("++++++++++++结束遍历第"+(i+1)+"本书++++++++++++");
catch (SAXException e)
e.printStackTrace();
catch (IOException e)
e.printStackTrace();
catch (ParserConfigurationException e)
e.printStackTrace();
输出:
一共有:2本书
++++++++++++开始遍历第1本书+++++++++++
id的属性的属性值为1
++++++++++++结束遍历第1本书++++++++++++
++++++++++++开始遍历第2本书+++++++++++
id的属性的属性值为2
++++++++++++结束遍历第2本书++++++++++++
解析book节点下的所有子节点:
package DomTest;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class DOMTest
public static void main(String[] args)
// 创建一个DocumentBuilderFactory对象
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
// 创建一个DocumentBuilder的对象
try
// 创建DocumentBuilder对象
DocumentBuilder db = dbf.newDocumentBuilder();
// 通过DocumentBuilder对象的parse方法加载books.xml文件
// 到当前项目下
Document document = db.parse("books.xml");
// 获取所有book节点的集合
NodeList bookList = document.getElementsByTagName("book");
//通过nodeList的getLength()方法获取bookLIst的长度
System.out.println("一共有:"+bookList.getLength()+"本书");
//便利各个book节点
for (int i = 0; i < bookList.getLength(); i++)
System.out.println("++++++++++++开始遍历第"+(i+1)+"本书+++++++++++");
//方式一,不知道有多少节点,通过循环来遍历所有节点。
//通过 item(i)获取一个book节点,nodeList
Node book=bookList.item(i);
//获取book的属性的集合
NamedNodeMap attrs=book.getAttributes();
System.out.println("第"+(i+1)+"本书共有"+attrs.getLength()+"个属性");
//便利book的属性
for (int j = 0; j < attrs.getLength(); j++)
//通过item()方法获取book节点的某一个属性
Node attr=attrs.item(j);
//获取属性名
System.out.println("属性名:"+attr.getNodeName());
//获取属性值
System.out.println("属性值:"+attr.getNodeValue());
// //方式二,知道有且只有一个节点。并且知道属性的名称为“id”
// //强制类型转换将book节点类型转换为Element类型
// Element book =(Element) bookList.item(i);
//
// //通过getAttribute(“id”)方法获取到属性的值
// String attrValue=book.getAttribute("id");
// System.out.println("id的属性的属性值为"+attrValue);
//解析book节点的子节点,需要用到方式一中创建的book对象
//获取子节点的集合
NodeList childNodes=book.getChildNodes();
//遍历childNodes获取每个子节点的节点名和节点值
System.out.println("第"+(i+1)+"本书共有"+childNodes.getLength()+"个子节点");
//循环遍历
for (int j = 0; j < childNodes.getLength(); j++)
//区分text类型的node和element类型的node
if(childNodes.item(j).getNodeType()==Node.ELEMENT_NODE)
//输出了element类型节点的节点名
System.out.println("第"+(j+1)+"个节点名:"+childNodes.item(j).getNodeName());
//输出element类型节点的节点值
//需先获取当前节点的首个子节点,否则获取的是《name》标签的值NULL
//方式一:如果<name>节点下有多个子节点,此方法只输出确定的某个子节点的值
//同样要注意,<name>节点的第一个子节点的值是第一子节点的类型的值,还是NULL
System.out.println("节点值为:"+childNodes.item(j).getFirstChild()
.getNodeValue());
//方式二:如果<name>节点下有多个子节点,此方法输出所有子节点的text
System.out.println(childNodes.item(j).getTextContent());
System.out.println("++++++++++++结束遍历第"+(i+1)+"本书++++++++++++");
catch (SAXException e)
e.printStackTrace();
catch (IOException e)
e.printStackTrace();
catch (ParserConfigurationException e)
e.printStackTrace();
输出:
一共有:2本书
++++++++++++开始遍历第1本书+++++++++++
第1本书共有1个属性
属性名:id
属性值:1
第1本书共有9个子节点
第2个节点名:name
节点值为:冰与火之歌
冰与火之歌
第4个节点名:author
节点值为:乔治马丁
乔治马丁
第6个节点名:year
节点值为:2014
2014
第8个节点名:price
节点值为:99
99
++++++++++++结束遍历第1本书++++++++++++
++++++++++++开始遍历第2本书+++++++++++
第2本书共有1个属性
属性名:id
属性值:2
第2本书共有7个子节点
第2个节点名:name
节点值为:秦腔
秦腔
第4个节点名:author
节点值为:贾平凹
贾平凹
第6个节点名:price
节点值为:90
90
++++++++++++结束遍历第2本书++++++++++++
SAX解析XML文件
通过自己创建的一个Handler类,由外向内顺序逐个解析。
初步解析:
步骤:
1、通过SAXParseFactory的静态newInstance()方法获取SAXParseFactory实例factory
2、通过SAXParserFactory实例的newSAXParser()方法返回SAXParse实例parser
3、创建一个类继承DefaultHandler,重写其中的一些方法进行业务处理并创建这个类的实例handler
重写两个方法:
startElement()
endElement()
SAXParserHandler:
package test2;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SAXParserHandler extends DefaultHandler
/***
* 遍历xml的开始标签
*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException
// TODO Auto-generated method stub
super.startElement(uri, localName, qName, attributes);
/***
* 遍历xml的结束标签
*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException
// TODO Auto-generated method stub
super.endElement(uri, localName, qName);
/***
* 标识解析开始
*/
@Override
public void startDocument() throws SAXException
// TODO Auto-generated method stub
super.startDocument();
System.out.println("SAX解析开始");
/***
* 标识解析结束
*/
@Override
public void endDocument() throws SAXException
// TODO Auto-generated method stub
super.endDocument();
System.out.println("SAX解析结束");
SAXTest.java:
package test;
import java.io.IOException;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.SAXException;
import test2.SAXParserHandler;
public class SAXTest
public static void main(String[] args)
// 通过SAXParseFactory的静态newInstance()
//方法获取SAXParseFactory实例factory
SAXParserFactory factory=SAXParserFactory.newInstance();
//通过SAXParserFactory实例的newSAXParser()
//方法返回SAXParse实例parser
try
SAXParser parser= factory.newSAXParser();
//创建SAXParserHandler对象
SAXParserHandler handler=new SAXParserHandler();
parser.parse("books.xml", handler);
catch (IOException e)
// TODO Auto-generated catch block
e.printStackTrace();
catch (ParserConfigurationException | SAXException e)
// TODO Auto-generated catch block
e.printStackTrace();
运行输出:
SAX解析开始
SAX解析结束
解析节点属性:
package test2;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
import test3.Book;
public class SAXParserHandler extends DefaultHandler
int bookIndex=0;//显示是第几本书的变量
/***
* 遍历xml的开始标签
*/
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException
// TODO Auto-generated method stub
//调用DefaultHandler类的startElement方法
super.startElement(uri, localName, qName, attributes);
//开始解析book元素的属性
if (qName.equals("book"))
bookIndex++;
System.out.println("开始遍历第"+bookIndex+"本书");
// //方法一:已知book元素下属性的名称,根据属性名称获取属性的值。
// String value=attributes.getValue("id");
// System.out.println("book的属性值为:"+value);
//方法二:book元素下舒心规定名称个数未知的情况
int num=attributes.getLength();
for (int i = 0; i < num; i++)
System.out.println("book元素的第"+(i+1)
+"个属性名:"+attributes.getQName(i));
System.out.println("book元素的第"+(i+1)
+"个属性值:"+attributes.getValue(i));
if (attributes.getQName(i).equals("id"))
book.setId(attributes.getValue(i));
else if(!qName.equals("book")&&!qName.equals("bookStore"))
System.out.print("节点名是:"+qName);
//qName.equals("name")时,向book中setName()
/***
* 遍历xml的结束标签
*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException
// TODO Auto-generated method stub
super.endElement(uri, localName, qName);
//判断是否针对一本书遍历结束
if (qName.equals("book"))
System.out.println("遍历结束");
System.out.println("结束遍历第"+bookIndex+"本书");
System.out.println();
/***
* 标识解析开始
*/
@Override
public void startDocument() throws SAXException
// TODO Auto-generated method stub
super.startDocument();
System.out.println("SAX解析开始");
/***
* 标识解析结束
*/
@Override
public void endDocument() throws SAXException
// TODO Auto-generated method stub
super.endDocument();
System.out.println("SAX解析结束");
/***
* ch 节点中的所有内容
* start 开始的节点
*
*/
@Override
public void characters(char[] ch, int start, int length) throws SAXException
// TODO Auto-generated method stub
super.characters(ch, start, length);
String value=new String(ch,start,length);
if (!value.trim().equals(""))
System.out.println("\\t节点值是:"+value);
输出:
SAX解析开始
开始遍历第1本书
book元素的第1个属性名:id
book元素的第1个属性值:1
节点名是:name 节点值是:冰与火之歌
节点名是:author 节点值是:乔治马丁
节点名是:year 节点值是:2014
节点名是:price 节点值是:99
遍历结束
结束遍历第1本书
开始遍历第2本书
book元素的第1个属性名:id
book元素的第1个属性值:2
节点名是:name 节点值是:秦腔
节点名是:author 节点值是:贾平凹
节点名是:price 节点值是:90
遍历结束
结束遍历第2本书
SAX解析结束
解析并存储XML结构:
新建Book类
package test3;
public class Book
private String id;
private String name;
private String author;
private String year;
private String price;
public String getId()
return id;
public void setId(String id)
this.id = id;
public String getName()
return name;
public void setName(String name)
this.name = name;
public String getAuthor()
return author;
public void setAuthor(String autor)
this.author = autor;
public String getYear()
return year;
public void setYear(String year)
this.year = year;
public String getPrice()
return price;
public void setPrice(String price)
this.price = price;
修改SAXParserHandler:
package test2;
import java.util.ArrayList;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
import test3.Book;
public class SAXParserHandler extends DefaultHandler
int bookIndex=0;//显示是第几本书的变量
//将character()中的value定义为全局变量
String value=null;
Book book=null;
private ArrayList<Book> bookList=new ArrayList<Book>();
public ArrayList<Book> getBookList()
return bookList;
/***
* 遍历xml的开始标签
*/
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException
// TODO Auto-generated method stub
//调用DefaultHandler类的startElement方法
super.startElement(uri, localName, qName, attributes);
//开始解析book元素的属性
if (qName.equals("book"))
book=new Book();
bookIndex++;
System.out.println("开始遍历第"+bookIndex+"本书");
// //方法一:已知book元素下属性的名称,根据属性名称获取属性的值。
// String value=attributes.getValue("id");
// System.out.println("book的属性值为:"+value);
//方法二:book元素下舒心规定名称个数未知的情况
int num=attributes.getLength();
for (int i = 0; i < num; i++)
System.out.println("book元素的第"+(i+1)
+"个属性名:"+attributes.getQName(i));
System.out.println("book元素的第"+(i+1)
+"个属性值:"+attributes.getValue(i));
if (attributes.getQName(i).equals("id"))
book.setId(attributes.getValue(i));
else if(!qName.equals("book")&&!qName.equals("bookStore"))
System.out.print("节点名是:"+qName);
//qName.equals("name")时,向book中setName()
/***
* 遍历xml的结束标签
*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException
// TODO Auto-generated method stub
super.endElement(uri, localName, qName);
//判断是否针对一本书遍历结束
if (qName.equals("book"))
bookList.add(book);
book=null;
System.out.println("遍历结束");
System.out.println("结束遍历第"+bookIndex+"本书");
System.out.println();
else if(qName.equals("name"))
book.setName(value);
else if(qName.equals("author"))
book.setAuthor(value);
else if(qName.equals("year"))
book.setYear(value);
else if(qName.equals("price"))
book.setPrice(value);
/***
* 标识解析开始
*/
@Override
public void startDocument() throws SAXException
// TODO Auto-generated method stub
super.startDocument();
System.out.println("SAX解析开始");
/***
* 标识解析结束
*/
@Override
public void endDocument() throws SAXException
// TODO Auto-generated method stub
super.endDocument();
System.out.println("SAX解析结束");
/***
* ch 节点中的所有内容
* start 开始的节点
*
*/
@Override
public void characters(char[] ch, int start, int length) throws SAXException
// TODO Auto-generated method stub
super.characters(ch, start, length);
value=new String(ch,start,length);
if (!value.trim().equals(""))
System.out.println("\\t节点值是:"+value);
修改SAXTest:
package test;
import java.io.IOException;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.SAXException;
import test2.SAXParserHandler;
import test3.Book;
public class SAXTest
public static void main(String[] args)
// 通过SAXParseFactory的静态newInstance()
//方法获取SAXParseFactory实例factory
SAXParserFactory factory=SAXParserFactory.newInstance();
//通过SAXParserFactory实例的newSAXParser()
//方法返回SAXParse实例parser
try
SAXParser parser= factory.newSAXParser();
//创建SAXParserHandler对象
SAXParserHandler handler=new SAXParserHandler();
parser.parse("books.xml", handler);
System.out.println("书的数量:"+handler.getBookList().size());
for(Book book: handler.getBookList())
System.out.println(book.getId());
System.out.println(book.getName());
System.out.println(book.getAuthor());
System.out.println(book.getPrice());
System.out.println(book.getYear());
System.out.println("-------------");
catch (IOException e)
// TODO Auto-generated catch block
e.printStackTrace();
catch (ParserConfigurationException | SAXException e)
// TODO Auto-generated catch block
e.printStackTrace();
输出:
SAX解析开始
开始遍历第1本书
book元素的第1个属性名:id
book元素的第1个属性值:1
节点名是:name 节点值是:冰与火之歌
节点名是:author 节点值是:乔治马丁
节点名是:year 节点值是:2014
节点名是:price 节点值是:99
遍历结束
结束遍历第1本书
开始遍历第2本书
book元素的第1个属性名:id
book元素的第1个属性值:2
节点名是:name 节点值是:秦腔
节点名是:author 节点值是:贾平凹
节点名是:price 节点值是:90
遍历结束
结束遍历第2本书
SAX解析结束
书的数量:2
1
冰与火之歌
乔治马丁
99
2014
2
秦腔
贾平凹
90
null
JDOM解析
包文件夹右键,Build Path,Add External Archices 导入JDOM jar包,但只是引用了路径,无法迁移到其他设备。
解决办法:在项目文件夹下新建一个文件夹,将jar包放进新建的文件夹之后再重新导入。右键jar包, Build Path》》》Add Path
package test;
import java.util.List;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import org.jdom2.Attribute;
import org.jdom2.Document;
import org.jdom2.Element;
import org.jdom2.JDOMException;
import org.jdom2.input.SAXBuilder;
public class JDOMTest
public static void main(String[] args)
//JDOM解析XML文件
//创建一个SAXBuilder对象
SAXBuilder saxbuilder=new SAXBuilder();
InputStream in;
try
//创建一个输入流,将xml文件加载到流中
in = new FileInputStream("src/res/books.xml");
//通过saxbuilder的build方法将输入流加载到saxbuilder中
Document document= saxbuilder.build(in);
//通过document对象获取xml文件的根节点
Element rootElement= document.getRootElement();
//获取根节点下的子节点的集合
List<Element> bookList=rootElement.getChildren();
//使用foreach循环解析
for (Element book : bookList)
System.out.println("开始解析第"+(bookList.indexOf(book)+1)
+"本书============");
//解析book的属性
List<Attribute> attrList=book.getAttributes();
// //知道节点属性名
// book.getAttribute("id");
//针对不清楚book节点下属性名和数量的情况
//遍历attrList
for (Attribute attr : attrList)
//获取属性名和属性值
String attrName=attr.getName();
String attrValue=attr.getValue();
System.out.println("属性名:"+attrName+"\\t属性值:"+attrValue);
//对book节点的子节点的节点名和节点值进行遍历
List<Element> bookChilds= book.getChildren();
for (Element child : bookChilds)
System.out.println("以上是关于JAVA解析XML文件的主要内容,如果未能解决你的问题,请参考以下文章