Spring Cloud Gateway Session
Posted 老邋遢
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring Cloud Gateway Session相关的知识,希望对你有一定的参考价值。
Spring Cloud Gateway Session
文章目录
一、楔子
1.1 为什么想要写此文档?
源于一次Zuul to Spring Cloud Gateway的升级,笔者开始大量查阅资料以增加对Spring Cloud Gateway的理解。
恰逢有此次Session,与诸位分享下历经短期调研后对Spring Cloud Gateway浅薄的理解。
本文还是着眼于平时开发时较难接触的诸如响应式Web框架设计、Spring WebFlux、Project Reactor等Spring官网文档没有详细讲述的内容。
和诸位分享知识的同时也对自身的学习做一个小结。假以时日,若有闲暇,再回来不断丰满完善此文(大概率不会)。
1.2 声明
因笔者从接触Spring Cloud Gateway至今(2021年8月25日),也不过半个月的时间,大部分的理解还是来源于官网的documentation或是一些相关的书籍(笔者期间参考过的书籍以及链接详见最下面“引用”部分)。所以有一些理解可能会有偏差,还希望看官们能谅解。
二、自底向上的概念讲解
2.1 什么是事件驱动模型?
一个简单的例子
“事件驱动模型”这个名词可能大家比较陌生,但是我们平时工作当中几乎无时无刻不在与它打着交道:
你每次鼠标的点击、移动、键盘按下等操作,都对应操作系统中的一个“事件(Event)”,然后应用程序会接收到对应的事件来进行处理。
Question:
大家电脑卡过吗?卡的时候打字按键顺序为什么不会丢失?
为了方便大家理解,笔者简单画了一下Windows系统中的事件(因为Windows是闭源的,所以下图为推断得出)
计算机还没有出现图形界面的时候,与操作系统交互都是由一条条的“指令”完成的。
当乔布斯看到了施乐(Xerox)公司生产的图形化界面主机时,于是便对此深深着迷,之后就有了苹果主机和我们使用的iPhone手机(TX行为),时至今日,苹果在图形化界面的展示和交互上,依旧是行业的翘楚。
不同于一条条DOS指令,图形化界面更加的方便,用户也能通过与图形界面交互在同一时间段内执行多个指令,这大大提升了人们的生产效率和计算机的普及度。
而Dos指令我们可以简化为以下流程:
上面这个模型有什么问题呢?
我们会发现在单个Terminal下我们只能等待系统执行完指令,期间我们不能干别的事情(阻塞),如果需要干别的事情,我们要么中断当前的指令,要么新启一个Terminal。
接下来我们看看图形界面的实现方式(以打Dota为例):
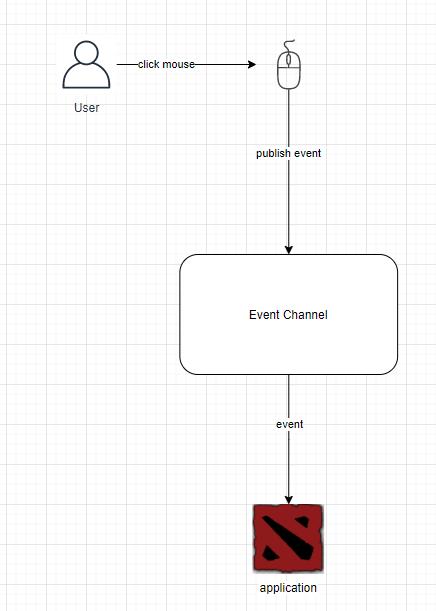
上图展示了我们图形化界面基于事件驱动的大致流程。
我们每点击一次鼠标都会产生一个鼠标事件(Event),接触过Java Swing或者AWT的同学应该会很熟悉。
然后该事件会被写入到系统的事件列表(或者是Channel中),然后对应的application会收到我们的指令,进行相应的工作。
Web下的事件驱动
通过上面的例子我们对基于事件驱动的模型有了大致的了解,这并不是一个新技术,只是新瓶装旧酒,应用到了我们的Web开发中,便成为一个新概念。
那么结合上面的讲述,我们传统Web的请求/响应模型就类似于DOS Terminal的形式,请求发送后,我们需要等待响应后才能进行后续操作。
同时之前使用的Zuul也是近似于这样的方式:
一个请求进来后Zuul会为该请求分配一条独立的线程,然后通过不同类型的过滤器来完成路由的功能。
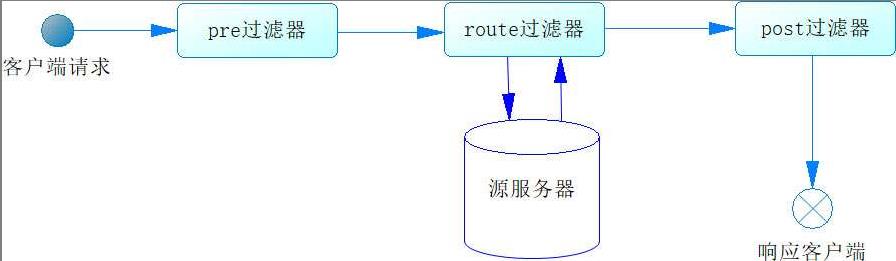
但是问题就在这里,这条线程会等route类型的过滤器去调用下游服务器,这显然是线程执行最为缓慢的一步。如果下游服务执行时间较长(这个在我们系统中已经见怪不怪了),就会导致线程积压,从而导致性能变慢。
接下来我们看下Spring Cloud Gateway的执行方式:
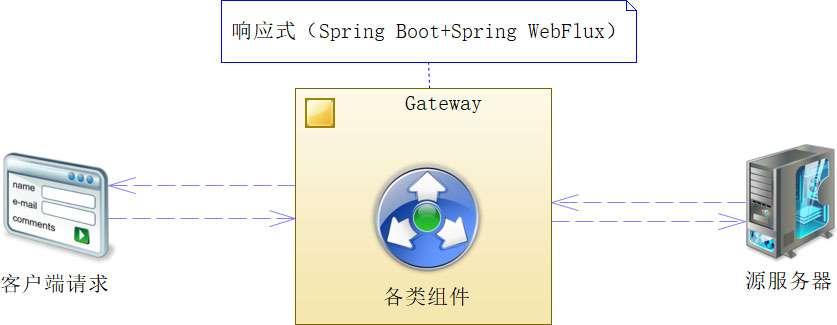
摘自《Spring Cloud微服务和分布式系统实践》一书中的上图用“各类组件”来高度概括了Gateway中响应式的处理流程,其实这样省略了WebFlux的精华部分,WebFlux是基于Reactor架构实现的,通过下图Reactor架构事件驱动&多路分发机制可以较为详细的了解处理流程。
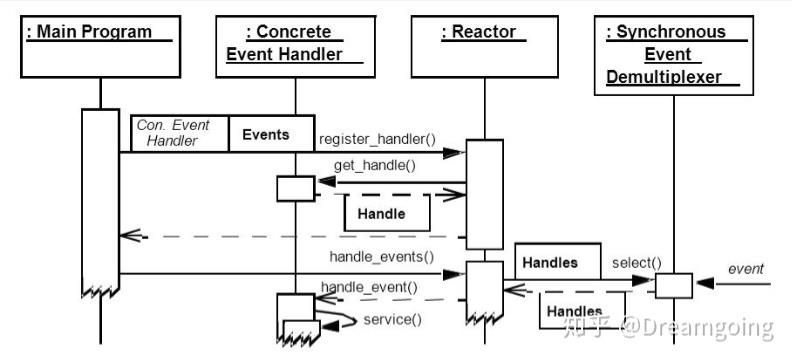
Reactor模式是一种典型的事件驱动的编程模型,Reactor逆置了程序处理的流程,其基本的思想即为Hollywood Principle— ‘Don’t call us, we’ll call you’.
上图可以主要关注Reactor和Event Demultiplexer交互的部分,这里的select用到了I/O多路复用的一些功能,这里先不赘述,在下一小节会单独讲解。
一个请求进来后,Gateway大致会经历以下流程
- 创建一条线程,这里类似于Zuul中的过滤器拦截的操作(具体会在后文介绍)
- 对源服务器转发请求,但是注意,Gateway并不会等待下游服务器的返回,而是将处理线程挂起,不再占用资源
- 待下游服务器返回消息后,再通过寻址的方式来响应之前客户端发送的请求
通过上面的流程,大家可以发现Gateway的线程在处理请求的时候,只是负责将请求转发至下游服务器,并没有等待执行完成的一个过程,因此Gateway线程活动时间更短,线程积压概率更低,故性能较于Zuul更好。
2.2 什么是IO多路复用?
上文提到了IO多路复用是并发事件驱动程序的基础,接下来我们就简单对IO多路复用进行一些前置知识的补充。
一句话解释:单线程或单进程同时监测若干个文件描述符是否可以执行IO操作的能力。
上面这句话可能比较抽象,但是没有关系,我们可以通过简单的示例来描述什么是IO多路复用:
以下是我手绘的示例,画的好不好凑合着看吧。
家里来客人了,奶奶让义哥烧5壶开水,聪明的义哥想出了三个方法:
-
自己挨个烧(BIO)
这种方法就是小明先烧A壶,等水开后再烧B壶,假定1壶水需要1小时,那么总计需要5小时
-
叫朋友一起来烧(Zuul)
小明发现水烧好后朋友都走了,于是机智的小明叫上朋友一起来烧,这样一个小时就烧好了,出于感谢,小明请四个朋友每人一杯咖啡,花费120元
-
义哥多路复用的烧(Gateway)
为了更加形象,我做了一个gif动图
这样5壶水同时烧,义哥只需要哪壶开了提哪壶即可,提升效率得同时也省下了咖啡钱
有一段网上IO多路复用的解释我觉得解释得很好,分享给大家:
“IO多路复用”:
IO指文件流或者网络流等一切流
多路指多个文件流,网络流等
复用指对单个线程的复用
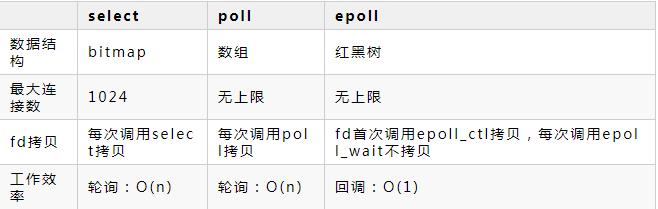
注意,多路复用高度依赖操作系统提供的IO复用能力,常见的各个OS都有自己的IO多路复用解决方案:
-
Linux: select、poll、epoll
-
MacOS/FreeBSD: kqueue
-
Windows/Solaris: IOCP
介于我们的应用基本是部署到Linux上的,所以这里只讨论Linux下的IO多路复用的三种实现方式区别。
这不是本文的重点,也就一笔带过了,如果感兴趣想要深入研究的同学可以看我引用中的几篇相关文章。
2.3 什么是WebFlux?
经过上面的初步学习我们已经掌握了事件驱动模型的思想,那么根据事件驱动衍生除了一种新的开发模式——“响应式编程”。
将来响应式编程会逐渐替代现有的开发模式,Spring官方现在也在大力推自己的响应式生态Spring Reactive。
在官网首页,Spring Reactive地位仅次于微服务
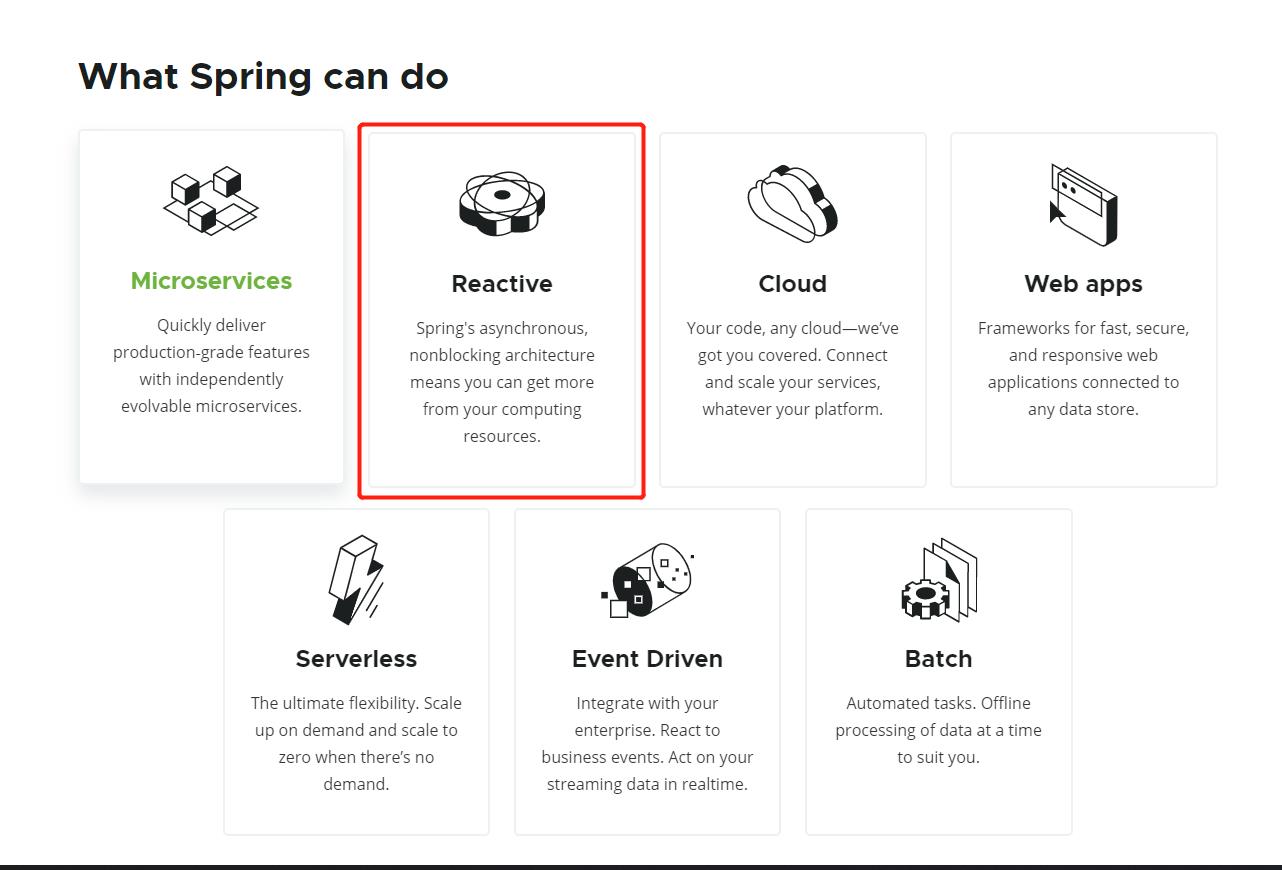
基于响应式编程思想,Spring演化除了自身的一套完整链条的微服务响应式编程框架:
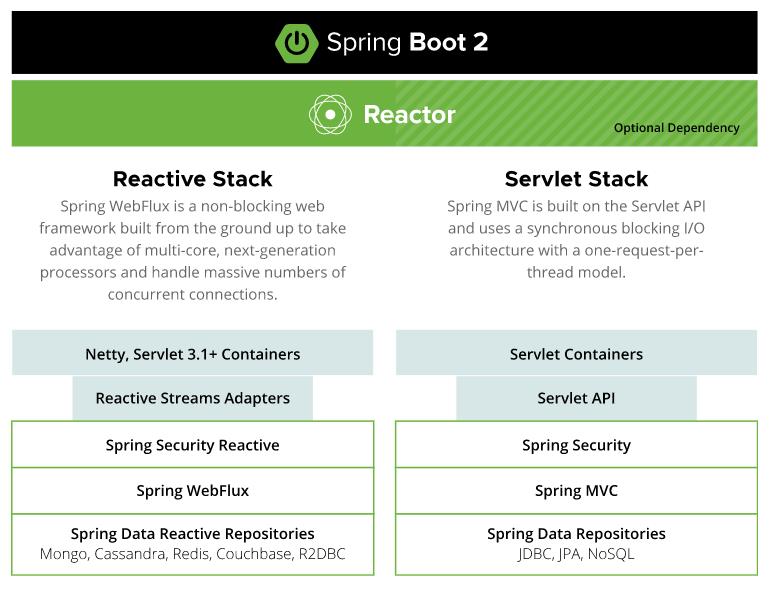
我们可以看到Spring官方罗列了从Web容器到数仓的完整响应式替换方案,这也是未来Web应用的新开发模式。
不过比较遗憾的是笔者本次只是做Gateway的替换,相信未来我们也会一步步将下游服务完成Reactive的全面升级。
同时从上图我们也可以看到本小节的主角——WebFlux,它是作为Spring MVC的替代方案而出现的。
Spring MVC作为一个老牌的开发模式,已经经过了岁月的考验,但是在流量日益增长的今日,尤其是需要构建高并发、高吞吐量的系统时显得有点力不从心。
Spring WebFlux 是 Spring Framework 5.0中引入的新的响应式web框架。与Spring MVC不同,它不需要Servlet API,是完全异步且非阻塞的,并且通过Reactor项目实现了Reactive Streams规范。
Spring WebFlux 用于创建基于事件循环执行模型的完全异步且非阻塞的应用程序。
Reactive Streams是一套用于构建高吞吐量、低延迟应用的规范。而Reactor项目是基于这套规范的实现,它是一个完全非阻塞的基础,且支持背压。
背压
在响应式的开发模式下,会有publish和subscribe两种操作(和MQ很像)。
在MQ中如果消费端很慢,但是消息发送的很快,就会导致消息大量的积压。
而背压就是在消息生产者和消费者间建立一种通信机制,如果生产者publish消息太快,消费者可以通过背压告诉生产者慢一点。
这就是Back Pressure,有点类似中国古代的一本预言书《推背图》,“万万千千说不尽,不如推背去归休”。
《推背图》作者在写完所有预言后,他的朋友过来推了一下他的背,让他去休息。
他的朋友就相当于subscriber,作者自己就相当于publisher。

Spring WebFlux基于Reactor实现了完全异步非阻塞的一套web框架,是一套响应式堆栈。
【spring-webmvc + Servlet + Tomcat】命令式的、同步阻塞的。
【spring-webflux + Reactor + Netty】响应式的、异步非阻塞的。
WebFlux中我们比较常见的两个对象分别是Mono和Flux,他们其实都实现了Publisher接口
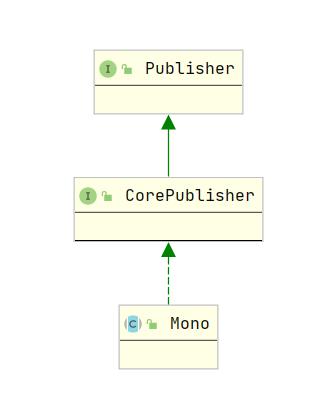
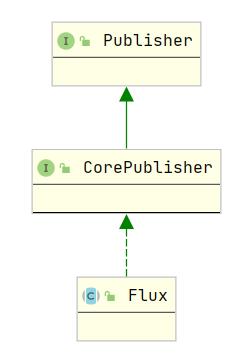
那有没有Subscriber接口呢?这个是有的:org.reactivestreams.Subscriber
但是WebFlux框架已经为我们实现了subscriber,我们需要关注的点就只是Publisher,当你publish后框架会subscribe并为你完成剩余的工作。
Mono和Flux是包装类,包装的对象即我们将来返回的对象,它是一个未来式,和CompletableFuture<Object>类似,它们之间唯一的区别在于
- Mono可以包装0~1个对象
- Flux可以包装0~N个对象
这个有点像Object和List<Object>的区别。
关于这里的设计Reactor Reference中也给出了解释:
This distinction carries a bit of semantic information into the type, indicating the rough cardinality of the asynchronous processing. For instance, an HTTP request produces only one response, so there is not much sense in doing a
countoperation. Expressing the result of such an HTTP call as aMono<HttpResponse>thus makes more sense than expressing it as aFlux<HttpResponse>, as it offers only operators that are relevant to a context of zero items or one item.
大致意思是(也就是机翻):
这种区别在类型中携带了一点语义信息,表明异步处理的粗略基数。 比如一个 HTTP 请求只产生一个响应,所以做一个计数操作没有多大意义。 因此,将此类 HTTP 调用的结果表示为 Mono<HttpResponse> 比将其表示为 Flux<HttpResponse> 更有意义,因为它仅提供与零项或一项的上下文相关的运算符。
下图展示了Flux是怎么去转换items的(即泛型里的对象)
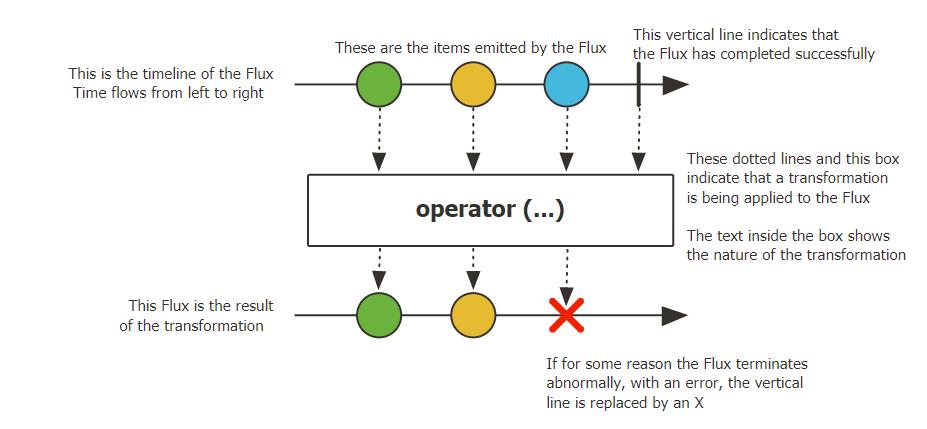
从左至右表示Flux的执行的时间线,上方代表Flux发布的元素列表,下方代表转换后的元素,虚线箭头代表转换已经发布到了Flux。
这个其实就是发布/订阅模式,和我们的MQ实现方式也很相像。
下图展示了Mono是怎么去转换一个item的(即泛型里的对象)
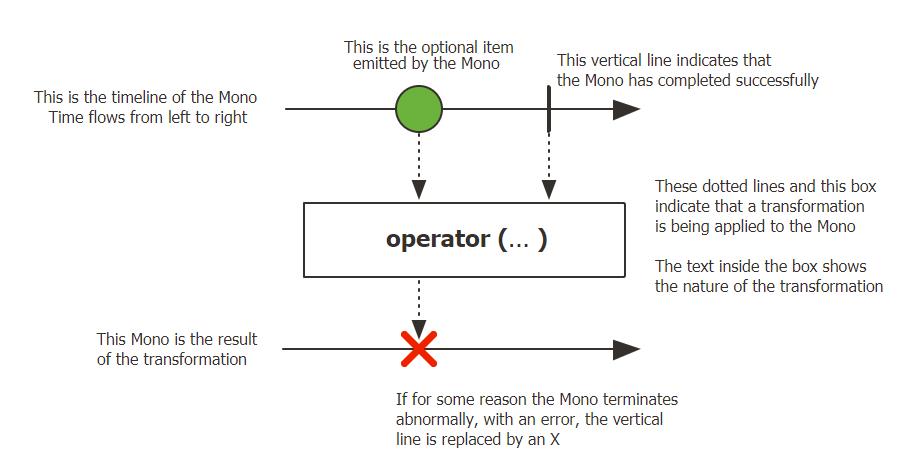
和上面就是一个和多个的区别,这里不再赘述。
小结一下:
WebFlux是事件驱动,响应式的Web框架。
需要澄清的一点是响应式的Web框架并没有提升单次请求响应的时间(这个取决于网络状态和下游服务),而是提升了系统的整体吞吐量(想想MQ就很好理解,同步向异步的转换,流量削峰等)。
三、 Spring Cloud Gateway 实战
这里不再贴代码了,希望在本地实验一把可以移步到代码仓库
这是一个相对完整的集成示例,包括但不限于以下组件:
- nacos-discovery
- nacos-config
- open-feign
- spring-cloud-gateway
- load-balancer
首先启动nacos,访问Nacos 配置主页,启动单机版nacos可以进入到bin目录下执行以下命令:
.\\startup.cmd -m standalone
我们可以看到基础配置和路由配置两个文件,进入路由配置gateway-routes.yml页面,我们可以看到路由配置如下:
spring:
cloud:
gateway:
routes:
- id: provider
uri: lb://provider
predicates:
- Path=/api/v1/**
filters:
- StripPrefix=2
- id是路由的唯一标识
- uri是路由地址
- predicate(谓语)是用于描述符合条件进行路由的说明
- filter(过滤器)这个就不用解释了
整理下就是:
path像/api/v1/**这样的请求会被路由到lb://provider,并且路由前会去掉两个前缀(也就是/api/v1)
那么Gateway是怎样通过简单的配置就能完成较为复杂的路由匹配和过滤的呢?
参考spring-cloud-gateway reference中的5~6章我们可以看到Gateway已经为我们实现了很多谓语和过滤器工厂,我们可以参考reference中的工厂进行简单配置后即可使用对应功能。
剩下的功能笔者不希望在本文中赘述,可以参考以下功能点逐个体验:
- 启动nacos + gateway + 一个provider,体验路由和过滤器以及整合nacos后的动态路由
- 启动nacos + gateway + N个provider,体验负载均衡
- BodyRewrite + 控制台可以看到WebFlux下怎么看responseBody
- filters包下变换每个filter顺序,通过控制台查看效果
- GlobalFiltersConfiguration中提供了另一种全局过滤器配置方式,同时也可以比较下与filters包下的执行顺序(filter下配置方式优先)
- PreFilter下与Resilience整合实现by path的限流,以及拦截后response输出
- bootstrap.yml中nacos shared-config功能
- SpringCloudGatewayDemoApplication中与feign整合需要配置的Converter
引用
书籍
《Java编程方法论: 响应式Spring Reactor 3设计与实现》知秋.著
博客&官网
以上是关于Spring Cloud Gateway Session的主要内容,如果未能解决你的问题,请参考以下文章
spring cloud gateway 某些路由中跳过全局过滤器
spring cloud gateway 报错 Unable to find GatewayFilterFactory with name