数据分析:新冠疫情实时数据爬取
Posted 晚风Serein
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析:新冠疫情实时数据爬取相关的知识,希望对你有一定的参考价值。
一、需求分析
报表需求
-
国内各省份**现有确诊数(=确诊-死亡-治愈)**所占比例
-
国内确诊总数、死亡总数、治愈总数、输入总数
-
国内近段时间每天的确诊数、疑似数趋势;累计确诊数、现有确诊数趋势;累计治愈数、累计死亡数趋势
-
全球各国现有确诊数所占比例
-
全球累计确诊总数、现有确诊总数、死亡总数、治愈总数
数据需求
- 国内各省份现有确诊、累计确诊、死亡、治愈;
- 国内总数现有确诊、累计确诊、死亡、治愈、输入;
- 国内近段时间每天的确诊数、疑似数、累计确诊数、现有确诊数、累计治愈数、累计死亡数
- 全球各国确诊、死亡、治愈;
- 全球总数确诊、死亡、治愈;
数据格式
Excel、SQLite
二、数据爬取分析处理
数据爬取
1、这里使用网易新闻里的实时疫情数据网站,接下来以国内各省份当日的疫情数据为例进行数据爬取。
https://wp.m.163.com/163/page/news/virus_report/index.html?nw=1&anw=1
2、通过网页检查,找到该网站的API数据接口

3、新建PyCharm项目,创建ChinaDataGet.py,导入我们需要的包
import json # json数据解析
import requests # 爬虫
import pandas as pd # 数据处理
import sqlite3 # sqlite数据库
4、在main函数中,声明数据接口url和请求头信息headers
if __name__ == '__main__':
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total'
headers =
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/102.0.5005.62 Safari/537.36 '
5、获取json数据模块:通过url和headers获取json。在main函数中打印data_json能否成功获取数据
# 获取json
def getHtml(url, headers):
re = requests.get(url=url, headers=headers)
# print(re.text)
re.encoding = re.apparent_encoding
status = re.status_code
# 通过json库将json格式的文本转换成python中的字典类型
data_json = json.loads(re.text)
# print(status)
return data_json
6、查看数据接口,找到中国每个省的当日数据。
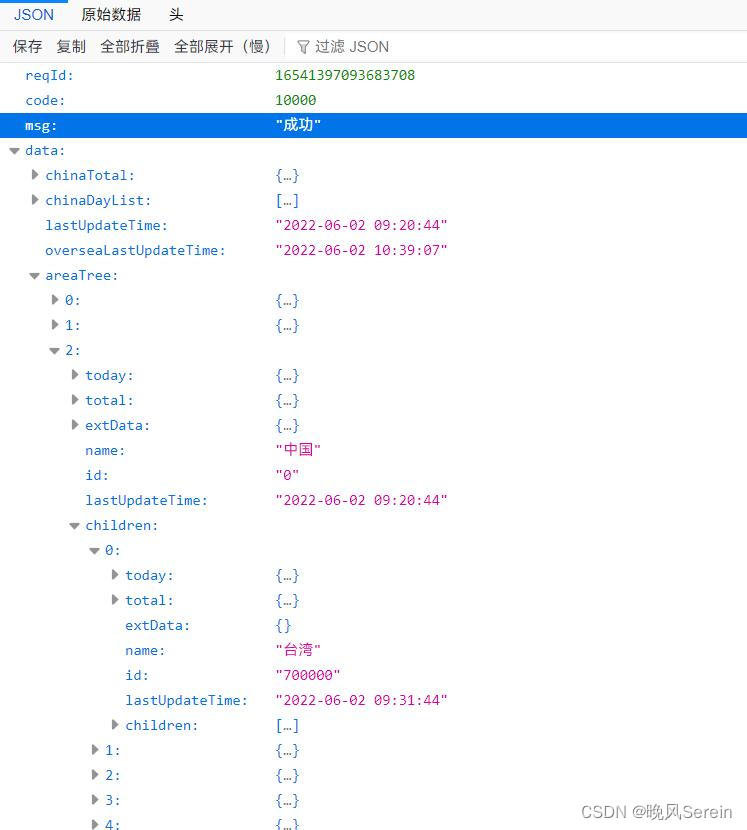
7、获取各省当日数据模块:在json中找到各省当日数据处理成DataFrame对象并返回。在main函数中打印today_df查看是否与原数据一致
# 获取各省份的当日数据
def getProvinceTodayData(data_json):
data = data_json['data']['areaTree'][2]['children']
today_df = pd.DataFrame(data)[['name', 'lastUpdateTime']]
# 获取当日的确诊、死亡、治愈
confirmData = pd.DataFrame([province['today']['confirm'] for province in data])
deadData = pd.DataFrame([province['today']['dead'] for province in data])
healData = pd.DataFrame([province['today']['heal'] for province in data])
# 将三列数据拼接到today_df,并计算现有确诊列
today_df['confirm'] = confirmData
today_df['dead'] = deadData
today_df['heal'] = healData
# 调整列的顺序
today_df = today_df[['name', 'confirm', 'dead', 'heal', 'lastUpdateTime']]
# 修改列名
colNames = ['省份', '确诊', '死亡', '治愈', '更新时间']
today_df.columns = colNames
return today_df
保存数据到Excel文件
将各省当日数据的DataFrame保存到excel文件,参数为数据dataframe、在excel中的表名sheetName、excel文件路径filePath。这里使用的是pandas中的ExcelWriter类,具体用法看代码
# 保存到excel
def saveProvinceTodayDataToExcel(df, sheetName, filePath):
# 使用pandas中的ExcelWriter类
writer = pd.ExcelWriter(filePath)
# 保存到excel,设置表名,不保存行索引
df.to_excel(writer, sheet_name=sheetName, index=False)
# 获取对应表名的工作表对象
worksheet = writer.sheets[sheetName]
# 将工作表的第4列宽设为20
worksheet.set_column(first_col=4, last_col=4, width=20)
# 保存writer对象, save()自带关闭操作
writer.save()
return
保存数据到SQLite数据库文件
1、初始化数据库文件,参数为数据库文件路径dbPath。需要导入sqlite3库。基本流程为创建数据库连接实例;创建游标实例;执行创建数据表语句;提交;关闭游标;关闭连接
# 初始化sqlite数据库
def initProvinceTodayDB(dbPath):
sql = '''
CREATE TABLE IF NOT EXISTS provinces_today
(
id integer primary key autoincrement,
proName text,
confirm integer ,
dead integer ,
heal integer ,
updateTime text
)
'''
conn = sqlite3.connect(dbPath)
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
cursor.close()
conn.close()
return
2、保存数据dataframe到数据库文件。基本流程为初始化数据库文件;创建数据库连接实例;创建游标实例;使用for循环将dataframe每一行的数据转换为列表;对每一行数据执行INSERT语句并提交;关闭游标;关闭连接
有个细节需要注意,dataframe中的数字是numpy.int64或numpy.int32类型的,这种类型的数据插入数据库时会造成乱码。所以需要将每一行数据的列表对应位置的元素强制转换为int类型
# 保存数据到数据库
def saveProvinceTodayDataToDB(today_df, dbPath):
# 初始化数据库
initProvinceTodayDB(dbPath)
# 连接数据库,打开游标
conn = sqlite3.connect(dbPath)
cursor = conn.cursor()
# 将各省份数据添加到数据库
for index in today_df.index:
# 这里取出来的数据中,确诊、死亡、治愈三个数据虽然看着是int类型,但实际是numpy.int64类型
# 若直接插入sqlite数据库会造成乱码
dataItem = today_df.iloc[index].tolist()
dataItem[1] = int(dataItem[1])
dataItem[2] = int(dataItem[2])
dataItem[3] = int(dataItem[3])
insert_sql = 'INSERT INTO provinces_today(proName, confirm, dead, heal, updateTime) VALUES(?, ?, ?, ?, ?)'
cursor.execute(insert_sql, dataItem)
conn.commit()
pass
# 关闭游标,关闭数据库
cursor.close()
conn.close()
其他的像全国累计数据,各省累计数据的获取方式都和上面相同,这里不再赘述。
以上是关于数据分析:新冠疫情实时数据爬取的主要内容,如果未能解决你的问题,请参考以下文章