关于输入语句格式化与变量定义类型不匹配导致结果错误
Posted xiaohajiang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于输入语句格式化与变量定义类型不匹配导致结果错误相关的知识,希望对你有一定的参考价值。
关于输入语句格式化与变量定义类型不匹配导致结果错误
一、事情的起始
一次实验课上,老师在黑板上写下几行代码,说到:“这是最近一个同学问我的一个问题,我想让你们也来看看。看看这个输入和输出是不是与预期的一样?如果不一样,那么问题出在什么地方呢?”
#include<stdio.h>
int main()
char a,b;
a=getchar();
scanf("%d",&b);
printf("%c %c",a,b);
return 0;
二、 原代码测试结果
老师的话无疑直接勾起了我的好奇心,于是我就直接开始测试起来。运行结果如下图所示:
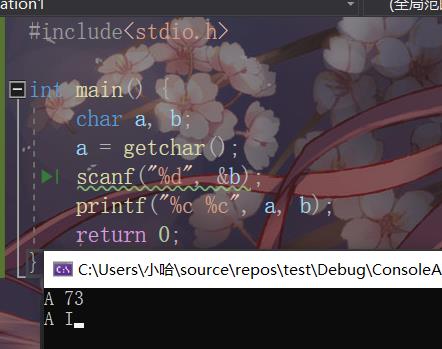
codeblocks 运行结果
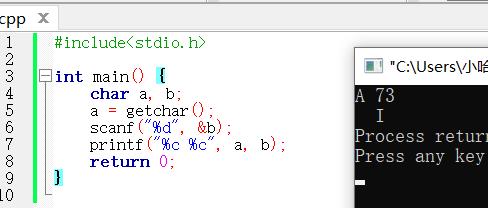
vs2019 运行结果
三、 结果分析
首先,我们先来明确预期结果,根据ASCII编码对照表可以得出我们预期期望输出的结果应当是a:=’ A ’ , b= 'I '。
显然 codeblocks 的运行结果是错误的,而 vs2019 的运行结果是正确的。在这里我们先讨论错误的运行结果,可是为什么出错是什么问题所导致的呢?我们可以通过单步调试寻找错,发现:
- a=getchar(); 该语句执行结束后,结果正确。 a的结果如预期所需
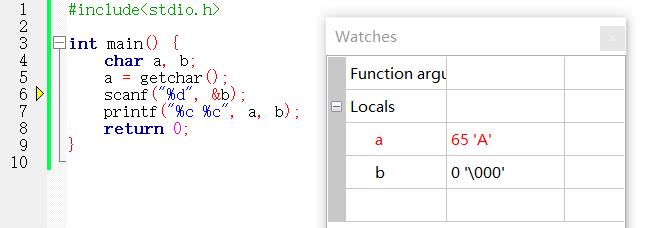
- scanf("%d",&b); 该语句执行后,发现b的值虽然变为预期所需,但是连带着a的值也跟着改变了。

我们可以先不妨大胆的猜测一下难道是不是 scanf 语句不能与 getchar 语句不能一起使用吗?
其实不然,将 vs2019 的运行结果与 codeblocks 的运行结果一对比就知语句的运行基理确确实实是与平常所学的是一样的,绝不可能是因为 scanf 语句不能与 getchar 语句一起使用。
既然单步调试发现问题出现在 scanf 语句上,那么便从该条语句上下功夫吧。皇天不负有心人,终于发现了一些线索。
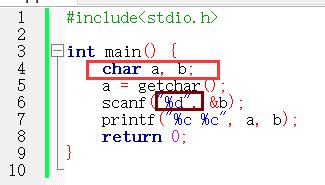
可见,我们的变量 a , b 都是 char 型,然而 scanf 却输入一个 int 型。关于这个就不得不提及内存的存储单元地址的分配,即编址方式。
四、内存的编制方式
1. 什么是存储单元地址
内存存储单元的空间位置是由 单元地址地址号 来表示的,而地址总线是用来指出存储单元地址号,根据这个地址可读出或者写入一个存储字。
2.什么是存储字
在内存中,一个存储单元可存储的一串二进制代码。不同的机器存储字长不同。
通常使用 8 位二进制表示一个字节。计算机系统既可以按字寻址,也可以按字节寻址。例如 IBM 370 机的字长为32位, 它按字寻址时,每一个存储字包含4个可独立寻址的字节(4B = 32b)。
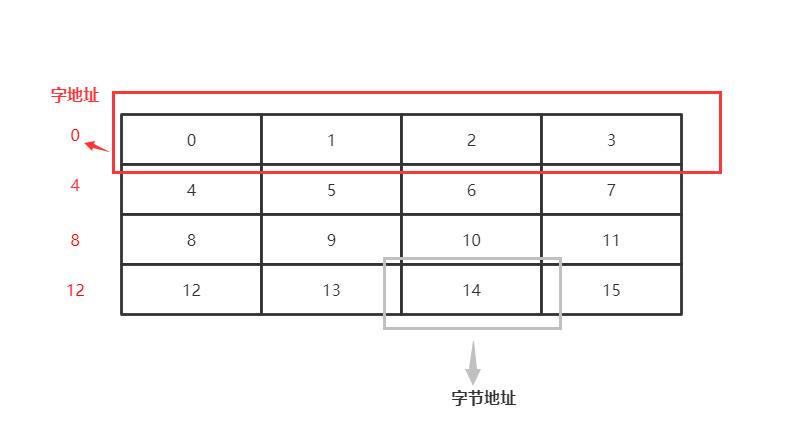
内存的存储方式分为:大端存储、小端存储。
大端存储:数据的低位存储在高地址,即低位数据存储在单元号大的位置上。
小端存储:数据的低位存储在低地址,即低位数据存储在单元号小的位置上。
IBM 370机内存地址分配示意图:(字地址是用该字高位字节的地址来表示)
五、错误分析
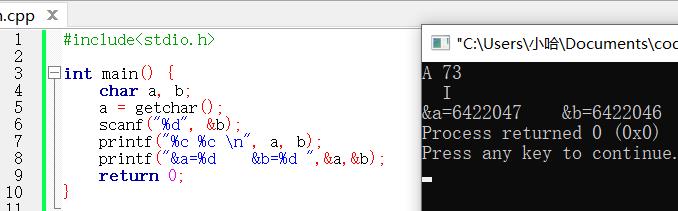
在C语言中,int 类型占四个字节,而 char 类型只占一个字节。由于题中代码变量 a、b都为 char 类型,且被定义在一起,故可见变量 a,b 的字节地址是连续且紧挨在一起的。scanf 语句读入了一个 int 型数据,但变量 b 是 char 型只被内存分配了一个字节,所以数据写入内存的时候也将改变变量 a 的值。
可验证猜想如下:
codeblocks 验证结果
vs2019 验证结果
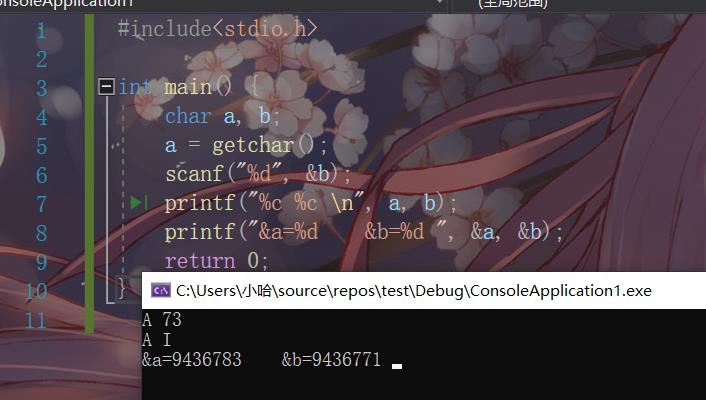
通过两个不同的编译器的输出结果可见, codeblocks 表明,由于变量 a,b 的字节地址连续,故在写入一个 4 字节数据的数据时导致变量 a 中的内容被改变; vs2019 表明,若变量 a, b 的字节地址不连续时,且不在同一字地址内时,输出结果正确。这也证明了我们的分析是正确的。
六、关于CB与VS编译器输出结果不同的论述
VS2019 即 Visual Studio 2019 编译器,是一款商业级用途的编译器。它是用于企业开发等的大型编译器,故其作为专业编译器不仅在编写代码时会实时提示代码的Error、Waring等信息,也会在代码运行时由于一些逻辑问题而导致结果错误的结果时,为了得到正确结果,编译器自己会自己额外做一些处理并提示出异常信息。
本题代码运行时VS2019 编译器异常提示:

然而 codeblocks 只是一款轻量级的编译器,所以不具有这些功能。
以上是关于关于输入语句格式化与变量定义类型不匹配导致结果错误的主要内容,如果未能解决你的问题,请参考以下文章