sql 如何过滤重复记录
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql 如何过滤重复记录相关的知识,希望对你有一定的参考价值。
请各位大侠帮忙了
问题1:对于以下几个记录
ID
123456
123123
123456
123456
123789
所有执行完SQL后的结果顺序与原ID顺序相同,另外由于涉及到数十万条记录的操作,要求速度要快
要求结果1:去除重复ID,显示记录结果为
123456
123123
123789
要求结果2:去掉重复ID,显示结果为
123123
123789 (与结果1不同的是将所有123456都去除了,而结果1进行了保存)
要求3:根据阈值的不同,决定是否进行重复过滤,例如阈值设置为2,由于123456的重复个数为3,那么由于3》2
结果为
123123
123789
如果阈值为4,由于3《4
结果为
123456
123123
123456
123456
123789
要求结果4:上面提到的过滤均是整个字段的过滤,如果有如下新的需求,只针对字段的前三位进行过滤,上面字段的前三位均是123,那么过滤结果是这6个字符串都是相同的(因为只取前三位作为比较依据),最终输出结果就是这六个字符串,
而如果选择前四位进行过滤,上面字段中有三个是相同的,1234开头的,最终输出结果就是这三个字符串
问题背景
在一个多表查询的sql中正常情况下产生的数据都是唯一的,但因为数据库中存在错误(某张表中存在相同的外键ID)导致我这边查询出来的数据就会有重复的问题
下面结果集中UserID:15834存在多个
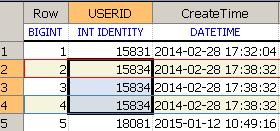
查询Sql如下:

SELECT *FROM (SELECT ROW_NUMBER() OVER ( ORDER BY T.USERID asc )AS Row
,T.USERID
,T.CreateTimeFROM UserInfo TLEFT JOIN DiseaseInfo i ON i.UserID=T.UserID
) TT WHERE TT.Row between 0 AND 20 ORDER BY UserID DESC

解决方法:
参考下面新的解决方案
在网络上了解到MSSql中通过关键字“PARTITION BY”可以将查询结果集进行分区处理,然后在查询结果集时就可以过滤掉重复的记录了(如果有指定分区字段则区ID相同)
通过更改后的Sql,在Over中添加PARTITION BY T.USERID以UserID进行分区,然后在查询结果集时通过DISTINCT ROW ,过滤掉重复的分区ID号

SELECT DISTINCT ROW ,*FROM (SELECT ROW_NUMBER() OVER (PARTITION BY T.USERID ORDER BY T.USERID asc )AS Row
,T.USERID
,T.CreateTimeFROM UserInfo TLEFT JOIN DiseaseInfo i ON i.UserID=T.UserID
) TT WHERE TT.Row between 0 AND 12 ORDER BY UserID DESC

查询时未过滤重复分区IDDISTINCT ROW ,下面的结果集跟上面的结果集不同(Row是进行过分区的所有有重复Row)
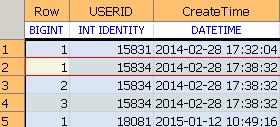
在查询结果集时过滤掉重复的分区ID号 DISTINCT ROW ,
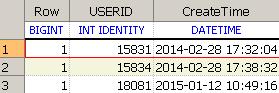
新解决方案:
由于在Sqlserver中如果多表联合查询中除非所有的字段都完全相同否则在使用DISTINCT 用进行去重时还是会当成两个不同的数据集进行处理,因此DISTINCT会失效即
如下面的结果集,虽然 USERID和其他字段内容相同但HID是不相同的所以无法使用DISTINCT进行去重
出现这种问题是因为数据库设计的错误(正常情况下关联表HospitalInfo中只可能存在一条ClinicInfo表对应的记录)
Sql语句:

SELECT *FROM (SELECT ROW_NUMBER() OVER ( order by T.USERID asc )AS Row
,T.USERID
,LEFT(T.Patient_Tel1,5)+'00000000' AS Tel
,T.CreateTime
,h.HName
,h.HID
fromUserInfo TLEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1AND t.UserID>=17867 AND T.UserID<=17875--(T.Patient_Tel1 like '%13800000000%')) TT WHERETT.Row between 0and20

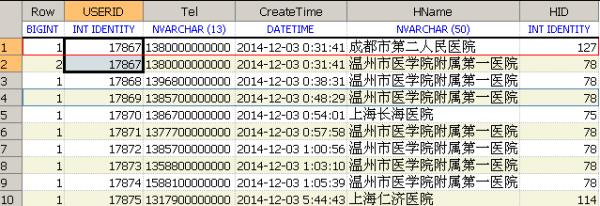
可以看到上面的结果集中Row是有重复的,其他Row为2的是跟第一个是重复的
因为数据库涉及到其他业务和人员因此我只能提交该问题给相关的技术,但在该问题解决前不能影响到我这边也出现此问题
于是在原sql基础上进行处理,虽然HospitalInfo表中不重复记录但表的自增ID是不可能重复的那我只需要最新的一条记录即可
如果通过DISTINCT过进行去重则就无法成功,因为数据存在差别,可以看到第一条和最后一条数据还是重复的

SELECT DISTINCT row,*FROM (SELECT ROW_NUMBER() OVER ( partition by T.USERID order by T.USERID asc )AS Row
,T.USERID
,LEFT(T.Patient_Tel1,5)+'00000000' AS Tel
,T.CreateTime
,h.HName
,h.HID
fromUserInfo TLEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1AND t.UserID>=17867 AND T.UserID<=17875--(T.Patient_Tel1 like '%13800000000%')) TT WHERE--row=1 ANDTT.Row between 0 and 20

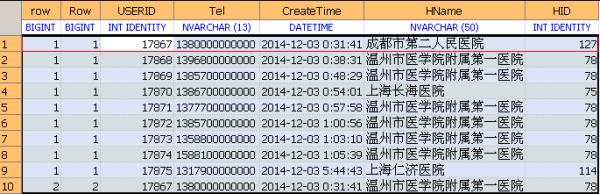
更改后的Sql

SELECT *FROM (--partition by T.USERID 以UserID对结果集进行分区SELECT ROW_NUMBER() OVER ( partition by T.USERID order by T.USERID asc )AS Row
,T.USERID
,LEFT(T.Patient_Tel1,5)+'00000000' AS Tel
,T.CreateTime
,h.HName
,h.HID
fromUserInfo TLEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1AND t.UserID>=17867 AND T.UserID<=17875--(T.Patient_Tel1 like '%13800000000%')) TT WHERE--因为之前已经以UserID对结果集进行分区,所以如果存在重复的字段则row的值会不相同--row=1 ANDTT.Row between 0 and 20

USERID=17867相同经过分区后会存在不同的Row值
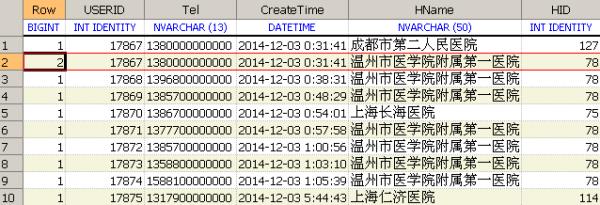
在对结果集再次过滤时添加条件 : row=1,已经将重复记录中旧的数据过滤掉了 (HID:78)
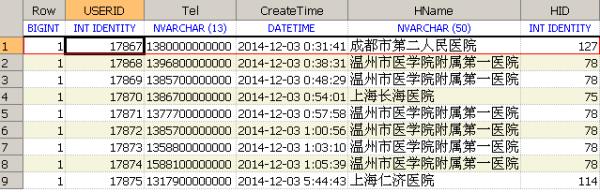
根据新的解决方案解决了重复的问题,但又出现的新的问题即Row分区后都是重复的,而我再进行分页的时候就无效了(因为此时结果集中的Row都是为1)
解决方案:在结果集再加一层查询并加上ID号然后再对结果集进行分页处理

-- 新增一层查询解决过滤掉重复数据后无法分页的问题SELECT * FROM (SELECT ROW_NUMBER() OVER (ORDER BY userid) AS RowNum,*FROM (--partition by T.USERID 以UserID对结果集进行分区SELECT ROW_NUMBER() OVER ( partition by T.USERID order by T.USERID asc )AS Row
,T.USERID
,LEFT(T.Patient_Tel1,5)+'00000000' AS Tel
,T.CreateTime
,h.HName
,h.HID
fromUserInfo TLEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1AND t.UserID>=17867 AND T.UserID<=20875--(T.Patient_Tel1 like '%13800000000%')) TT
)AS TWHERE--过滤重复数据Row=1--对结果进行分页AND RowNum between 13 and 24

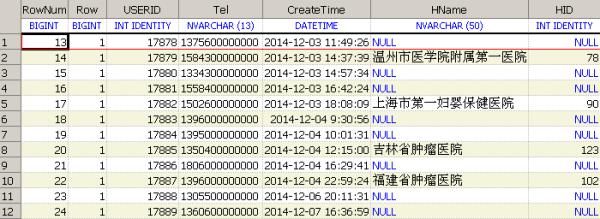
参考:
MSDN: OVER 子句 (Transact-SQL)
stackoverflow sql query distinct with Row_Number
SQL Trick: row_number() is to SELECT what dense_rank() is to SELECT DISTINCT
参考技术A 要求结果1:如果只取ID列 select distinct ID from table1
如果还有其他列,在id相同情况下,取col1最小的记录。
select ID,col1 from table1 t1 where not exists(select * from table1 where ID=t1.ID and col1>t1.col1)
要求结果2:
select ID from table1 t1 where not exists (select * from table1 where ID=t1.ID)
select ID from table1 t1 where (select count(*) from table1 where ID=t1.ID)=1
要求3:例如阈值设置为2
select ID from table1 t1 where (select count(*) from table1 where ID=t1.ID)<=2
要求结果4:选择前四位进行过滤
select distinct ID=left(ID,4) from table1
只要把前面语句中的ID换成left(ID,4)就可以了。本回答被提问者采纳 参考技术B 1楼第一个结果还不错,也可以用
SELECT First(test1.id)
FROM test1
GROUP BY test1.id
后面的用HAVE子句比较方便, 不用2个SQL
结果2
SELECT First(test1.id)
FROM test1
GROUP BY test1.id
HAVING Count(test1.id)=1;
结果3
SELECT First(test1.id)
FROM test1
GROUP BY test1.id
HAVING Count(test1.id)<=2;
<=阈值
结果4 同样用LEFT:
1
SELECT First(test1.id)
FROM test1
GROUP BY left(test1.id,4)
后面的用HAVE子句比较方便, 不用2个SQL
结果2
SELECT First(test1.id)
FROM test1
GROUP BY left(test1.id,4)
HAVING Count(left(test1.id,4))=1;
结果3
SELECT First(test1.id)
FROM test1
GROUP BY left(test1.id,4)
HAVING Count(left(test1.id,4))<=2;
sql查询重复记录删除重复记录方法大全
查找所有重复标题的记录:
SELECT *
FROM t_info a
WHERE ((SELECT COUNT(*)
FROM t_info
WHERE Title = a.Title) > 1)
ORDER BY Title DESC
一。查找重复记录
1。查找全部重复记录
Select * From 表 Where 重复字段 In (Select 重复字段 From 表 Group By 重复字段 Having Count(*)>1)
2。过滤重复记录(只显示一条)
Select * From HZT Where ID In (Select Max(ID) From HZT Group By Title)
注:此处显示ID最大一条记录
二。删除重复记录
1。删除全部重复记录(慎用)
Delete 表 Where 重复字段 In (Select 重复字段 From 表 Group By 重复字段 Having Count(*)>1)
2。保留一条(这个应该是大多数人所需要的 ^_^)
Delete HZT Where ID Not In (Select Max(ID) From HZT Group By Title)
注:此处保留ID最大一条记录
1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断
select * from people
where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录
delete from people
where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)
3、查找表中多余的重复记录(多个字段)
select * from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
4、删除表中多余的重复记录(多个字段),只留有rowid最小的记录
delete from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
5、查找表中多余的重复记录(多个字段),不包含rowid最小的记录
select * from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
补充:
有两个以上的重复记录,一是完全重复的记录,也即所有字段均重复的记录,二是部分关键字段重复的记录,比如Name字段重复,而其他字段不一定重复或都重复可以忽略。
1、对于第一种重复,比较容易解决,使用
select distinct * from tableName
就可以得到无重复记录的结果集。
如果该表需要删除重复的记录(重复记录保留1条),可以按以下方法删除
select distinct * into #Tmp from tableName
drop table tableName
select * into tableName from #Tmp
drop table #Tmp
发生这种重复的原因是表设计不周产生的,增加唯一索引列即可解决。
2、这类重复问题通常要求保留重复记录中的第一条记录,操作方法如下
假设有重复的字段为Name,Address,要求得到这两个字段唯一的结果集
select identity(int,1,1) as autoID, * into #Tmp from tableName
select min(autoID) as autoID into #Tmp2 from #Tmp group by Name,autoID
select * from #Tmp where autoID in(select autoID from #tmp2)
以上是关于sql 如何过滤重复记录的主要内容,如果未能解决你的问题,请参考以下文章