c++面向对象高级编程(上)
Posted mr.chenyuelin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了c++面向对象高级编程(上)相关的知识,希望对你有一定的参考价值。
原视频:https://www.bilibili.com/video/BV1Nq4y1E7Zi?p=4
文章目录
头文件结构
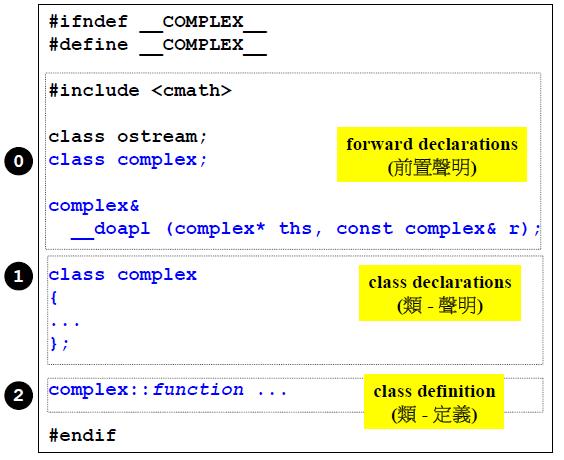
防卫式声明,防止头文件被重复包含

模板,类似于泛型
template<typename T>//
内联函数
在类声明内定义的函数,自动成为inline函数;在类声明外定义的函数,需要加上inline关键字才能成为inline函数.

在编译时未必会真正被编译为inline函数.因此如果函数足够简单,我们就把它声明为inline就好了.
构造函数
C++的构造函数也可以有默认实参.C++构造函数的特殊之处在于列表初始化(initialization list).
#include <iostream>
using namespace std;
class Test
public:
int a;
int b;
//使用初始化列
Test(int m = 0,int n = 0):a(m),b(n)
;
int main()
Test test(1, 2);
Test test2;
Test* t = new Test(2, 3);
cout << test.a << " " << test.b << endl;
cout << t->a << " " << t->b << endl;
return 0;
使用列表初始化的效率比直接在大括号里赋值更高,应尽量使用列表初始化.
常量成员函数
若成员函数中不改变成员变量,应加以const修饰
#include <iostream>
using namespace std;
class Complex
public:
//使用初始化列
Complex(int m = 0,int n = 0):real(m),imag(n)
//当成员函数中不改变成员变量使用const修饰,参数列表之后修饰
int getReal() const return real;
int getImag() const return imag;
private:
int real, imag;
;
int main()
const Complex com(1, 2);//如果定义变量时使用const,而成员函数没有使用const会报错
cout<<com.getReal()<<endl;
return 0;
就是如果你已经确定该函数不会对变量改变就修饰为const,这样外部用的时候有没有修饰为const都不会报错
传值、传指针、传引用的区别
传值是形参开辟一个新空间,地址跟实参不一样而值一样,所以形参的改变不会影响实参
传指针是传地址,形参拥有实参一样的地址,所以形参的改变会影响实参
传引用可以看做变量的别名,本质还是传址,不过两点优点:
1.比传指针安全,我们操作时只能改地址里的值不会改地址,而指针可以修改指向的地址和值,万一你把指向的地址给改了那不就完蛋了,
2.而且形式上比传指针简洁很多
3.传引用速度比传值速度快,因为本质上还是传地址只需4个字节,传值可能会很大
#include<iostream>
using namespace std;
// 传指针
void fun_2(int *num)
*num = 200; // *num就是根据指针num找原来位置的变量
cout<<"In function 2 num = "<<*num<<endl;
// 传引用
void fun_3(int &num)
num = 300; // 引用的操作看起来就像是直接赋值一样
cout<<"In function 3 num = "<<num<<endl;
//传引用const修饰,代表该变量不可修改
void fun_4(const int &num)
cout << num << endl;
int main()
int num = 0;
// 传指针
cout<<"Before function 2 num = "<<num<<endl;
fun_2(&num); // 地址传过去
cout<<"After function 2 num = "<<num<<endl<<endl;
// 传引用
cout<<"Before function 3 num = "<<num<<endl;
fun_3(num);
cout<<"After function 3 num = "<<num<<endl<<endl;
return 0;

若不希望在函数体内对输入参数进行修改,应使用const修饰输入参数,改了就编译出错
若函数的返回值是原本就存在的对象,则应以引用形式返回.
若函数的返回值是临时变量,则只能通过值传递返回.
另外补充引用做返回值的好处:

函数内部返回类型为值,而实际函数返回类型为引用,好像有点不匹配?
使用引用传递参数和返回值的好处在于传送者无需知道接收者是否以引用形式接收
友元函数
友元函数不受访问级别的控制,可以自由访问对象的所有成员.
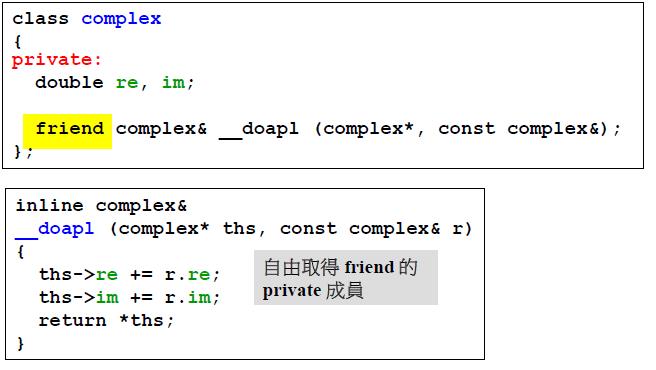
同一类的各个对象互为友元,因此在类定义内可以访问其他对象的私有变量

complex c1, c2;
c2.func(c1); // 因为c1和c2互为友元
运算符重载
就是要为自定义类型定义操作符的规则
实现一个操作符重载的方式通常分为两种情况:
1.将操作符重载实现为类的成员函数;
2.操作符重载实现为非类的成员函数(即全局函数)。
两者只能写一个
#include<iostream>
using namespace std;
class Person
public:
int age;
Person(int age)
this->age = age;
//将操作符重载实现为类的成员函数
bool operator==(const Person& ps)
//this当前对象指针
if (this->age == ps.age)
return true;
else
return false;
;
//操作符重载实现为非类的成员函数(即全局函数)
bool operator>(Person const& p1, Person const& p2)
if (p1.age > p2.age)
return true;
else
return false;
int main()
Person p1(10);
Person p2(20);
if(p1 == p2)
cout << "p1 is equal with p2." << endl;
else
cout << "p1 is not equal with p2." << endl;
return 0;
写成类成员函数的前提:使用时操作符左侧必须为该类对象否则不会调用
但其实还是写成成员函数里面得用比较多,因为数据一般修饰为private,类外就访问不到了
操作符重载的限制
实现操作符重载时,需要注意:
1.重载后操作符的操作数至少有一个是用户定义类型;
2.不能违反原来操作数的语法规则;
3.不能创建新的操作符;
4.不能重载的操作符包括(以空格分隔):sizeof . .* :: ?: RTTI类型运算符
5.=、()、[]、以及 ->操作符只能被类的成员函数重载
在类外声明函数重载<<
与重载+的考虑方法类似,<<操作符通常的使用方式是cout<<c1而非c1<<cout,因此不能使用成员函数重载<<运算符.
考虑到形如cout<<c1<<c2<<c3的级联用法,重载函数的返回值为ostream&而非void.

补充:

返回这样的形式是创建临时变量尽管它没有名字,所以返回值只能是值,不能加引用
类设计的小总结

带指针成员变量的类----以String类为例
一般都要有3个函数,分别是拷贝构造函数、拷贝赋值函数、析构函数

深拷贝和浅拷贝区别
浅拷贝只是增加了一个指针指向已存在的内存地址,仅仅是指向被复制的内存地址,如果原地址发生改变,那么浅复制出来的对象也会相应的改变。深拷贝是增加了一个指针并且申请了一个新的内存,使这个增加的指针指向这个新的内存。
记忆:浅拷贝是同一块内存空间,而深拷贝不是同一块内存
为什么我要写这3个而不用系统自带呢
我们要实现深拷贝,系统自带的是浅拷贝,会出现内存泄漏
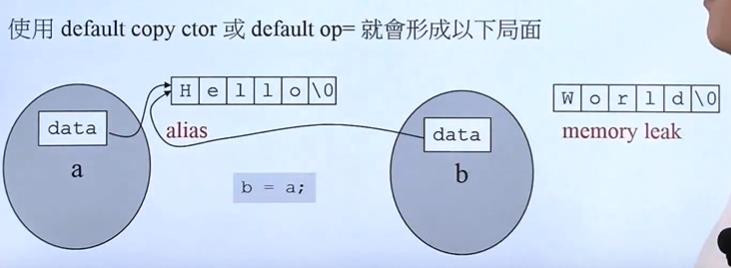
浅拷贝直接将b指针指向a指向的空间导致原有的内存空间泄漏,而且a指针改变也会影响b
构造函数和析构函数
构造函数执行数据的深拷贝,需申请内存空间
析构函数是内存空间的释放,程序结束时自动调用

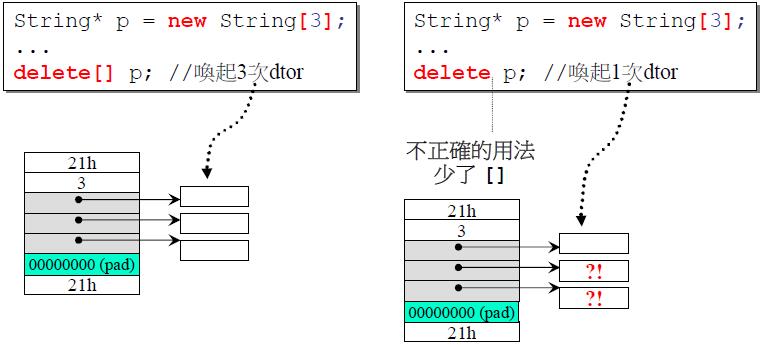
值得注意的是使用delete[]操作符释放数组内存,若直接使用delete操作符释放数组内存虽然能够通过编译,但有可能产生内存泄漏.
拷贝构造函数和拷贝赋值函数
String s1 = "hello";
String s2(s1); // 拷贝1: 调用拷贝构造函数
String s3;
s3 = s1; // 拷贝2: 调用拷贝赋值函数
String s4 = s1; // 拷贝3: 调用拷贝构造函数
结论很明显,如果是在初始化时调用拷贝构造函数,不是初始化调用拷贝赋值函数

拷贝赋值函数中要检测自我赋值,这不仅是为了效率考虑,也是为了防止出现bug.
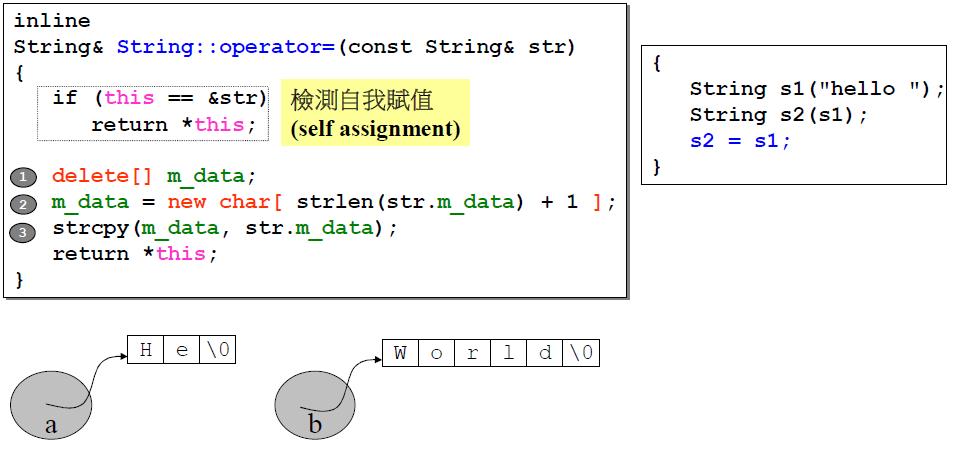
检测自我赋值的意思就是两个指针本来是指向同一块空间,第一步删除后,第二步就找不到原来那块数据了
堆栈与内存管理
栈是函数内部定义的临时变量,函数结束后自动释放
堆是指由操作系统提供的一块内存空间,全局变量就是在堆上或程序可动态分配从其中获得
全局变量和静态变量其生命在在整个程序结束之后才结束,其作用域是整个程序.
而动态分配的要在作用域之前释放内存,否则内存泄漏,内存泄漏因为指针在函数结束之后,指针为空了,但内存忘记释放了
class Complex … ;
// ...
Complex* p = new Complex;
// ...
delete p;
new和delete过程的内存分配
new操作先分配内存,再调用构造函数.
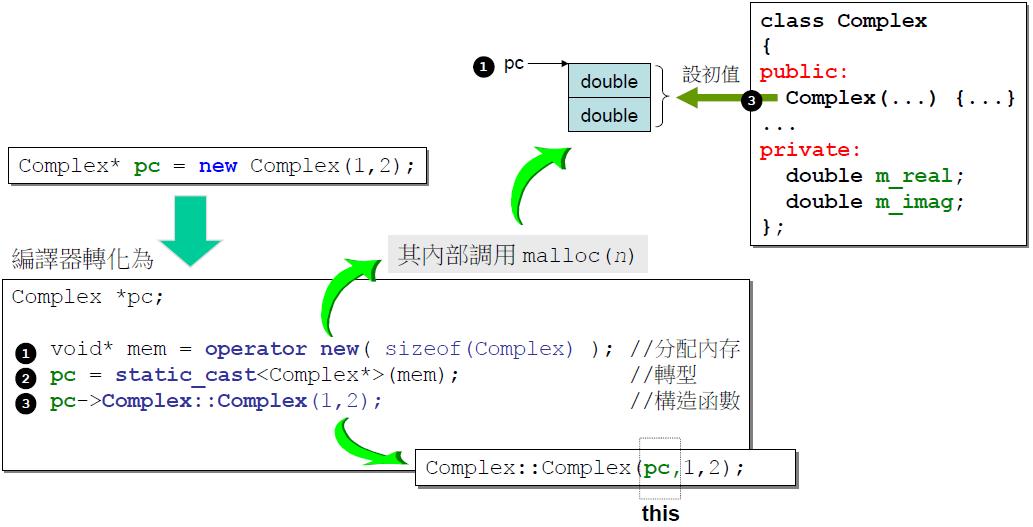
delete操作先调用析构函数,再释放内存.
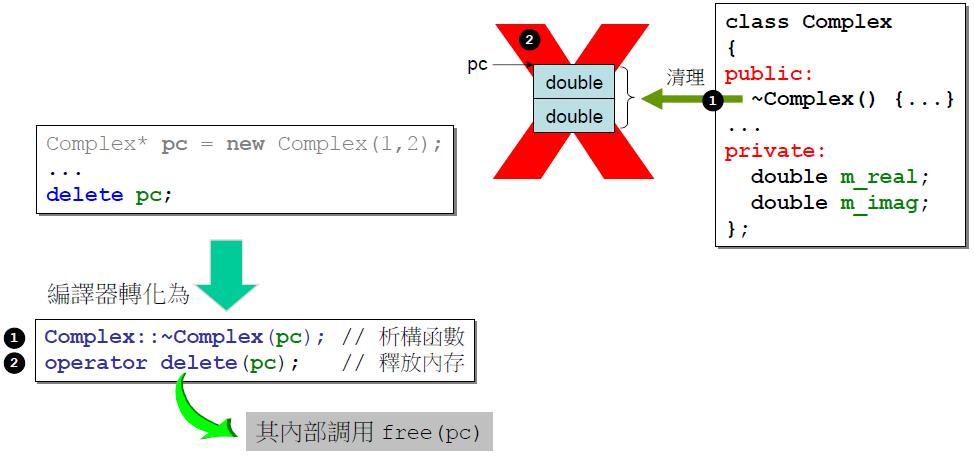
new array与delete array要配对。 delete操作符仅会调用一次析构函数,而delete[]操作符依次对每个元素调用析构函数.对于String这样带有指针的类,若将delete[]误用为delete会引起内存泄漏.
static
类外使用类里的成员:classname::
1.对于类,非静态成员是在内存中每个对象均存在一份,而静态成员中内存中仅有一份
2.非静态成员函数需通过this指针调用,而静态函数不用
3.static成员变量需在类外定义进行初始化
4.static成员函数可以通过对象调用,也可以通过类名调用
5.非静态函数可以访问静态成员,静态成员函数不能访问非静态成员
class Account
public:
static double m_rate;
static void set_rate(const double& x) m_rate = x;
;
double Account::m_rate = 8.0;
int main()
Account::set_rate(5.0);
Account a;
a.set_rate(7.0);
总之,静态成员函数主要为了调用方便,不需要生成对象就能调用
单例模式的应用

类之间的3种关系
复合composition、委托、继承
复合
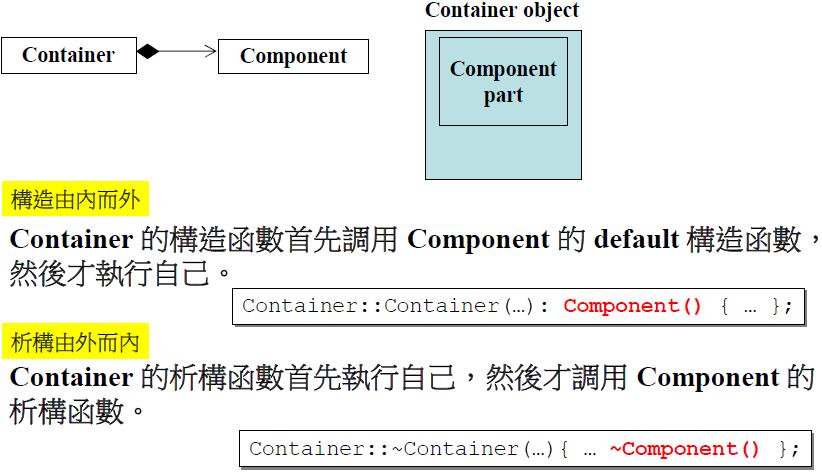
复合表示一种has-a的关系,STL中queue的实现就使用了复合关系.这种结构也被称为adapter模式.

复合关系下构造由内而外,析构由外而内:
委托
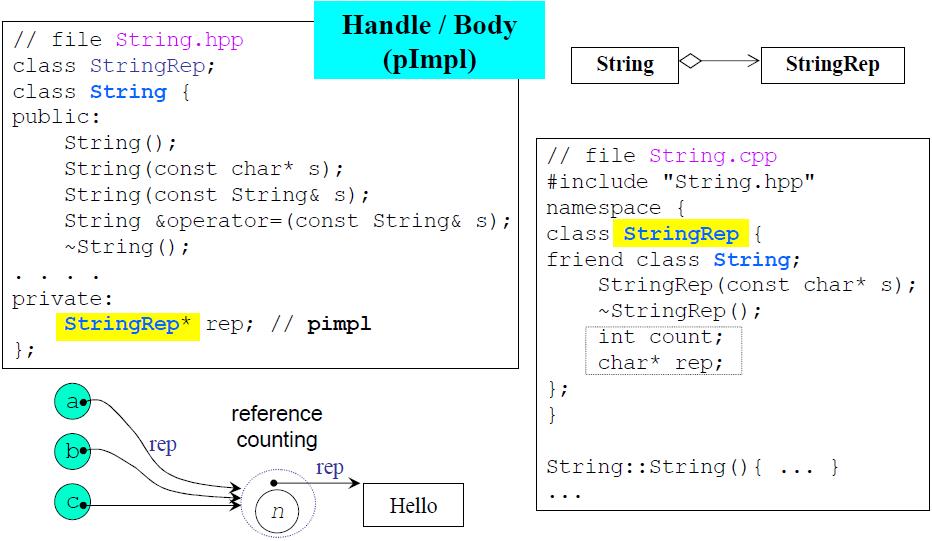
委托通过一个指针将类的定义与类的实现分隔开来,也被称为编译防火墙.
继承
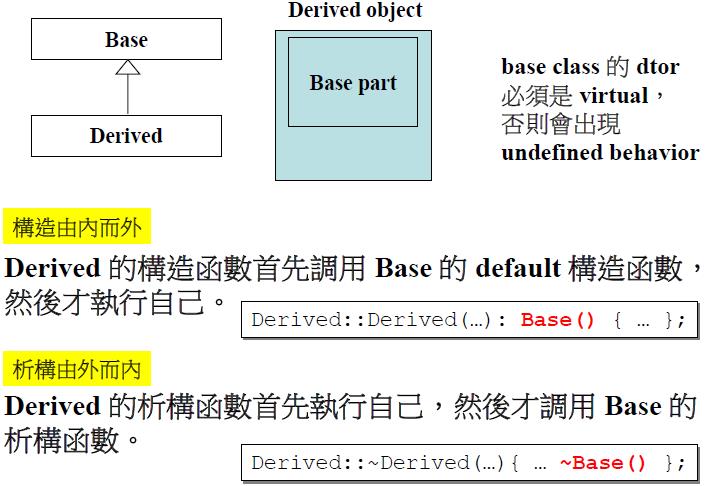
继承表示一种is-a的关系,STL中_List_node的实现就使用了继承关系.

继承关系下构造由内而外,析构由外而内:
以上是关于c++面向对象高级编程(上)的主要内容,如果未能解决你的问题,请参考以下文章