机器学习-随手笔记二(卷积神经网络TensorFlow和IV值计算)
Posted 龙鸣丿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习-随手笔记二(卷积神经网络TensorFlow和IV值计算)相关的知识,希望对你有一定的参考价值。
目录
卷积神经网络:
简介:
简称CNN,20世纪60年代,Hubel和Wisesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效的降低反馈神经网络的复杂性,继而提出了卷积神经网络。


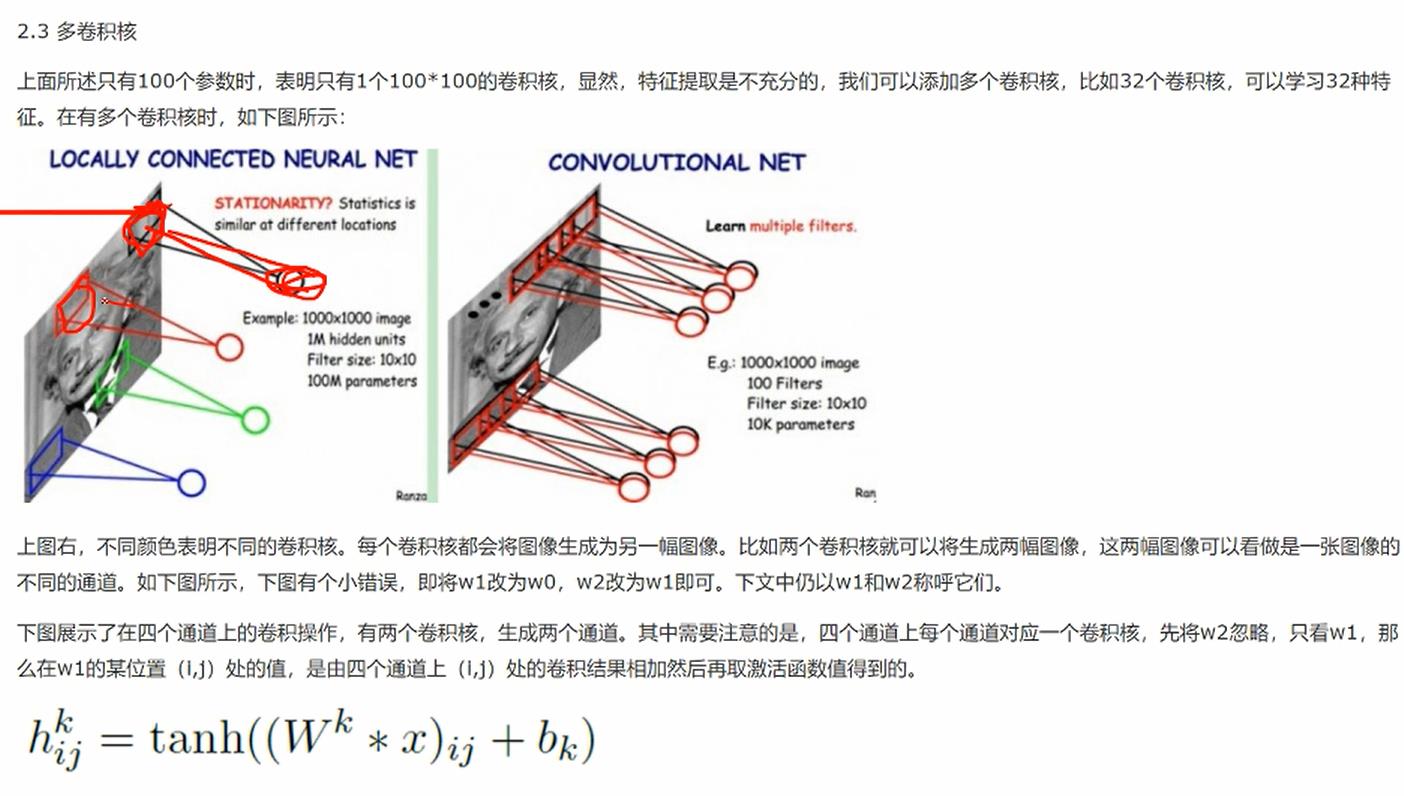
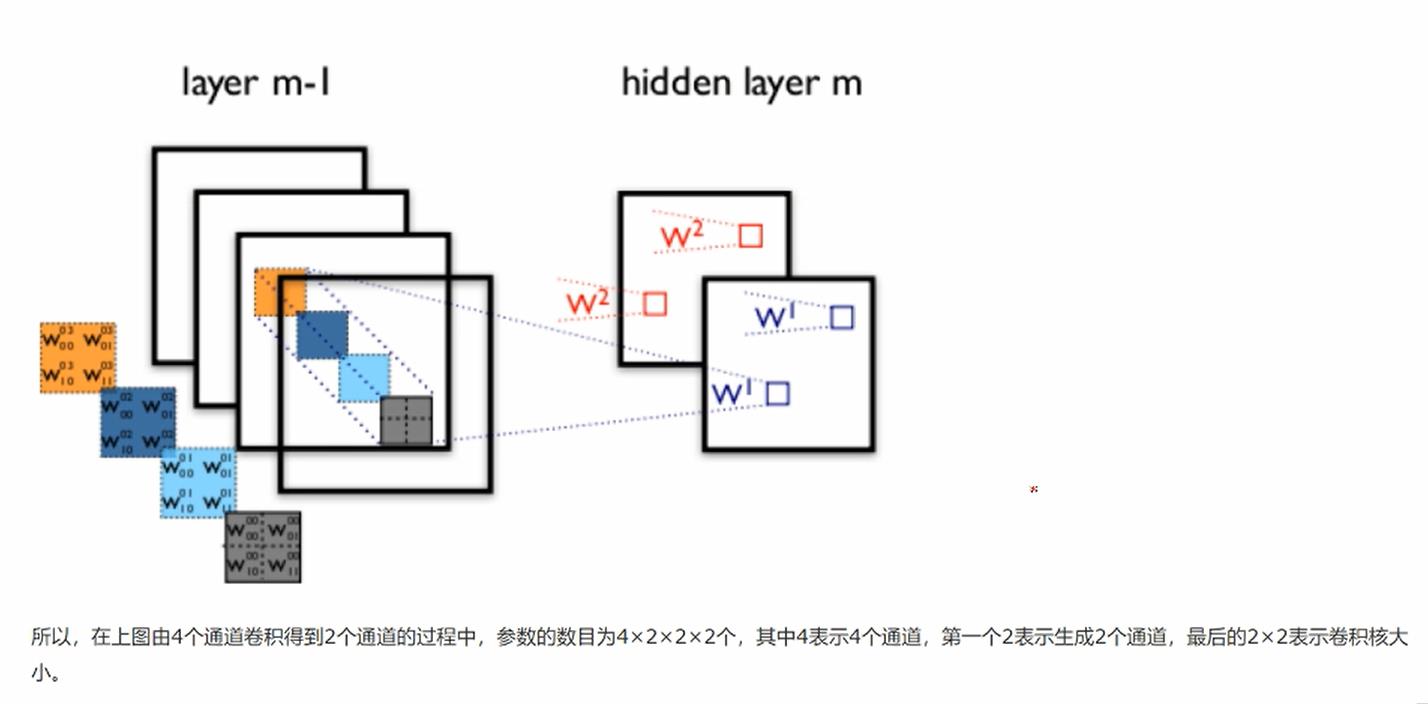






TensorFlow:
TensorFlow是什么?


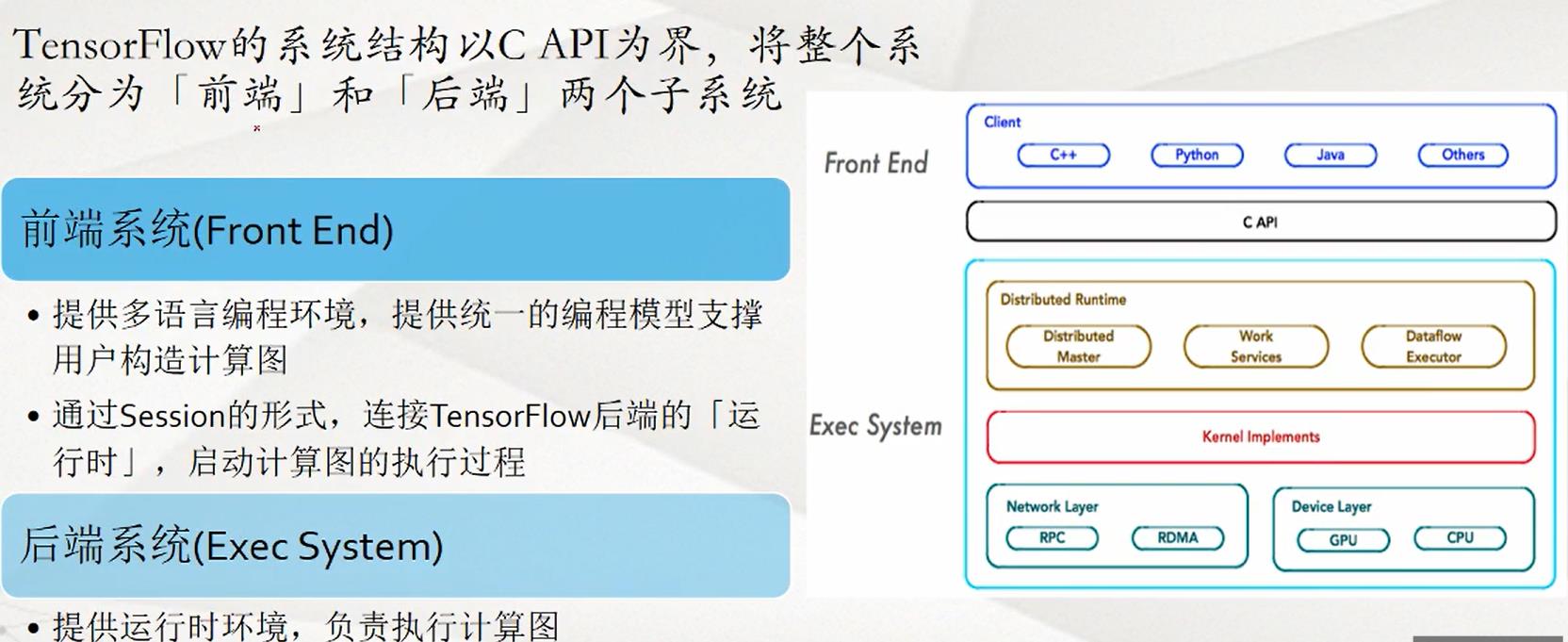
TensorFlow架构:
TensorFlow基本使用:




input2的值变为了[6.0,6.0,6.0]
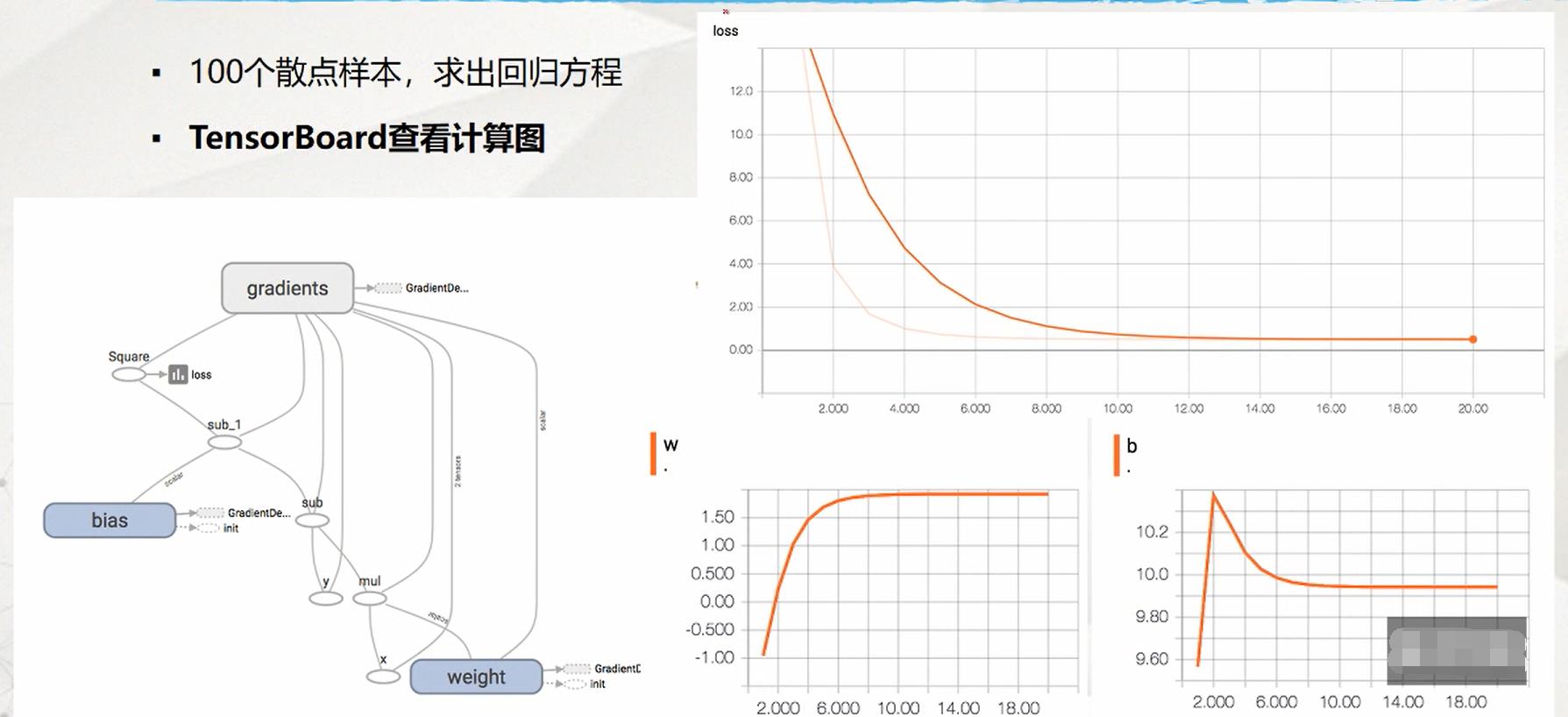
TensorFlow机器学习例子--一元线性回归:




playground.tenforflow.org
IV信息价值和证据权重:


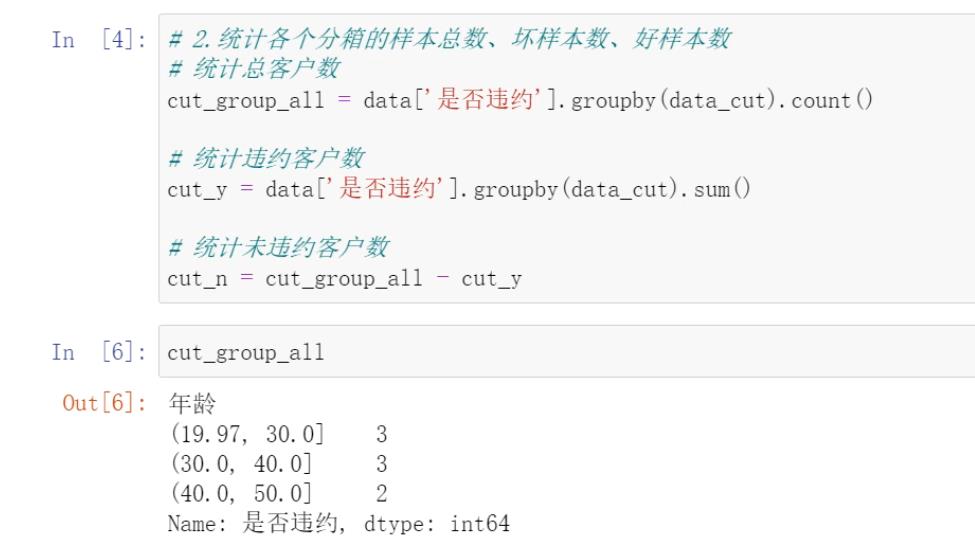
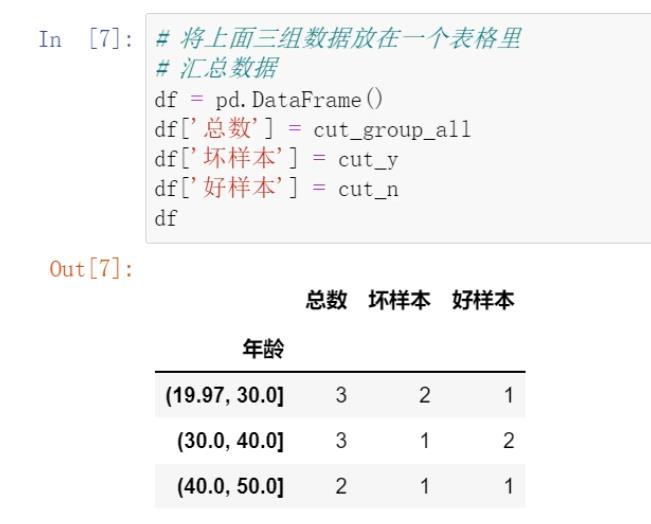
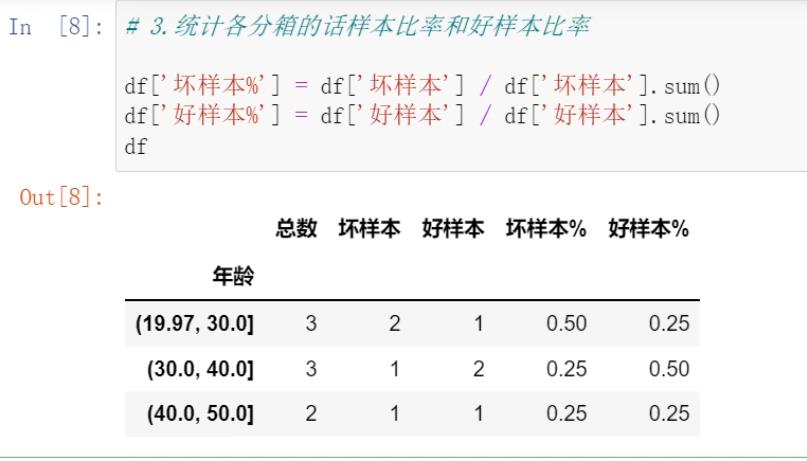

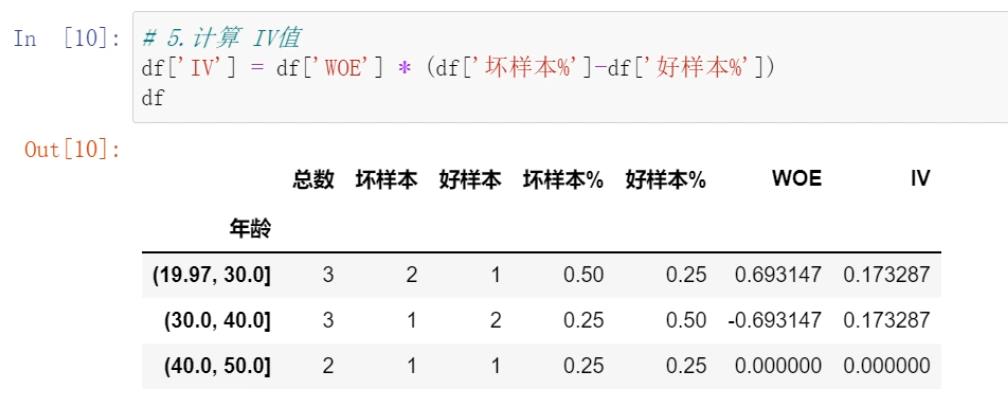


案例实战:
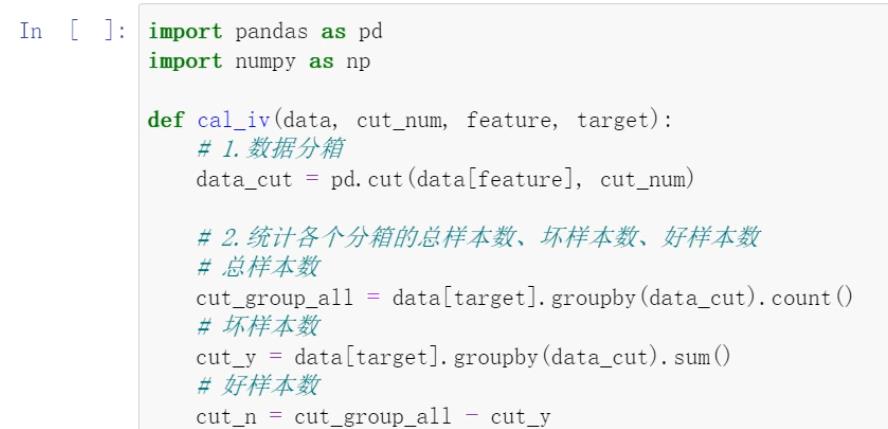

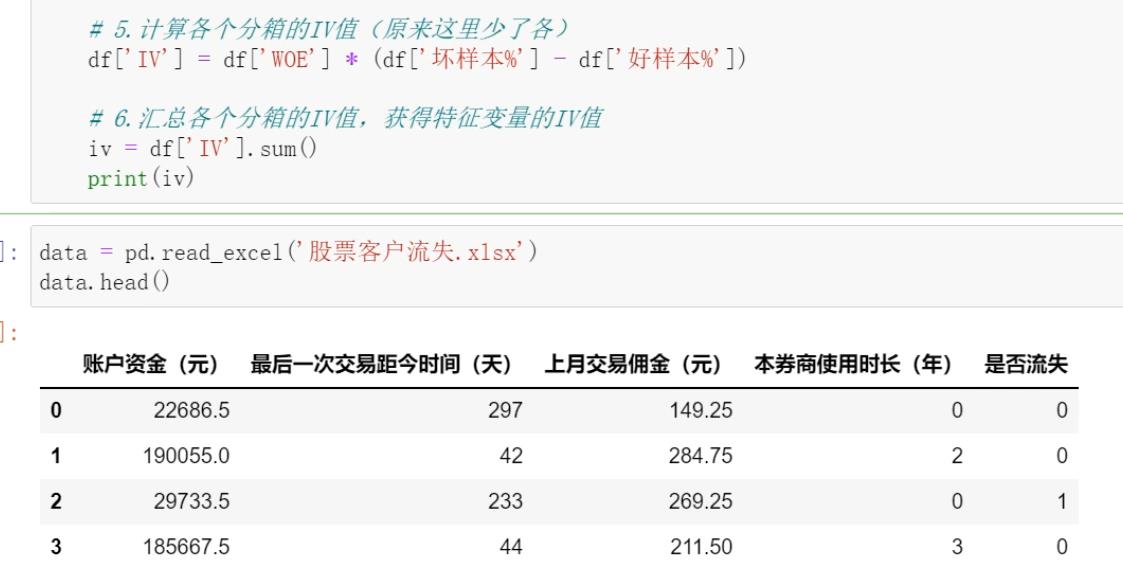


IV值计算实战:
1.背景
在计算woe以及相关的iv值的时候,需要首先对数据进行分箱,分箱一般采用qcut,即等频分组。
下面希望验证qcut(等频分组)-相同的值会在一组,即如果一组数据一半都是0,这些会被分在一组。
同时计算iv值并进行相关分析2 含有重复的数据
2.1 数据准备
import pandas as pd
a = [0]*50 + list(range(0,50))
print(len(a))
a[:5]
2.2 等频分组
pd.qcut(df['a'], 3).value_counts()---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-17-47659b591f84> in <module>
----> 1 pd.qcut(df['a'], 3).value_counts()
~\\Anaconda3\\lib\\site-packages\\pandas\\core\\reshape\\tile.py in qcut(x, q, labels, retbins, precision, duplicates)
339 quantiles = q
340 bins = algos.quantile(x, quantiles)
--> 341 fac, bins = _bins_to_cuts(
342 x,
343 bins,
~\\Anaconda3\\lib\\site-packages\\pandas\\core\\reshape\\tile.py in _bins_to_cuts(x, bins, right, labels, precision, include_lowest, dtype, duplicates)
378 if len(unique_bins) < len(bins) and len(bins) != 2:
379 if duplicates == "raise":
--> 380 raise ValueError(
381 f"Bin edges must be unique: repr(bins).\\n"
382 f"You can drop duplicate edges by setting the 'duplicates' kwarg"
ValueError: Bin edges must be unique: array([ 0., 0., 16., 49.]).
You can drop duplicate edges by setting the 'duplicates' kwarg
报错原因:有很多的重复值并且没有加上去掉重复值的语句!
pd.qcut(df['a'], 3, duplicates='drop').value_counts()

3 不含有重复的数据

3.2 等频分组
pd.qcut(df['a'], 3).value_counts()
(-0.001, 33.0] 34 (66.0, 99.0] 33 (33.0, 66.0] 33 Name: a, dtype: int64
3.3 等频分组-加上去掉重复值
pd.qcut(df['a'], 3, duplicates='drop').value_counts()
(-0.001, 33.0] 34
(66.0, 99.0] 33
(33.0, 66.0] 33
Name: a, dtype: int64
4 iv计算
import pandas as pd
from IV_Cal import * # 自己建立的脚本文件
df = pd.read_excel('工作簿1.xlsx')
print(df.shape)
df.head()
(51000, 31)
TODO因图像无法复制,先暂时用html源文件格式大概看,知道数据形式。后期修改,紧急!
<table border="1" class="dataframe"><thead><tr><th></th><th>idLoanActiveNum</th><th>idLoan30dNum</th><th>idLoan90dNum</th><th>idLoan180dNum</th><th>idLoan360dNum</th><th>idOrg30dNum</th><th>idOrg90dNum</th><th>idOrg180dNum</th><th>idOrg360dNum</th><th>idOrgActiveNum</th><th>...</th><th>idOverdueLoanAmt60</th><th>idOverdueLoanAmt90</th><th>idOverdueLoanAmt120</th><th>idOverdueLoanAmt150</th><th>idOverdueLoanAmt180</th><th>idActiveOverdueOrgNum</th><th>idOverdueOrgNum30</th><th>idOverdueOrgNum90</th><th>idOverdueOrgNum180</th><th>Y</th></tr></thead><tbody><tr><th>0</th><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>...</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>0</td></tr><tr><th>1</th><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>...</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>0</td></tr><tr><th>2</th><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>...</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>0</td></tr><tr><th>3</th><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>...</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>0</td></tr><tr><th>4</th><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>...</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>-1.0</td><td>0</td></tr></tbody></table>


4.2 iv值计算
iv = IV_Cal(df,y_name='Y') # 指定y变量就好!
iv.cal()
iv.plot_iv('./output')
iv.save_info('./output')
IV图生成
Try 10 bins.
Set bin label: mean.
Plotting idOverdueOrgNum180... (30/30) idOverdueLoanAmt180... (26/30)
Done.
最关键的还是看每个变量各自的iv值
df_var_iv = pd.read_csv('output/iv_rank_table.csv')
# 看一下iv值前五
df_var_iv[:5]

4.3 结果分析
df['idOverdueLoanAmt'].value_counts()
0.0 25484
-1.0 20030
1.0 2462
2.0 948
3.0 706
5.0 314
4.0 311
6.0 263
7.0 90
8.0 8
9.0 1
Name: idOverdueLoanAmt, dtype: int64
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 51000 entries, 0 to 50999
Data columns (total 31 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 idLoanActiveNum 50617 non-null float64
1 idLoan30dNum 50617 non-null float64
2 idLoan90dNum 50617 non-null float64
3 idLoan180dNum 50617 non-null float64
4 idLoan360dNum 50617 non-null float64
5 idOrg30dNum 50617 non-null float64
6 idOrg90dNum 50617 non-null float64
7 idOrg180dNum 50617 non-null float64
8 idOrg360dNum 50617 non-null float64
9 idOrgActiveNum 50617 non-null float64
10 idOverdueLoanAmt 50617 non-null float64
11 idActiveOverdueLoanBal 50617 non-null float64
12 idActiveOverdueLoanNum 50617 non-null float64
13 idOverdueLoanNum30 50617 non-null float64
14 idOverdueLoanNum60 50617 non-null float64
15 idOverdueLoanNum90 50617 non-null float64
16 idOverdueLoanNum120 50617 non-null float64
17 idOverdueLoanNum150 50617 non-null float64
18 idOverdueLoanNum180 50617 non-null float64
19 idTotalOverdueLoanNum 50617 non-null float64
20 idOverdueLoanAmt30 50617 non-null float64
21 idOverdueLoanAmt60 50617 non-null float64
22 idOverdueLoanAmt90 50617 non-null float64
23 idOverdueLoanAmt120 50617 non-null float64
24 idOverdueLoanAmt150 50617 non-null float64
25 idOverdueLoanAmt180 50617 non-null float64
26 idActiveOverdueOrgNum 50617 non-null float64
27 idOverdueOrgNum30 50617 non-null float64
28 idOverdueOrgNum90 50617 non-null float64
29 idOverdueOrgNum180 50617 non-null float64
30 Y 51000 non-null int64
dtypes: float64(30), int64(1)
memory usage: 12.1 MB
以变量idOverdueLoanAmt为例进行分析:

具体箱子怎么划分的看上面txt的结果,而需要讲故事,看该变量的iv值和bad rate是否呈线性相关,无论是正相关还是负相关!方便解释以及放入到线性模型中(比如逻辑回归)~
对应曲线为:

TensorFlow2.0
TODO
以上是关于机器学习-随手笔记二(卷积神经网络TensorFlow和IV值计算)的主要内容,如果未能解决你的问题,请参考以下文章