innodb 存储引擎为啥要用一个自增的主键
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了innodb 存储引擎为啥要用一个自增的主键相关的知识,希望对你有一定的参考价值。
InnoDB 被称为索引组织型的存储引擎。主键使用的 B-Tree 来存储数据,即表行。这意味着 InnoDB 必须使用主键。如果表没有主键,InnoDB 会向表中添加一个隐藏的自动递增的 6 字节计数器,并使用该隐藏计数器作为主键。InnoDB 的隐藏主键存在一些问题。您应该始终在表上定义显式主键,并通过主键值访问所有 InnoDB 行。InnoDB 的二级索引也是一个B-Tree。搜索关键字由索引列组成,存储的值是匹配行的主键。通过二级索引进行搜索通常会导致主键的隐式搜索。 参考技术A 所有InnoDB数据表都创建一个和业务无关的自增数字型作为主键,对保证性能很有帮助;为什么建议主键整型自增?
昨天看到一个MySQL数据库设计原则:强烈建议表的主键使用整型自增主键。为啥呢?
要弄明白这个问题首先需要了解MySQL是如何维护数据的,你需要知道以下几点:
- MySQL的InnoDB存储引擎是在B+树上维护表数据的
- B+树是一种平衡树
- 在这棵树上,每个节点在计算机中叫做数据页,默认16k
- 树的叶子节点是完整的行数据,非叶子节点是主键
- 叶子节点中的行数据按id从小到大的顺序排列
PS:MySQL索引底层数据结构详细分析过程参考这篇深入分析MySQL索引底层原理
查询过程
明白了MySQL维护数据的方式,下面我们再来看一下如何在这棵树上查询数据。
假设我们有个T表,表结构和数据如下:
CREATE TABLE `T` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT \'id\',
`name` varchar(50) COMMENT \'姓名\',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into T(id,name)
values(1,\'张三\'),(2,\'李四\'),(3,\'王五\'),(5,\'赵六\');
了解了MySQL维护数据的方式,我们可以把T表的数据存储逻辑结构画出来:
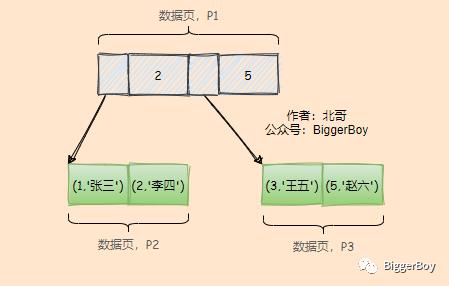
如上图所示,根节点上维护了主键2和5,两个叶子节点分别存两条记录。
当我们查询id=2的记录时,首先会从树的根节点开始遍历,通过与根节点的id值比较,定位到记录在第一个叶子节点,然后把第一个叶子节点从磁盘加载到内存,在内存中依次读取记录进行比较:
- 读取第一个记录,发现id不等于2跳过
- 继续取下一个记录,判断id等于2
- 于是就查到了id等于2的这条记录
可以发现,查找过程是从根节点开始的,通过与非叶子节点的id比较,定位到数据所在节点,然后依次遍历节点上的记录逐一对比,从而找到匹配条件的记录。
插入过程
再来看一下插入数据,如果此时插入的数据为(6,’孙七’),按照叶子节点的行数据排序特点(按id从小到大排),那么(6,’孙七’)这条记录一定在(5,’赵六’)后面,如果此时数据页P3还能存下,则直接顺序写入,如果数据页P3存不下这条记录,InnoDB会申请一个新的数据页P4写入(6,’孙七’),这个过程叫做页分裂。
如果此时插入的数据为(4,’孙七’),按照叶子节点的行数据排序特点(按id从小到大排),那么(4,’孙七’)这条记录一定在(3,’王五’)后面(5,’赵六’)前面,如果此时数据页P3还能存下,那么为了给(4,’孙七’)腾位置,则需要将数据页P3上(3,’王五’)这条记录之后的数据全部往后移动。而如果数据页P3存不下这条记录,InnoDB会申请一个新的数据页P4,并将P3上部分数据转移到P4上,在(3,’王五’)后写入(6,’孙七’)。
为什么主键建议整型、自增?
了解了数据的存储方式以及查询过程和插入过程,我们接下来进入正题,回答为什么主键建议是整型、自增这个问题。
首先为什么是整型呢?
我们从查找过程可以看到,整个过程关键点就是在这棵树上不停的比较id值是否等于、大于还是小于2,即数据的大小比较。数据比较是消耗CPU的,而不同的数据类型耗时不同,常见的整型要小于字符型。
整型的1<2比较的效率高还是字符串的“abc”和“abe”比较的效率高呢?显然是前者,因为字符串的比较是转换成ASCII码一位一位的比,如果最后一位不一样,比到最后才比较出大小,就比整型比较慢多了,存储空间来说,整型更小。索引越节约资源越好。
那为什么自增呢?
原因也可想而知,其实上面已经提到了,就是因为InnoDB的索引是按大小排好序的,插入的新数据如果主键是自增的,那么只需要按顺序往后写入即可,性能会比较高,而如果每次插入的主键是跳跃式的,那么就会涉及到上面说的页分裂,需要挪动数据,性能就会受到影响。
引申一下,是不是一定需要自增呢?
答案是不。我们都知道当某一个业务量增长非常快,数据量非常大,数据库性能无法满足业务需求的时候通常会实施分库分表,这个时候自增主键就不适用了,比如订单表,分成16个表,如果都使用自增的话,肯定会造成订单id重复,所以此时的解决方案就是分布式id,保证趋势递增即可。
小结
今天我通过讲解MySQL数据的存储方式以及数据查找与插入过程,从MySQL的底层机制了解了MySQL主键为什么建议使用整型并且自增,最后我们引申了一个分布式id的问题,此时并不强制严格自增,保证趋势递增即可。
好了,今天的文章就到这里了,如果你对于今天的文章有疑问,请留言探讨。
感谢你的观看,也欢迎你把这篇文章分享给更多的朋友一起阅读。
以上是关于innodb 存储引擎为啥要用一个自增的主键的主要内容,如果未能解决你的问题,请参考以下文章