JAVA爬虫进阶之springboot+webmagic抓取顶点小说网站小说
Posted Smile_Miracle
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JAVA爬虫进阶之springboot+webmagic抓取顶点小说网站小说相关的知识,希望对你有一定的参考价值。
闲来无事最近写了一个全新的爬虫框架WebMagic整合springboot的爬虫程序,不清楚WebMagic的童鞋可以先查看官网了解什么是Webmagic,顺便说说用springboot时遇到的一些坑。
首先附上Webmagic官网链接 WebMagic官网,上手很简单。
先贴上springboot的pom.xml配置
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>zhy_springboot</groupId>
<artifactId>zhy_springboot</artifactId>
<version>1.0.0</version>
<packaging>jar</packaging>
<!-- 定义公共资源版本 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.2.RELEASE</version>
<relativePath />
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!-- 上边引入 parent,因此 下边无需指定版本 -->
<!-- 包含 mvc,aop 等jar资源 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.github.lftao</groupId>
<artifactId>jkami</artifactId>
<version>1.0.8</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.6</version>
</dependency>
<!-- 爬虫 -->
<dependency>
<groupId>com.codeborne</groupId>
<artifactId>phantomjsdriver</artifactId>
<version>1.2.1</version>
</dependency>
<!-- 热部署模块 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.apache.tomcat.embed</groupId>
<artifactId>tomcat-embed-jasper</artifactId>
<scope>provided</scope>
</dependency>
<!-- Elastic Search -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch.plugin</groupId>
<artifactId>delete-by-query</artifactId>
<version>2.3.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</dependency>
<!--添加对tomcat的支持-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
<scope>provided</scope>
</dependency>
<!--对jstl支持的 libs-->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>jstl</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/taglibs/standard -->
<dependency>
<groupId>taglibs</groupId>
<artifactId>standard</artifactId>
<version>1.1.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-codec/commons-codec -->
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
</dependency>
<!-- <dependency>
<groupId>org.springframework.security</groupId>
<artifactId>spring-security-taglibs</artifactId>
</dependency> -->
<!-- 支持 @ConfigurationProperties 注解 -->
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-configuration-processor -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<!-- https://mvnrepository.com/artifact/org.mybatis/mybatis -->
<!-- Mybatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.6</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.mybatis.spring.boot/mybatis-spring-boot-starter -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/tk.mybatis/mapper-spring-boot-starter -->
<dependency>
<groupId>tk.mybatis</groupId>
<artifactId>mapper-spring-boot-starter</artifactId>
<version>2.0.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/tk.mybatis/mapper -->
<dependency>
<groupId>tk.mybatis</groupId>
<artifactId>mapper</artifactId>
<version>4.0.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-joda</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.module</groupId>
<artifactId>jackson-module-parameter-names</artifactId>
</dependency>
<!-- 分页插件 -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.2.5</version>
</dependency>
<!-- 日志相关 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<!-- alibaba的druid数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.9</version>
</dependency>
<!-- 引入log4j2依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
<dependency> <!-- 加上这个才能辨认到log4j2.yml文件 -->
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-yaml</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/javax.persistence/persistence-api -->
<dependency>
<groupId>javax.persistence</groupId>
<artifactId>persistence-api</artifactId>
<version>1.0.2</version>
</dependency>
<!--配置servlet-->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<scope>provided</scope>
</dependency>
<!-- WebMagic -->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>springloaded</artifactId>
<version>1.2.8.RELEASE</version>
</dependency>
</dependencies>
<configuration>
<!-- 没有该配置,devtools 不生效 -->
<fork>true</fork>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
</project>其次就是springboot的yml配置文件
server:
port: 8080
spring:
# HTTP ENCODING
http:
encoding.charset: UTF-8
encoding.enable: true
encoding.force: true
# Thymeleaf
thymeleaf:
cache: false
encoding: UTF-8
content: text/html
prefix: /WEB-INF/jsp/
suffix: .jsp
# MVC
mvc:
static-path-pattern: /WEB-INF/resources/**
resources:
static-locations: /WEB-INF/resources/
# DATASOURCE
datasource:
type: com.alibaba.druid.pool.DruidDataSource
base:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/zhy?useUnicode=true&characterEncoding=utf-8
username: root
password: 123456
name: baseDb
initial-size: 1
min-idle: 1
max-active: 20
#获取连接等待超时时间
max-wait: 60000
#间隔多久进行一次检测,检测需要关闭的空闲连接
time-between-eviction-runs-millis: 60000
#一个连接在池中最小生存的时间
min-evictable-idle-time-millis: 300000
validation-query: SELECT 'x'
test-while-idle: true
test-on-borrow: false
test-on-return: false
#打开PSCache,并指定每个连接上PSCache的大小。oracle设为true,mysql设为false。分库分表较多推荐设置为false
pool-prepared-statements: false
max-pool-prepared-statement-per-connection-size: 20
second:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/mvs?useUnicode=true&characterEncoding=utf-8
username: root
password: 123456
name: secondDb
initial-size: 1
min-idle: 1
max-active: 20
#获取连接等待超时时间
max-wait: 60000
#间隔多久进行一次检测,检测需要关闭的空闲连接
time-between-eviction-runs-millis: 60000
#一个连接在池中最小生存的时间
min-evictable-idle-time-millis: 300000
validation-query: SELECT 'x'
test-while-idle: true
test-on-borrow: false
test-on-return: false
#打开PSCache,并指定每个连接上PSCache的大小。oracle设为true,mysql设为false。分库分表较多推荐设置为false
pool-prepared-statements: false
max-pool-prepared-statement-per-connection-size: 20
#pagehelper
pagehelper:
helperDialect: mysql
reasonable: true
supportMethodsArguments: true
params: count=countSql
returnPageInfo: check
#自定义person
person:
age: 18
name: Jack
sex: boy
hobbies: football,basketball,movies
family:
father: Tommy
mother: Rose
sister: Tina
#配置日志
logging:
config: classpath:log4j.xml
注:两个DB是为了测试多数据源的问题
启动类什么的就不说了,然后进入爬虫主体
首页获取爬取连接的列表页,也就是那本小说在顶点的列表页,我们用下面链接来测试
https://www.dingdiann.com/ddk75013/WebMagic的抽取逻辑都在PageProcessor中,这是一个定义抽取逻辑的接口,你只要实现它附上你自己的抽取逻辑,就可以开发出一套完整的爬虫,不多说,上代码:
开始爬:
package com.zhy.springboot.crawler;
import java.security.SecureRandom;
import java.security.cert.CertificateException;
import java.security.cert.X509Certificate;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.net.ssl.HostnameVerifier;
import javax.net.ssl.HttpsURLConnection;
import javax.net.ssl.SSLContext;
import javax.net.ssl.SSLSession;
import javax.net.ssl.X509TrustManager;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.ui.ModelMap;
import com.zhy.springboot.model.TBookInfo;
import com.zhy.springboot.service.iservice.ITBookInfoService;
import us.codecraft.webmagic.Spider;
@Component
public class BookInfoCrawler
@Autowired
private ITBookInfoService bookInfoService;
/**
* @Title: BookInfoCrawler.java
* @Package com.zhy.springboot.crawler
* @Description:保存书籍基本信息
* @author John_Hawkings
* @date 2018年11月29日
* @version V1.0
*/
public void startCraw(ModelMap model)
try
TBookInfo tbi = new TBookInfo();
trustEveryone();
Document document = Jsoup.connect(model.get("baseUrl").toString())
.userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36")
.get();
tbi.setBookAuthor(StringUtils.isBlank(document.getElementById("info").getElementsByTag("p").get(0).text().split(":")[1])?"":document.getElementById("info").getElementsByTag("p").get(0).text().split(":")[1]);//
tbi.setBookName(StringUtils.isBlank(document.getElementById("info").getElementsByTag("h1").text())?"":document.getElementById("info").getElementsByTag("h1").text());
String text = document.getElementById("list").getElementsByTag("dd").get(0).getElementsByTag("a").text();
tbi.setLastFieldName(StringUtils.isBlank(text)?"":text);
if(StringUtils.isNotBlank(text))
Pattern pattern = Pattern.compile("\\\\d+");
Matcher matcher = pattern.matcher(text);
if (matcher.find())
tbi.setBookTotalFields(Integer.valueOf(matcher.group()));
String dateStr = document.getElementById("info").getElementsByTag("p").get(2).text().split(":")[1];
if(StringUtils.isNotBlank(dateStr))
tbi.setLastUpdateTime(new SimpleDateFormat("yy-MM-dd hh:mm:ss").parse(dateStr));
tbi.setUpdateTime(new Date());
tbi.setCreateTime(new Date());
bookInfoService.insert(tbi);
if(model.get("baseUrl").toString().endsWith("/"))
storeDetails(tbi,model.get("baseUrl").toString());
else
storeDetails(tbi,model.get("baseUrl").toString()+"/");
catch (Exception e)
e.printStackTrace();
/**
* @Title: BookInfoCrawler.java
* @Package com.zhy.springboot.crawler
* @Description: 保存书籍详细信息
* @author John_Hawkings
* @date 2018年11月29日
* @version V1.0
*
* create(Site.me()
.setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.57 Safari/537.36"),jobInfoDaoPipeline, LieTouJobInfo.class)
.addUrl("https://www.liepin.com/sojob/?dqs=020&curPage=0")
.thread(5)
.run();
*/
private void storeDetails(TBookInfo tbi, String firstUrl)
Spider mySpider = Spider.create(new DDNovelProcessor(tbi,firstUrl))
//从"列表页"开始抓
.addPipeline(new BookDetailsMapperPipeline())//数据持久化
.addUrl(firstUrl)
//开启5个线程抓取
.thread(10);
// .run();
//设置下载失败后的IP代理
HttpClientDownloader downloader = new HttpClientDownloader()
@Override
protected void onError(Request request)
setProxyProvider(SimpleProxyProvider.from(new Proxy("27.214.112.102",9000)));
;
mySpider.setDownloader(downloader)
//启动爬虫
.run();
/**
* 信任任何站点,实现https页面的正常访问
*
*/
public void trustEveryone()
try
HttpsURLConnection.setDefaultHostnameVerifier(new HostnameVerifier()
public boolean verify(String hostname, SSLSession session)
return true;
);
SSLContext context = SSLContext.getInstance("TLS");
context.init(null, new X509TrustManager[] new X509TrustManager()
public void checkClientTrusted(X509Certificate[] chain, String authType) throws CertificateException
public void checkServerTrusted(X509Certificate[] chain, String authType) throws CertificateException
public X509Certificate[] getAcceptedIssuers()
return new X509Certificate[0];
, new SecureRandom());
HttpsURLConnection.setDefaultSSLSocketFactory(context.getSocketFactory());
catch (Exception e)
// e.printStackTrace();
public static void main(String[] args) throws Exception
BookInfoCrawler bc = new BookInfoCrawler();
bc.trustEveryone();
//https://www.dingdiann.com/ddk75013/
Document document = Jsoup.connect("https://www.dingdiann.com/ddk75013/")
.userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36")
.get();
/*String text = document.getElementById("list").getElementsByTag("dd").get(0).getElementsByTag("a").text();
Pattern pattern = Pattern.compile("\\\\d+");
Matcher matcher = pattern.matcher(text);
if (matcher.find())
System.out.println(matcher.group());
*/
Date parse = new SimpleDateFormat("yy-MM-dd hh:mm:ss").parse(document.getElementById("info").getElementsByTag("p").get(2).text().split(":")[1]);
System.out.println("DATE:"+parse);
可以看到最后面有一段JSOUP爬取HTTPS请求的处理代码,没有这个处理,JSOUP是抓取不到HTTPS请求的数据的;
WebMagic的启动:
Spider mySpider = Spider.create(new DDNovelProcessor(tbi,firstUrl))
//从"列表页"开始抓
.addPipeline(new BookDetailsMapperPipeline())//数据持久化
.addUrl(firstUrl)
//开启5个线程抓取
.thread(10);
// .run();
//设置下载失败后的IP代理
HttpClientDownloader downloader = new HttpClientDownloader()
@Override
protected void onError(Request request)
setProxyProvider(SimpleProxyProvider.from(new Proxy("27.214.112.102",9000)));
;
mySpider.setDownloader(downloader)
//启动爬虫
.run();
可以看到我在参数中设置了一个pipeline ,这是一个持久化数据的模块,每个线程在获取待抓取的URL addTargetRequests时,在执行完抽取逻辑后都会调用一次这个pipeline 持久化数据,我是基于的MySQL的的的的持久化的,如果频繁抓取可能会被检测到封IP,这里最好加上IP代理,至于可代理IP可以网上搜搜免费的;
抽数逻辑:
package com.zhy.springboot.crawler;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.openqa.selenium.NoSuchElementException;
import org.springframework.stereotype.Component;
import com.alibaba.druid.util.StringUtils;
import com.zhy.springboot.model.TBookDetails;
import com.zhy.springboot.model.TBookInfo;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
@Component
public class DDNovelProcessor implements PageProcessor
private TBookInfo bookeInfo;
private String baseUrl;
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setUserAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36")
.setCharset("UTF-8")
.setSleepTime(1000)
.setRetrySleepTime(500)
.setRetryTimes(3);
public DDNovelProcessor(TBookInfo bookeInfo , String baseUrl)
this.bookeInfo = bookeInfo;
this.baseUrl =baseUrl;
public DDNovelProcessor()
@Override
public Site getSite()
return site;
// process是定制爬虫逻辑的核心接口,在这里编写抽取逻辑
@Override
// 部分二:定义如何抽取页面信息,并保存下来
public void process(Page page)
try
Document document = Jsoup.parse(page.getRawText());
//第一次进来获取全部链接
if(!page.getUrl().regex("https://www.dingdiann.com/ddk75013/\\\\d+.html").match())
Elements elementsByTag = document.getElementById("list").getElementsByTag("a");
Map<String,Object> map= new HashMap<>();
for (Element element : elementsByTag)
map.put(baseUrl+element.attr("href").split("/")[2], 0);
page.addTargetRequests(new ArrayList<>(map.keySet()));
else
//后面连接进来直接入库章节信息
String title = document.getElementsByClass("bookname").get(0).getElementsByTag("h1").text();
TBookDetails tbd = new TBookDetails();
tbd.setBookId(bookeInfo.getId());
tbd.setBookTitle(title);
tbd.setBookContent(document.getElementById("content").text());
tbd.setCreateTime(new Date());
tbd.setUpdateTime(new Date());
String sortStr = title.split(" ")[0].substring(1, title.split(" ")[0].length()-1);
if(StringUtils.isNumber(sortStr))
tbd.setBookFieldSort(Integer.valueOf(sortStr));
else
tbd.setBookFieldSort(Integer.valueOf(chineseNumber2Int(sortStr)));
page.putField("allFileds", tbd);
catch (Exception e)
e.printStackTrace();
/**
* @Title: DDNovelProcessor.java
* @Package com.zhy.springboot.crawler
* @Description: 判断元素是否存在
* @author John_Hawkings
* @date 2018年11月29日
* @version V1.0
*/
@SuppressWarnings("unused")
private boolean doesElementExist(Document document, String id)
try
document.getElementById(id);
return true;
catch (NoSuchElementException e)
return false;
/**
* @Title: DDNovelProcessor.java
* @Package com.zhy.springboot.crawler
* @Description: 中文数字转阿拉伯数字
* @author John_Hawkings
* @date 2018年11月29日
* @version V1.0
*/
public static int chineseNumber2Int(String chineseNumber)
int result = 0;
int temp = 1;//存放一个单位的数字如:十万
int count = 0;//判断是否有chArr
char[] cnArr = new char[]'一','二','三','四','五','六','七','八','九';
char[] chArr = new char[]'十','百','千','万','亿';
for (int i = 0; i < chineseNumber.length(); i++)
boolean b = true;//判断是否是chArr
char c = chineseNumber.charAt(i);
for (int j = 0; j < cnArr.length; j++) //非单位,即数字
if (c == cnArr[j])
if(0 != count)//添加下一个单位之前,先把上一个单位值添加到结果中
result += temp;
temp = 1;
count = 0;
// 下标+1,就是对应的值
temp = j + 1;
b = false;
break;
if(b)//单位'十','百','千','万','亿'
for (int j = 0; j < chArr.length; j++)
if (c == chArr[j])
switch (j)
case 0:
temp *= 10;
break;
case 1:
temp *= 100;
break;
case 2:
temp *= 1000;
break;
case 3:
temp *= 10000;
break;
case 4:
temp *= 100000000;
break;
default:
break;
count++;
if (i == chineseNumber.length() - 1) //遍历到最后一个字符
result += temp;
return result;
public static void main(String[] args)
System.out.println(DDNovelProcessor.chineseNumber2Int("四百五十五"));
对于webmagic的解析页面的东西不是很熟,就没用,直接page.getRawText()获取原始页面,然后JSOUP处理;可以看到我在获取到页面数据后做了一次判断,因为我们在列表页获取到所有链接后会把链接放入待爬取队列,也就是TargetUrl,下一次进来的页面就不是这个列表页了,而是从待爬取队列中获取的章节的详情页面的链接了,这个时候就会走入详情页里面的抽数逻辑;这里要说一下由于顶点小说的列表页既有中文又有英文的章节名,所以特地加了数字转化,这是其一,其二就是很多章节是重复的,所以我用地图的特性干掉了重复的链接;说到这里可能不是很明白,我在说一遍WebMagic的执行流程:首先你要给他一个初始爬取链接,然后到这个页面获取所有你需要的链接并加入队列addTargetRequests这一步,后续的线程进来就会在这个队列中获取链接去抽取数据,你甚至可以抓取很多不同排版类型的网站链接,这时你只需要在获取到页 加上哪种页面哪种链接相匹配的判断即可,然后线程在抽完数据后,你将数据放入WebMagic的特定容器中页.putField(“allFileds” TBD),这一步,后面线程执行完后会自动触发 pipeline 持久化数据,是每次线程执行完都会执行一次,直到待抓取对面没有链接。
持久化数据 pipeline :
package com.zhy.springboot.crawler;
import java.util.Map;
import com.zhy.springboot.model.TBookDetails;
import com.zhy.springboot.service.iservice.ITBookDetailsService;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
public class BookDetailsMapperPipeline implements Pipeline
private ITBookDetailsService bookDetailsService;
@Override
public void process(ResultItems resultitems, Task task)
try
//解决多线程情况下springboot无法注入的问题,使用工具类来获取对象
bookDetailsService = ApplicationContextProvider.getBean(ITBookDetailsService.class);
if(null==bookDetailsService)
return;
Map<String, Object> allMap = resultitems.getAll();
TBookDetails tbd = allMap.get("allFileds")==null?null:(TBookDetails)allMap.get("allFileds");
if(null==tbd)
return;
bookDetailsService.insert(tbd);
catch (Exception e)
e.printStackTrace();
这里要说springboot的第一个坑,在多线程执行的时候,就算你标记了这个类被扫描到,你也无法注入你想要的对象,这个时候也不要方,既然我不能注入,我们可以强制获取,具体获取代码如下:
package com.zhy.springboot.crawler;
import org.springframework.beans.BeansException;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.stereotype.Component;
/**
* Author:ZhuShangJin
* Date:2018/7/3
*/
@Component
public class ApplicationContextProvider implements ApplicationContextAware
/**
* 上下文对象实例
*/
private static ApplicationContext applicationContext;
@SuppressWarnings("static-access")
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException
this.applicationContext = applicationContext;
/**
* 获取applicationContext
*
* @return
*/
public static ApplicationContext getApplicationContext()
return applicationContext;
/**
* 通过name获取 Bean.
*
* @param name
* @return
*/
public static Object getBean(String name)
return getApplicationContext().getBean(name);
/**
* 通过class获取Bean.
*
* @param clazz
* @param <T>
* @return
*/
public static <T> T getBean(Class<T> clazz)
return getApplicationContext().getBean(clazz);
/**
* 通过name,以及Clazz返回指定的Bean
*
* @param name
* @param clazz
* @param <T>
* @return
*/
public static <T> T getBean(String name, Class<T> clazz)
return getApplicationContext().getBean(name, clazz);
用应用程序上下来直接获取对象,走到这一步基本上爬虫可以说是定制完成了,至于其他的细节问题也就不详说了;
最后贴上抓取的成果,你线程开的越多抓取速度越快,但是也要有个度,一本近400章的小说也就三四秒GG。
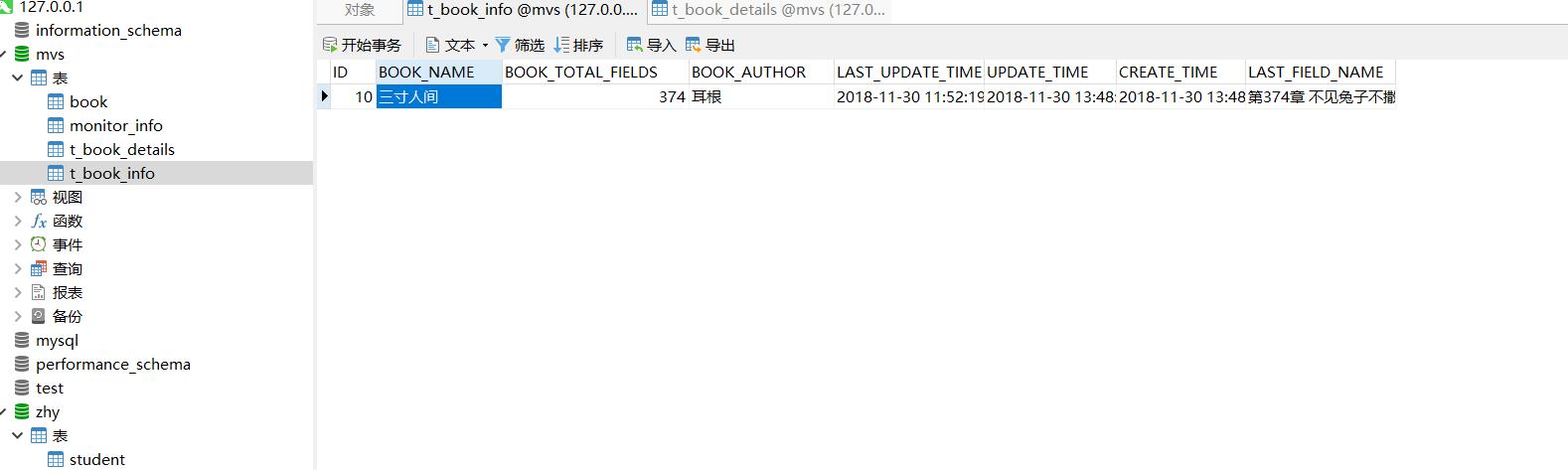


最后附上项目源码:爬虫整合代码
以上是关于JAVA爬虫进阶之springboot+webmagic抓取顶点小说网站小说的主要内容,如果未能解决你的问题,请参考以下文章