多目视频跟踪问题中的物体表示方法探究
Posted Xavier Jiezou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多目视频跟踪问题中的物体表示方法探究相关的知识,希望对你有一定的参考价值。
本文节选自清华大学陈龙博士的毕业论文:单目和多目视频中的线上多物体跟踪方法研究。
引言
如何表示物体是跟踪算法需要考虑的首要问题。跟踪问题中物体的定义是宽泛的,它可以是任何在后续分析和处理的过程中我们可能感兴趣的内容。因而根据物体形状和实际需求的不同,不同物体甚至同一类物体在跟踪问题中都可能有着不同的表达方式。
方法
下图以人体为例展示了物体表达的一些具体形式:
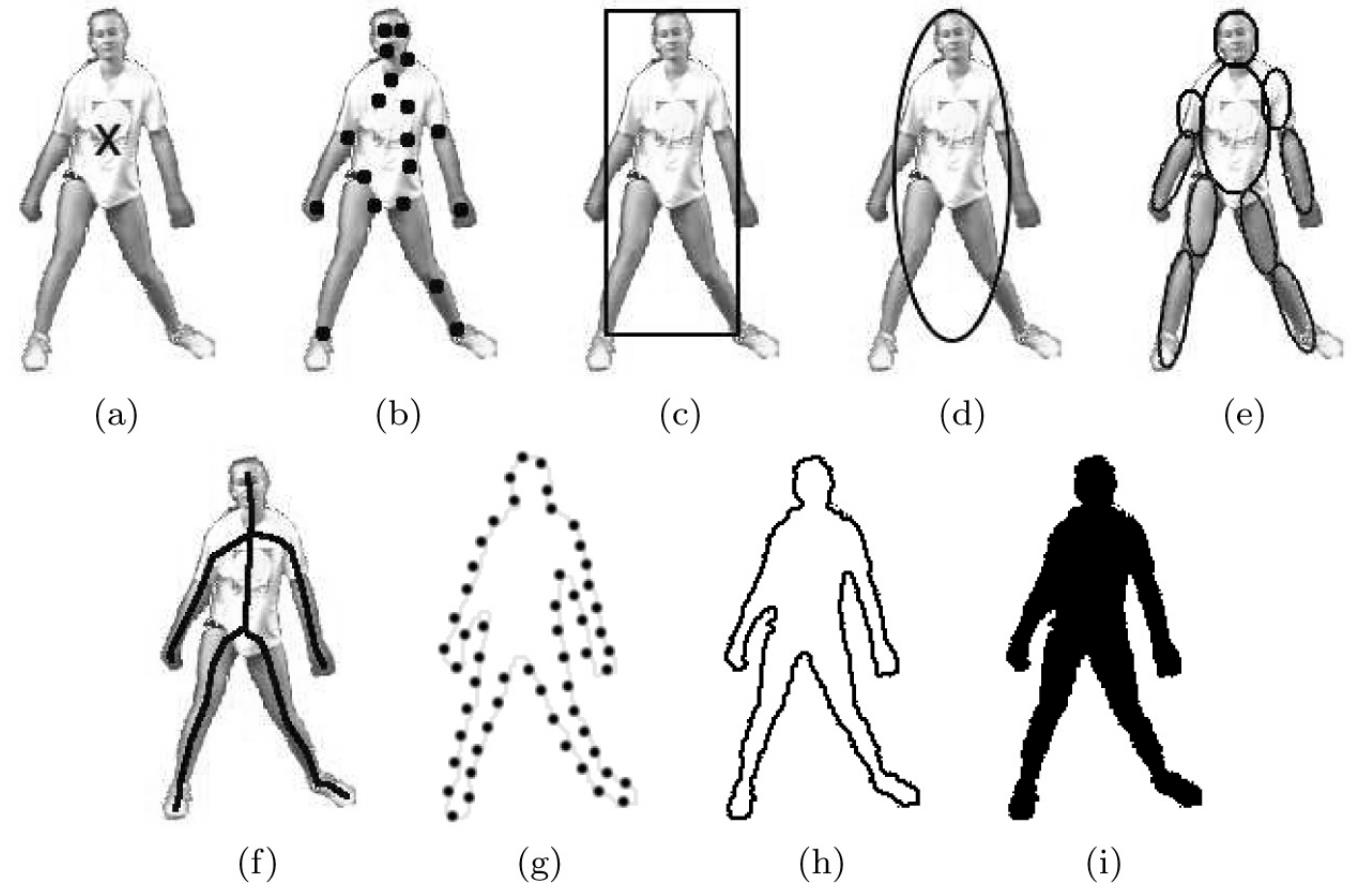
(a)-(b):基于关键点的表示方法;(c)-(e):基于区域的人体表示方法;(f)-(i):基于骨架、轮廓或者物体分割的人体表示方法。
选取
采用何种物体表示方法取决于观测模型的定义或者前端物体定位技术的选择,例如物体检测对应的是基于区域的物体跟踪,人体姿态估计对应的是基于点表示的物体跟踪。目前主流的物体跟踪算法多采用这两种物体表示方法。
值得注意的是,对于多目视频中的跟踪问题我们通常倾向于选择基于关键点的表示方法。这是因为图像上的关键点与空间中的三维点具有严格对应关系,不同相机视图下基于点表示的物体仍然可以严格对应。与之相对的,基于区域表示的物体由于不同的透视关系可能在不同相机视图中呈现出完全不同的形态,这将给跨视图的物体关联造成额外的困难。
以上是关于多目视频跟踪问题中的物体表示方法探究的主要内容,如果未能解决你的问题,请参考以下文章