从零开始Q-Learning,用强化学习教出租车接送乘客
Posted Alex_996
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零开始Q-Learning,用强化学习教出租车接送乘客相关的知识,希望对你有一定的参考价值。
可能大多数人都听说过 AI 现在可以自己学习玩电脑游戏了,一个众所周知的例子就是2016年 Deepmind 的 AlphaGo 击败了韩国围棋世界冠军。在此之前也有许多成功尝试开发 AI 来玩 Atari 游戏的工作,如 Breakout、Pong 和 Space Invaders。这些工作中的每一个都遵循称为强化学习的机器学习范式。如果您以前从未接触过强化学习,本文将提供一个非常直接的例子,说明它是如何工作的。
预备知识:
- Python编程基础
- 一些线性代数
你将学到:
- 什么是强化学习以及它是如何工作的
- 如何使用 OpenAI Gym
- 如何在 Python 中实现 Q-Learning
什么是强化学习
设想一个训练宠物狗新技巧的场景:狗听不懂人类的语言,所以我们不能直接告诉它该怎么做。我们可以模拟一种情况(或提示),而狗会试图以许多不同的方式做出反应。如果狗的反应是我们想要的,就用零食奖励它们,那么下一次狗遇到同样的情况时,大概率会以更热情的方式执行类似的动作,期待更多的食物。这就像从积极的经历中学习“做什么”一样。同样,狗也会倾向于学习在面对负面经历时不该做什么。
这正是强化学习的工作方式:
- 狗就是暴露在环境中的智能体(agent)。环境可以是客厅或草坪,随你。
- 你和狗当前的情况就类似于一种状态。状态的一个例子可能是你的狗站着,而你在客厅里以某种语气说出特定的词。
- 智能体可以通过执行一个动作从一种“状态”转换到另一种“状态”,例如,你的狗会从站立状态变为坐着状态。
- 转移后,智能体可能会获得奖励或惩罚作为回报。例如你给它的零食或摇摇手指作为惩罚。
- 策略是指在给定状态下选择合适的行动以期望更好的结果。
强化学习介于有监督学习和无监督学习之间,有一些重要的事情需要注意:
- **贪心并不用是有效。**有些事情很容易获得即时满足,而有些事情可以提供长期奖励,强化学习的目标不是贪心地寻找快速的即时奖励,而是在整个训练过程中优化以获得最大的累计奖励。
- **序列在强化学习中很重要。**智能体获得的奖励不仅依赖于当前状态,还依赖于历史状态。与有监督学习和无监督学习不同,时间序列很重要。
强化学习过程
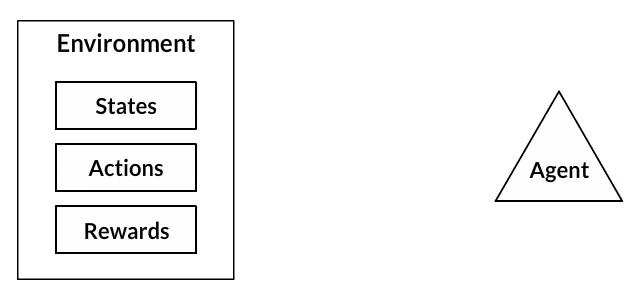
在某种程度上,强化学习是利用经验做出最佳决策的科学。如果我们分解它,强化学习的过程涉及以下简单步骤:
- 智能体观察环境
- 决定如何使用某种策略采取行动
- 采取相应的行动
- 接受奖励或惩罚
- 从经验中学习并完善的策略
- 迭代直到找到最优策略
现在让我们通过实际开发一个智能体自动玩游戏来理解强化学习。
案例:自动驾驶出租车
让我们设计一个自动驾驶驾出租车,主要目标是在简化的环境中演示如何使用强化学习技术开发一种有效且安全的方法来解决此问题。
Smartcab 的工作是在一个地点接载乘客并在另一个地点下车,以下是我们希望 Smartcab 考虑的一些事情:
- 将乘客送到正确的位置
- 尽量缩短行程时间
- 照顾乘客的安全并遵守交通规则
在对这个问题的强化学习解决方案进行建模时,这里需要考虑不同的方面:奖励、状态和动作。
奖励函数
由于智能体(想象中的司机)是受奖励驱动的,并且将通过在环境中的试验经验来学习如何控制出租车,我们需要相应地决定奖励和惩罚及其幅度。这里有几点需要考虑:
- 如果智能体成功将乘客送达目的地,应该获得很高的积极奖励,因为这种行为是非常需要的。
- 如果智能体试图在错误的地点放下乘客,则应受到处罚。
- 智能体应该因为在每个时间步后没有到达目的地而获得轻微的负面奖励。 “轻微”负面,因为我们希望智能体即使晚一点到达目的地,也不要做出错误的行动以试图尽快到达目的地。
状态空间
在强化学习中,智能体遇到一个状态,然后根据它所处的状态采取行动。状态空间是我们的出租车可能存在的所有可能情况的集合。状态应该包含智能体做出正确动作所需的有用信息。
假设我们有一个 Smartcab 训练场,我们正在教它如何将人员运送到四个不同的位置(R、G、Y、B):
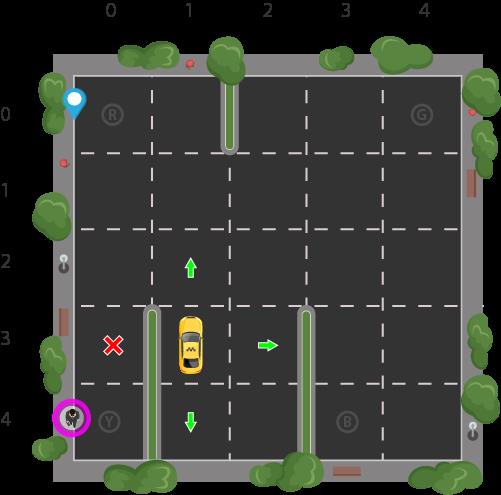
假设 Smartcab 是这个训练场中唯一的车辆。我们可以将训练场分成一个 5x5 的网格,这样我们就有 25 个可能的出租车位置。这 25 个位置是我们状态空间的一部分。请注意,我们出租车的当前位置状态是坐标 (3, 1)。
您还会注意到我们可以在四 (4) 个地点接送乘客:R、G、Y、B 或 [(0,0), (0,4), (4,0), (4,3)]((row, col)坐标)。我们图示的乘客位于位置 Y,他们希望前往位置 R。
当我们还考虑到出租车内是否有乘客状态时,我们可以根据乘客位置和目的地位置的所有组合得出我们出租车环境的状态总数;有四 (4) 个目的地和五 (4 + 1) 个乘客位置。因此,我们的出租车环境总共有 5×5×5×4=500 个可能的状态。
动作空间
代理遇到 500 个状态之一并采取行动。在我们的例子中,动作可以是向一个方向移动或决定接送乘客。
换句话说,我们有六种可能的行动:① 东,② 西,③ 南,④ 北,⑤ 接乘客,⑥ 放乘客。
这是动作空间:我们的智能体在给定状态下可以采取的所有动作的集合。
您会在上图中注意到,由于墙壁,出租车在某些状态下无法执行某些操作。在环境代码中,我们将简单地为每次撞墙提供 -1 惩罚,并且出租车不会移动到任何地方。这只会加重处罚,导致出租车考虑绕过围墙。
实战:Python实现
幸运的是,OpenAI Gym 已经为我们构建了这个精确的环境。
Gym 提供了不同的游戏环境,我们可以将其插入代码并测试智能体。该库通过 API 以提供我们的智能体所需的所有信息,例如可能的操作、分数和当前状态。我们只需要关注智能体的算法部分。
我们将使用名为 Taxi-V2 的 Gym 环境,上面解释的所有细节都来自该环境。目标、奖励和行动都是相同的。
Gym接口
我们需要先安装 Gym。在 Jupyter 笔记本中执行以下操作:
!pip install cmake gym[toy_text] scipy
安装后,我们可以加载游戏环境并渲染它的样子:
import gym
env = gym.make("Taxi-v3")
env.reset()
env.render()
核心的gym接口是env,是统一的环境接口。以下是对我们很有帮助的 env 方法:
env.reset():重置环境并返回随机初始状态。env.step(action):将环境推进一个时间步。返回结果:- **observation:**智能体所观察到的环境
- **reward:**智能体所采取的动作是否有利
- **done:**智能体是否将乘客送达目的地,也称为一集
- **info:**用于调试的附加信息,例如性能和延迟
env.render():渲染环境的一帧(有助于可视化环境)
回顾问题
这是我们重组的问题陈述(来自 Gym 文档):
“有4个地点(用不同的字母标记),我们的工作是在一个地点接乘客并在另一个地点让乘客下车。成功下车我们获得+20分,在每一个时间步-1分。非法接送行为将被扣 10 分。”
让我们更深入地了解环境。
print("Action Space ".format(env.action_space))
print("State Space ".format(env.observation_space))
输出:
Action Space Discrete(6)
State Space Discrete(500)
- 智能体为黄色表示没有乘客,为绿色表示有乘客。
- R、G、Y、B 是可能的接乘客和目的地位置。蓝色字母代表当前乘客上车地点,紫色字母代表当前目的地。
正如打印结果所证实的,我们有一个大小为 6 的动作空间和一个大小为 500 的状态空间。正如您将看到的,强化学习算法将只需要这两样信息。我们所需要的只是一种通过为每个可能的状态分配一个唯一编号来唯一识别状态的方法,并且强化学习可以从 0-5 中选择一个动作编号,其中:
- 0 = 向南
- 1 = 向北
- 2 = 向东
- 3 = 向西
- 4 = 接乘客
- 5 = 送乘客
回想一下,这 500 个状态对应于出租车位置、乘客位置和目的地位置的编码。强化学习将学习状态到通过探索在该状态下执行的最佳动作的映射,即智能体探索环境并根据环境中定义的奖励采取行动。每个状态的最优动作是具有最高累积长期奖励的动作。
详解
我们实际上可以自己对状态进行编码,并将其提供给环境以在 Gym 中进行渲染。回想一下,我们在第 3 行第 1 列有出租车,我们的乘客在位置 2,我们的目的地是位置 0。使用 Taxi-v3 状态编码方法,我们可以执行以下操作:
state = env.encode(3, 1, 2, 0) # (taxi row, taxi column, passenger index, destination index)
print("State:", state)
env.s = state
env.render()
输出:
State: 328

然后我们可以使用 env.s 通过编码数字手动设置环境的状态,也可以自定义这些数字,你会看到出租车、乘客和目的地四处移动。
奖励表
创建 Taxi 环境时,还会创建一个初始 Reward 表,称为“P”。我们可以把它想象成一个矩阵,其中状态数为行,动作数为列,即状态×动作矩阵。
由于每个状态都在这个矩阵中,我们可以看到分配给插图状态的默认奖励值:
env.P[328]
0: [(1.0, 428, -1, False)],
1: [(1.0, 228, -1, False)],
2: [(1.0, 348, -1, False)],
3: [(1.0, 328, -1, False)],
4: [(1.0, 328, -10, False)],
5: [(1.0, 328, -10, False)]
这个字典的结构是 **action: [(probability, nextstate, reward, done)]**。
需要注意的几点:
- 0-5 对应于图中出租车在我们当前状态下可以执行的操作(南、北、东、西、上客、下客)。
- 在此环境中,概率始终为 1.0。
- 如果我们在字典的这个索引处采取了这个行动,nextstate是我们将处于的状态。
- 在此特定状态下,所有移动动作都有 -1 奖励,拾取/放下动作有 -10 奖励。如果我们处于出租车有乘客并且位于正确目的地的状态,我们将在下车动作中得到 20 的奖励
- done 用于告诉我们何时成功地将乘客送到正确的位置。每一次成功的下车都是一集的结束。
请注意,如果我们的智能体选择在此状态下探索的动作撞墙,将继续累积 -1 惩罚,这会影响长期奖励。
传统解决方案
让我们看看如果我们在没有强化学习的情况下尝试暴力解决问题会发生什么。
由于我们在每个状态都有默认奖励的 P 表,我们可以尝试让我们的出租车仅使用它来导航。
我们将创建一个无限循环,该循环一直运行到一名乘客到达一个目的地(一集),或者换句话说,直到收到的奖励为 20 时。 env.action_space.sample() 方法自动从所有集合中选择一个随机动作可能的行动。
import gym
env = gym.make("Taxi-v3")
env.reset()
env.render()
state = env.encode(3, 1, 2, 0) # (taxi row, taxi column, passenger index, destination index)
print("State:", state)
env.s = state
env.s = 328 # set environment to illustration's state
epochs = 0
penalties, reward = 0, 0
frames = [] # for animation
done = False
while not done:
action = env.action_space.sample()
state, reward, done, info = env.step(action)
env.render()
if reward == -10:
penalties += 1
# Put each rendered frame into dict for animation
frames.append(
'frame': env.render(mode='ansi'),
'state': state,
'action': action,
'reward': reward
)
epochs += 1
print("Timesteps taken: ".format(epochs))
print("Penalties incurred: ".format(penalties))
输出:
Timesteps taken: 200
Penalties incurred: 62
效果并不好。我们的智能体需要数千个时间步长,并做出许多错误的下车,才能将一名乘客送到正确的目的地。
这是因为我们没有从过去的经验中学习。我们可以一遍又一遍地运行它,它永远不会优化。智能体不知道哪个动作最适合每个状态,这正是强化学习将为我们做的事情。
强化学习方案
我们将使用一种称为 Q-learning 的简单 RL 算法,它会给我们的智能体一些记忆。
Q-Learning
从本质上讲,Q-learning 让智能体使用环境的奖励来学习,随着时间的推移,在给定状态下采取的最佳行动。
在我们的 Taxi 环境中,我们有奖励表 P,代理将从中学习。它通过查看在当前状态下采取行动而获得奖励,然后更新 Q 值以记住该行动是否有益。
存储在 Q 表中的值称为 Q 值,它们映射到(状态、动作)组合。
特定状态-动作组合的 Q 值代表从该状态采取的动作的“质量”。更好的 Q 值意味着获得更大奖励的机会更大。
例如,如果出租车面临的状态包括乘客在其当前位置,则与其他动作(如下车或北上)相比,上车的 Q 值很可能更高。
Q 值被初始化为任意值,当代理将自己暴露在环境中并通过执行不同的动作接收不同的奖励时,Q 值使用以下等式更新:
Q
(
s
t
a
t
e
,
a
c
t
i
o
n
)
←
(
1
−
α
)
Q
(
s
t
a
t
e
,
a
c
t
i
o
n
)
+
α
(
r
e
w
a
r
d
+
γ
max
a
Q
(
n
e
x
t
s
t
a
t
e
,
a
l
l
a
c
t
i
o
n
s
)
)
Q(\\small state, \\small action) \\leftarrow (1 - \\alpha) Q(\\small state, \\small action) + \\alpha \\Big(\\small reward + \\gamma \\max_a Q(\\small next \\ state, \\small all \\ actions)\\Big)
Q(state,action)←(1−α)Q(state,action)+α(reward+γamaxQ(next state,all actions))
其中:
- α是学习率 (0<α≤1) - 就像在监督学习设置中一样,α 是我们的 Q 值在每次迭代中更新的程度。
- γ是折扣因子 (0≤γ≤1) - 确定我们希望对未来奖励给予多大的重视。折扣因子的高值(接近 1)捕获了长期有效奖励,而 0 的折扣因子使我们的代理只考虑即时奖励,因此使其变得贪婪。
这是什么话?
我们通过首先获取旧 Q 值的权重 (1-α),然后添加学习值来分配 (←) 或更新代理当前状态和动作的 Q 值。学习值是在当前状态下采取当前行动的奖励和一旦我们采取当前行动后我们将处于的下一个状态的折扣最大奖励的组合。
基本上,我们通过查看当前状态/动作组合的奖励以及下一个状态的最大奖励来学习在当前状态下采取的正确动作。这最终将导致我们的出租车考虑将最好的奖励串在一起的路线。
状态-动作对的 Q 值是即时奖励和折扣未来奖励(结果状态)的总和。我们存储每个状态和动作的 Q 值的方式是通过 Q 表。
Q-Table
Q 表是一个矩阵,其中每个状态 (500) 都有一行,每个动作 (6) 都有一列。它首先初始化为 0,然后在训练后更新值。请注意,Q 表与奖励表具有相同的维度,但用途完全不同。
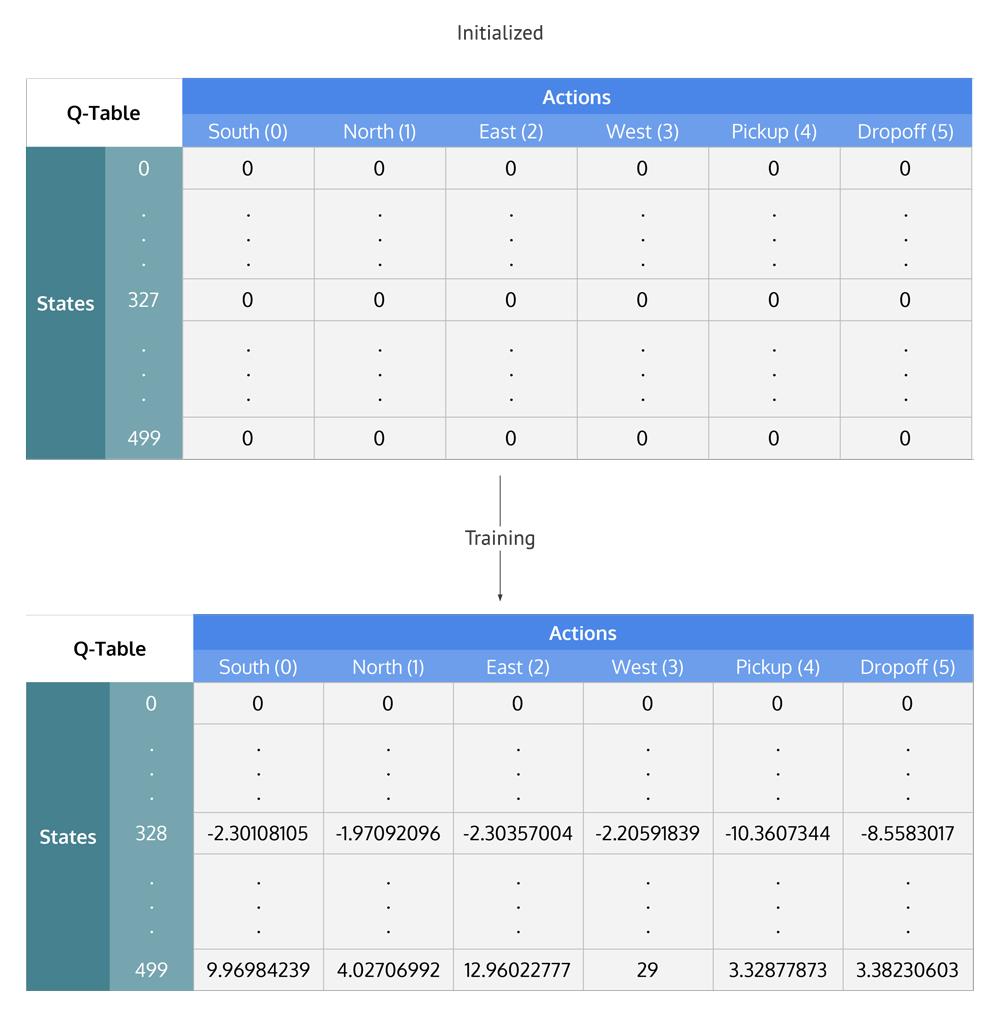
总结 Q-Learning 过程
将其分解为步骤,我们得到
- 用全零初始化 Q 表。
- 开始探索动作:对于每个状态,从当前状态 (S) 的所有可能动作中选择任何一个。
- 作为该动作 (a) 的结果,前往下一个状态 (S’)。
- 对于状态 (S’) 中的所有可能动作,选择具有最高 Q 值的动作。
- 使用等式更新 Q 表值。
- 将下一个状态设置为当前状态。
- 如果达到目标状态,则结束并重复该过程。
利用学习价值
在对动作进行足够的随机探索之后,Q 值趋于收敛,为我们的代理提供动作值函数,它可以利用它从给定状态中选择最佳动作。
在探索(选择随机动作)和利用(根据已经学习的 Q 值选择动作)之间存在权衡。我们希望防止动作总是采用相同的路线,并且可能会过度拟合,因此我们将引入另一个称为 ϵ “epsilon” 的参数以在训练期间迎合这一点。
我们有时会倾向于进一步探索动作空间,而不是仅仅选择最好的学习 Q 值动作。较低的 epsilon 值会导致具有更多惩罚的情节(平均而言),这很明显,因为我们正在探索和做出随机决定。
通过Python实现Q-Learning
训练智能体
首先,我们将 Q 表初始化为一个 500×6 的零矩阵:
import numpy as np
q_table = np.zeros([env.observation_space.n, env.action_space.n])
我们现在可以创建训练算法,当代理在数千个情节中探索环境时更新这个 Q 表。
在尚未完成的第一部分,我们决定是选择随机动作还是利用已经计算的 Q 值。这只需使用 epsilon 值并将其与 random.uniform(0, 1) 函数进行比较即可完成,该函数返回 0 和 1 之间的任意数字。
我们在环境中执行选择的动作以获得 next_state 和执行动作的奖励。之后,我们计算与 next_state 对应的动作的最大 Q 值,然后我们可以轻松地将 Q 值更新为 new_q_value:
import random
import gym
import numpy as np
env = gym.make("Taxi-v3")
env.reset()
# Hyperparameters
alpha = 0.1
gamma = 0.6
epsilon = 0.1
# For plotting metrics
all_epochs = []
all_penalties = []
q_table = np.zeros([env.observation_space.n, env.action_space.n])
for i in range(1, 100001):
state = env.reset()
epochs, penalties, reward, = 0, 0, 0
done = False
while not done:
if random.uniform(0, 1) < epsilon:
action = env.action_space.sample() # Explore action space
else:
action = np.argmax(q_table[state]) # Exploit learned values
next_state, reward, done, info = env.step(action)
old_value = q_table[state, action]
next_max = np.max(q_table[next_state])
new_value = (1 - alpha) * old_value + alpha * (reward + gamma * next_max)
q_table[state, action] = new_value
if reward == -10:
penalties += 1
state = next_state
epochs += 1
print("Training finished.\\n")
现在 Q 表已经建立超过 100,000 集,让我们看看在我们的插图状态下 Q 值是多少:
q_table[328]
输出:
array([ -2.30108105, -1.97092096, -2.30357004, -2.20591839, -10.3607344 , -8.5583017 ])
最大 Q 值是“北”(-1.971),所以看起来 Q 学习已经有效地学习了在我们的插图状态下采取的最佳行动!
评估智能体
让我们评估一下代理的性能。我们不需要进一步探索动作,所以现在总是使用最佳 Q 值选择下一个动作:
total_epochs, total_penalties = 0, 0
episodes = 100
for _ in range(episodes):
state = env.reset()
epochs, penalties, reward = 0, 0, 0
done = False
while not done:
action = np.argmax(q_table[state])
state, reward, done, info = env.step(action)
if reward == -10:
penalties += 1
epochs += 1
total_penalties += penalties
total_epochs += epochs
print(f"Results after episodes episodes:")
print(f"Average timesteps per episode: total_epochs / episodes")
print(f"Average penalties per episode: total_penalties / episodes")
输出:
Results after 100 episodes:
Average timesteps per episode: 12.3
Average penalties per episode: 0.0
从评估中我们可以看出,该代理的性能显着提高,并且没有受到任何处罚,这意味着它对 100 名不同的乘客执行了正确的上车/下车操作。
对比
Q-learning 代理最初在探索过程中会犯错误,但一旦探索足够多(看到大多数状态),它就可以明智地采取行动,最大限度地提高智能移动的回报。 让我们看看与仅进行随机移动的代理相比,我们的 Q 学习解决方案要好得多。
我们根据以下指标评估我们的代理:
- 每集的平均惩罚次数:数字越小,我们的代理的性能越好。理想情况下,我们希望这个指标为零或非常接近于零。
- 每次行程的平均时间步数:我们也希望每集的时间步数较少,因为我们希望我们的代理采取最少的步骤(即最短路径)到达目的地。
- 每次移动的平均奖励:奖励越大意味着代理正在做正确的事情。 这就是为什么决定奖励是强化学习的关键部分。 在我们的例子中,由于时间步长和惩罚都是负奖励,更高的平均奖励意味着代理以最少的惩罚尽快到达目的地”

这些指标是在 100 集以上计算得出的。结果表明,我们的 Q-learning 代理成功了!
超参数与优化
alpha、gamma 和 epsilon 的值主要是基于直觉和一些“试一试”,但有更好的方法来得出好的值。
理想情况下,这三个都应该随着时间的推移而减少,因为随着代理继续学习,它实际上会建立更有弹性的先验;
- α \\Large \\alpha α:随着您继续获得越来越大的知识库,(学习率)应该会降低。
- γ \\Large \\gamma γ:随着你越来越接近最后期限,你对近期奖励的偏好应该会增加,因为你不会有足够长的时间来获得长期奖励,这意味着你的 gamma 应该会降低。
- ϵ \\Large \\epsilon ϵ:随着我们制定策略,我们不再需要探索和更多的利用来从我们的策略中获得更多效用,因此随着试验的增加,epsilon 应该减少。
超参数调参
以编程方式得出最佳超参数值集的一种简单方法是创建一个综合搜索函数(类似于网格搜索),该函数选择将产生最佳奖励/时间步长比的参数。 使用reward/time_steps 的原因是我们希望选择能够让我们尽快获得最大奖励的参数。 我们可能还想跟踪与超参数值组合相对应的惩罚数量,因为这也可能是一个决定因素(我们不希望我们的智能代理以更快到达为代价而违反规则)。 获得正确的超参数值组合的一种更奇特的方法是使用遗传算法。
总结与展望
好吧!我们首先借助现实世界的类比来理解强化学习。然后,我们深入研究了强化学习的基础知识,并将自动驾驶出租车设计为强化学习问题。然后我们在 python 中使用 OpenAI 的 Gym 为我们提供了一个相关的环境,我们可以在其中开发我们的代理并对其进行评估。然后我们观察到我们的代理在不使用任何算法玩游戏的情况下有多糟糕,所以我们从头开始实施 Q-learning 算法。在 Q-learning 之后,智能体的性能显着提高。最后,我们讨论了为我们的算法确定超参数的更好方法。
Q-learning 是最简单的强化学习算法之一。然而,Q-learning 的问题是,一旦环境中的状态数量非常多,使用 Q 表实现它们就变得很困难,因为它的大小会变得非常非常大。最先进的技术使用深度神经网络而不是 Q 表(深度强化学习)。神经网络将状态信息和动作接收到输入层,并随着时间的推移学习输出正确的动作。深度学习技术(如卷积神经网络)也用于解释屏幕上的像素并从游戏中提取信息(如分数),然后让代理控制游戏。
我们已经讨论了很多关于强化学习和游戏的内容。但强化学习不仅限于游戏。它用于管理股票投资组合和财务、制造人形机器人、制造和库存管理、开发通用 AI 代理,这些代理可以使用单一算法执行多项操作,例如同一个代理玩多个 Atari 游戏。 Open AI 还有一个名为 Universe 的平台,用于在无数游戏、网站和其他通用应用程序中测量和训练 AI 的通用智能。
以上是关于从零开始Q-Learning,用强化学习教出租车接送乘客的主要内容,如果未能解决你的问题,请参考以下文章