大数据方向面试问题
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据方向面试问题相关的知识,希望对你有一定的参考价值。
🎶这段时间忙于实习的工作,来字节细细算算,也快4个月了,部门主要是和抖音电商和Tiktok shop相关的业务,具体点的内容不方便透露,新人想要快速成长,疯狂做需求可能是一个不错的选择,但同时也要记得注重思考。
- hadoop专题: hadoop系列文章.
- spark专题: spark系列文章.
- flink专题: Flink系列文章.
🍏本期将一些热点问题进行总结,面试中肯定会问到的,哈哈哈😼,给大家提供参考、很多问题都没有标准答案,大家按照自己的思路去回答即可。当然,如果有其他问题我没有写到,可以评论我,我加上!
tag:20220808只写到flink,后续需要添加
我是目录😊
1. 数据仓库部分
1.1 数据仓库的定义
数据仓库(Data Warehouse)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。
1.2 数据库与数据仓库的区别
目标:数据库是用来处理日常业务产生的数据,主要面向事务处理,需要频繁增、删、改、查操作,数据仓库是各种数据源的汇总,主要是用来支持企业所有级别的决策制定,主要用来分析。
存储:数据库一般存储当前事务发生的数据,如付款、下单等,而数据仓库一般存储历史数据,不需要及时同步。
设计:数据库一般支持3NF,数据仓库设计一般不满足3NF。
1.3 如何构建数据仓库
ER关系实体模型:用实体-关系-实体来描述企业业务,设计要求满足3NF,需要全面了解业务,实施周期长。
维度建模:将数仓的表分为维度表和事实表,常见的有星型模型、雪花模型、星座模型。不满足3NF,用冗余换取查询性能。
Data Vault 模型:ER模型的衍生,其设计的出发点也是为了实现数据的整合,但不能直接用于数据分析决策,强调数据的历史性、可追溯性和原子性,而不要求对数据进行过度的一致性处理和整合。
Anchor 模型:对 Data Vault 模型做了进一步规范化处理,模型规范到 6NF,基本变成了 k-v 结构化模型。
1.4 数仓分层(维度建模来说)
- ODS层(Operational Data Store):该层级主要功能是存储从源系统直接获得的数据(数据从数据结构、数据之间的逻辑关系上都与源系统基本保持一致)。实现某些业务系统字段的数据仓库技术处理、少量的基础的数据清洗(比如脏数据过滤、字符集转换、维值处理)、生成增量数据表。
- DIM层(Dimension):该层主要存储简单、静态、代码类的维表,包括从OLTP层抽取转换维表、根据业务或分析需求构建的维表以及仓库技术维表如日期维表等。
- DWD层(Data Warehouse Detail):该层的主要功能是基于主题域的划分,面向业务主题、以数据为驱动设计模型,完成数据整合,提供统一的基础数据来源。在该层级完成数 据的清洗、重定义、整合分类功能。
- DWM层(Data Warehouse Middle):面向分析主题的、统一的数据访问层,所有的基础数据、业务规则和业务实体的基础指标库以及多维模型都在这里统一计算口径、统一建模,大量基础指标库以及多维模型在该层实现。该层级以分析需求为驱动进行模型设计,实现跨业务主题域数据的关联计算或者轻度汇总计算,因此会有大数据量的多表关联汇总计算。
- DM层(Data Warehouse Model):该层次主要功能是加工多维度冗余的宽表(解决复杂的查询)、多角度分析的汇总表。
- APP层(Application):该层级的主要功能是提供差异化的数据服务、满足业务方的需求;在该层级实现报表(tableau、邮件报表)、自助取数等需求。
1.5 数据仓库分层原因:
清晰数据结构:每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解。
方便数据血缘追踪:简单来说,我们最终给业务呈现的是一个能直接使用业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
把复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
屏蔽原始数据的异常:屏蔽业务的影响,不必改一次业务就需要重新接入数据。
1.6 缓慢变化维度的处理方式
修改维度值:直接修改维度表中的数据,这样晚上数据同步时,之后所有的数据都是新的维度。
插入新的维度行:在维度表中插入新的一行,事实表中的数据和新的维度关联。
添加维度列:在维度表中插入新的一列,作为修改后的字段,历史数据可重新归属。
1.7 事实表分类
事务事实表:单事务事实表(一个业务过程)和多事务事实表(多个业务过程),一般是用来存储当天最细粒度的事实(下单、付款等业务过程)。
周期快照事实表:以预定的间隔采样状态度量,比如自然年至今或者历史至今的下单金额、支付金额、支付买家数的状态数据。(提前算好一个周期之内的汇总数据)
累积快照事实表:计算时间区间数据,希望将业务开始,结束,过程中的状态用一条数据记录下来,而不是发生一个动作就记录一条数据,具有较明确起止时间的短生命周期,这样方便计算duration。
2. Hadoop
2.1 HDFS的架构
Client:文件上传HDFS的时候将文件切分成一个一个的Block(128m);与NameNode交互获取文件地址;与DataNode交互获取或写入数据;提供交互。
NameNode:主节点,存储数据的元数据信息,不存储具体的数据,管理Block,处理Client请求,给DataNode下命令。
DataNode:从节点。NameNode下达命令,DataNode执行实际的操作,存储真实的数据,执行数据的读写操作
Secondary NameNode:NameNode的备份。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务,一般设置两个DataNode来防止挂掉。
2.2 MR中的shuffle操作
shuffle是map任务之后,reduce方法之前的阶段。主要有以下几个阶段:
map方法之后进入环形缓冲区:map方法之后将(k,v)类型的数据输入至100m大小的环形缓冲区,通过getpartition方法将(k,v)数据拼接上分区,索引等信息。
环形缓冲区落盘:当缓冲区的数据达到80%时进行溢出写磁盘的操作,同一个分区里面的数据会进行快速排序和combiner(可选),对多个溢写的文件最后会进行一个归并排序,将它输出到磁盘中。(一个map task只有一个文件,但是缓冲区到80m就会溢写,而且还要加上索引、分区等信息,128m的数据会溢写多个文件,都需要归并排序成一个文件。)
reduce拉取数据:reduce阶段会对上一阶段产生的磁盘文件进行拉取,同一个分区的数据会进入到同一个reduce中进行归并排序和combiner(可选)然后进入对应的reduce方法。
2.3 处理小文件过多
读取数据时,采用CombineTextInputFormat将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个maptask
2.4 shuffle 优化
map端:
- 增大环形缓冲区大小。由100m扩大到200m
- 增大环形缓冲区溢写的比例。由80%扩大到90%
- 减少对溢写文件的merge次数。(10个文件,一次20个merge)
- 不影响实际业务的前提下,采用Combiner提前合并,减少 I/O
reduce端:
5. 合理设置Map和Reduce数:两个都不能设置太少,也不能设置太多。太少,会导致Task等待,延长处理时间;太多,会导致 Map、Reduce任务间竞争资源,造成处理超时等错误。
6. 规避使用Reduce,因为Reduce在用于连接数据集的时候将会产生大量的网络消耗。
7. 设置Map、Reduce共存:调整slowstart.completedmaps参数,使Map运行到一定程度后,Reduce也开始运行,减少Reduce的等待时间。
8. 集群性能可以的前提下,增大Reduce端存储数据内存的大小。
2.5 数据倾斜
- map端提前进行combine,减少传输的数据量
- 区分倾斜key和非倾斜key,对热点值和非热点值分开处理(加盐)
- 用group by 代替count distinct
- map join
3. Hive
3.1 hive的架构
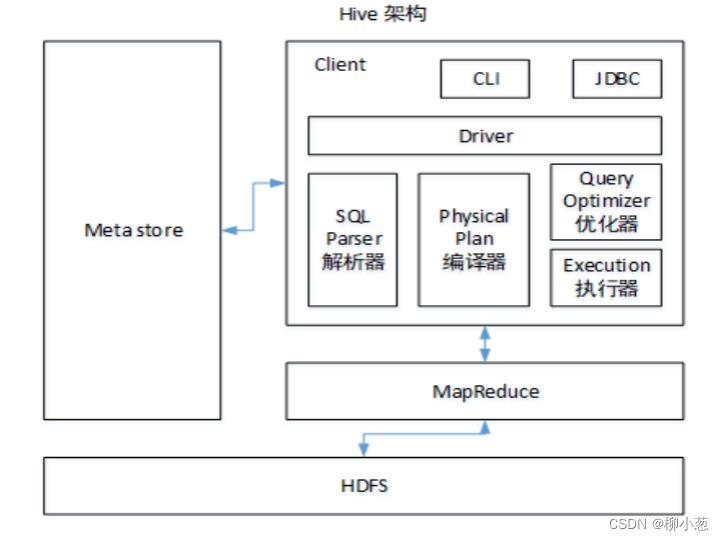
- SQL Parser:Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将SQL 转化为抽象语法树 AST Tree;
- Semantic Analyzer(语法分析器):遍历 AST Tree,抽象出查询的基本组成单元QueryBlock;
- Logical plan:遍历 QueryBlock,翻译为执行操作树 OperatorTree
- Logical plan optimizer: 逻辑层优化器进行 OperatorTree 变换,合并不必要的 ReduceSinkOperator,减少 shuffle数据量
- Physical plan:遍历 OperatorTree,翻译为 MapReduce 任务;
- Logical plan optimizer:物理层优化器进行 MapReduce 任务的变换,
生成最终的执行计划。
3.2 Hive 与数据库交互原理?
前 Hive 将元数据存储在 RDBMS 中,比如存储在 mysql、Derby 中。元数据信息包括:存在的表、表的列、权限和更多的其他信息。可以将 sql语句转换为MapReduce 任务进行运行,对数据进行操作。
3.3 Sort By,Order By,Cluster By,Distrbute By 的含义?
- sort by:分区内排序,一般和distrbute by一起使用
- order by:会对输入做全局排序,因此只有一个 reducer(多个 reducer 无法保证全局有序)。只有一个 reducer,会导致当输入规模较大时,需要较长的计算时间。
- distribute by:按照字段分区
- cluster by:当distribute by 字段和 sort by 字段一样时,可直接使用cluster by
3.3 Hive 内部表和外部表的区别?
- 内部表:创建内部表时,会将数据移动到数据仓库指向的路径;在删除表的时候,内部表的元数据和数据会被一起删除,
- 外部表:若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变;删除外部表时,只删除元数据,不删除数据。
3.4 .Hive 的函数:UDF、UDAF、UDTF 的区别?
- UDF:单行进入,单行输出 (substr、date、month、repeat)
- UDAF:多行进入,单行输出 (count 、sum、max、min)
- UDTF:单行输入,多行输出 (explode、posexplode)
4. Spark
4.1 RDD是什么?解释一下特点。
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。是一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
弹性:
- 存储的弹性:内存与磁盘的自动切换
- 容错的弹性:数据丢失可以自动恢复
- 计算的弹性:计算出错重试机制
- 分片的弹性:可根据需要重新分片(分片是分区的意义😂)
4.2 Spark有几种部署方式?
- Local:运行在一台机器上,通常是练手或者测试环境。
- Standalone:构建一个基于Mster+Slaves的资源调度集群,Spark任务提交给Master运行。是Spark自身的一个调度系统。
- Yarn: Spark客户端直接连接Yarn,不需要额外构建Spark集群。有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点
4.3 什么是宽窄依赖?
- 宽依赖:示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会引起 Shuffle
- 窄依赖:每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用,不会引起 Shuffle
4.4 spark中stage的划分?每个stage又根据什么决定task个数?
- stage:是根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。
- task:Stage是一个task的集合,将Stage根据分区数划分成一个个的Task(多少个分区,就有多少个task)
4.5 转换算子和行动算子有哪些以及区别?
- 转换算子:map、flatmap、reduceByKey、groupByKey…
- 行动算子:reduce、collect、first、take、foreach…
4.6 Repartition和Coalesce关系与区别?
- 两者都是用来改变RDD的partition数量的,repartition底层调用的就是coalesce方法:coalesce(numPartitions, shuffle = true)
- repartition一定会发生shuffle,coalesce根据传入的参数来判断是否发生shuffle一般情况下增大rdd的partition数量使用repartition,减少partition数量时使用coalesce
spark中的缓存机制(cache和persist)和checkpoint机制的区别?
- cache:内存,不会截断血缘关系,使用计算过程中的数据缓存。
- checkpoint:磁盘,截断血缘关系,在ck之前必须没有任何任务提交才会生效,ck过程会额外提交一次任务。
5. flink (未完待续…date=20220808)
6. 参考资料
- 《阿里巴巴大数据之路》
- 《数据仓库工具箱》
- 《hadoop权威指南》
- 《尚硅谷之spark学习》
- 《spark权威指南》
以上是关于大数据方向面试问题的主要内容,如果未能解决你的问题,请参考以下文章
面试中的项目介绍怎么介绍?从哪些方面介绍?一文搞明白(大数据方向,其他方向可借鉴)
面试中的项目介绍怎么介绍?从哪些方面介绍?一文搞明白(大数据方向,其他方向可借鉴)