MySQL索引的Index method中btree和hash的区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL索引的Index method中btree和hash的区别相关的知识,希望对你有一定的参考价值。
hash 分片理解了散列表的基本特点,再来看看分布式数据库的 hash 分片。
hash 分片设计的要点:
1. 固定的数据映射到固定的节点 / 槽位
2. 数据分布均匀
3. 扩容方便
主要是扩容时尽可能移动较少的数据。扩容之后实现新的数据分布均匀。
想要实现动态扩容,尽可能不影响业务并保证效率,需要做到移动尽可能少的数据,一致性 hash 就是为了解决移动较少数据的问题,但是一致性 hash 的缺点是数据分布的均匀性较差。为了解决这个问题,聪明的 dev 们又设计了跳增一致性 hash 算法。
到这里,可以看出 hash 与分片最紧密或者说最神似的点在于:
1. 固定的输入有固定的输出
2. 值呈均匀分布
如果分布式数据库的分片数据分布不均匀,最糟情况就像散列表的极端冲突一样,落在最终数据库上的压力跟不使用分布式相同。
3. 方便扩容
当分片填充满的时候,需要扩容使总数据量在总分片之间再次达到数据均匀分布状态,扩容需要用 hash 函数重新映射旧值到新的分片。
4. 散列表和 hash 分片想要有好的表现都依赖于设计良好的 hash 函数。
正是由于这些相似特点,Hash 在分布式数据库里得到比较多的使用。回到测试的老本行,这些点便是我们测试思考的重点。 参考技术A *nix系系统:
ES(Unix)
例子: IvS7aeT4NzQPM
说明:Linux或者其他linux内核系统中
长度: 13 个字符
描述:第1、2位为salt,例子中的'Iv'位salt,后面的为hash值
系统:MD5(Unix)
例子:$1$12345678$XM4P3PrKBgKNnTaqG9P0T/
说明:Linux或者其他linux内核系统中
长度:34个字符
描述:开始的$1$位为加密标志,后面8位12345678为加密使用的salt,后面的为hash
加密算法:2000次循环调用MD5加密
系统:SHA-512(Unix)
例子:$6$12345678$U6Yv5E1lWn6mEESzKen42o6rbEm
说明:Linux或者其他linux内核系统中
长度: 13 个字符
描述:开始的$6$位为加密标志,后面8位为salt,后面的为hash
加密算法:5000次的SHA-512加密
系统:SHA-256(Unix)
例子:$5$12345678$jBWLgeYZbSvREnuBr5s3gp13vqi
说明:Linux或者其他linux内核系统中
长度: 55 个字符
描述:开始的$5$位为加密标志,后面8位为salt,后面的为hash
加密算法:5000次的SHA-256加密
系统:MD5(APR)
例子:$apr1$12345678$auQSX8Mvzt.tdBi4y6Xgj.
说明:Linux或者其他linux内核系统中
长度:37个字符
描述:开始的$apr1$位为加密标志,后面8位为salt,后面的为hash
加密算法:2000次循环调用MD5加密
windows系统:
windows
例子:Admin:b474d48cdfc4974d86ef4d24904cdd91
长度:98个字符
加密算法:MD4(MD4(Unicode($pass)).Unicode(strtolower($username)))
mysql
系统:mysql
例子:606717496665bcba
说明:老版本的MySql中
长度:8字节(16个字符)
说明:包括两个字节,且每个字的值不超过0x7fffffff
系统:MySQL5
例子:*E6CC90B878B948C35E92B003C792C46C58C4AF40
说明:较新版本的MySQL
长度:20字节(40位)
加密算法:SHA-1(SHA-1($pass))
其他系统:
系统:MD5(WordPress)
例子:$P$B123456780BhGFYSlUqGyE6ErKErL01
说明:WordPress使用的md5
长度:34个字符
描述:$P$表示加密类型,然后跟着一位字符,经常是字符‘B’,后面是8位salt,后面是就是hash
加密算法:8192次md5循环加密
系统:MD5(phpBB3)
说明:phpBB 3.x.x.使用
例子:$H$9123456785DAERgALpsri.D9z3ht120
长度:34个字符
描述:开始的$H$为加密标志,后面跟着一个字符,一般的都是字符‘9’,然后是8位salt,然后是hash 值
加密算法:2048次循环调用MD5加密
系统:RAdmin v2.x
说明:Remote Administrator v2.x版本中
例子:5e32cceaafed5cc80866737dfb212d7f
长度:16字节(32个字符)
加密算法:字符用0填充到100字节后,将填充过后的字符经过md5加密得到(32位值)
md5加密
标准MD5
例子:c4ca4238a0b923820dcc509a6f75849b
使用范围:phpBB v2.x, Joomla 的 1.0.13版本前,及其他cmd
长度:16个字符
其他的加salt及变形类似:
md5($salt.$pass)
例子:f190ce9ac8445d249747cab7be43f7d5:12
md5(md5($pass))
例子:28c8edde3d61a0411511d3b1866f0636
md5(md5($pass).$salt)
例子:6011527690eddca23580955c216b1fd2:wQ6
md5(md5($salt).md5($pass))
例子: 81f87275dd805aa018df8befe09fe9f8:wH6_S
md5(md5($salt).$pass)
例子: 816a14db44578f516cbaef25bd8d8296:1234
MySQL 5.6 Index Condition Pushdown
ICP(index condition pushdown)是mysql利用索引(二级索引)元组和筛字段在索引中的where条件从表中提取数据记录的一种优化操作。ICP的思想是:存储引擎在访问索引的时候检查筛选字段在索引中的where条件(pushed index condition,推送的索引条件),如果索引元组中的数据不满足推送的索引条件,那么就过滤掉该条数据记录。ICP(优化器)尽可能的把index condition的处理从server层下推到storage engine层。storage engine使用索引过过滤不相关的数据,仅返回符合index condition条件的数据给server层。也是说数据过滤尽可能在storage engine层进行,而不是返回所有数据给server层,然后后再根据where条件进行过滤。使用ICP(mysql 5.6版本以前)和没有使用ICP的数据访问和提取过程如下(插图来在MariaDB Blog)
优化器没有使用ICP时,数据访问和提取的过程如下:
1) 当storage engine读取下一行时,首先读取索引元组(index tuple),然后使用索引元组在基表中(base table)定位和读取整行数据。
2) sever层评估where条件,如果该行数据满足where条件则使用,否则丢弃。
3) 执行1),直到最后一行数据。
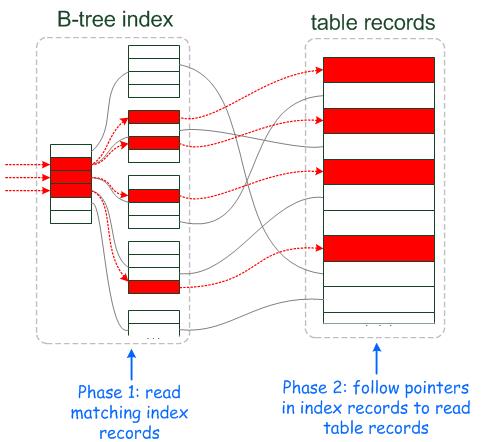
优化器使用ICP时,server层将会把能够通过使用索引进行评估的where条件下推到storage engine层。
数据访问和提取过程如下:
1) storage engine从索引中读取下一条索引元组。
2) storage engine使用索引元组评估下推的索引条件。如果没有满足where条件,storage engine将会处理下一条索引元组(回到上一步)。只有当索引元组满足下推的索引条件的时候,才会继续去基表中读取数据。
3) 如果满足下推的索引条件,storage engine通过索引元组定位基表的行和读取整行数据并返回给server层。
4) server层评估没有被下推到storage engine层的where条件,如果该行数据满足where条件则使用,否则丢弃。
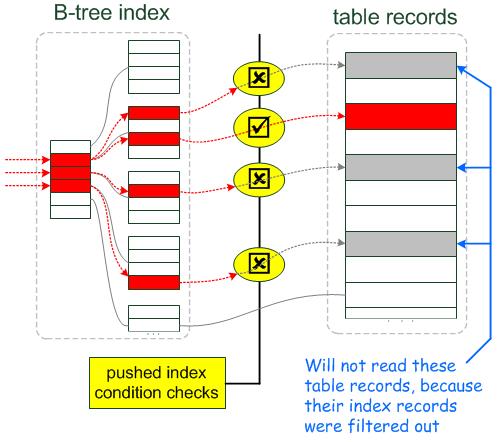
而使用ICP时,如果where条件的一部分能够通过使用索引中的字段进行评估,那么mysql server把这部分where条件下推到storage engine(存储引擎层)。存储引擎通过索引元组的索引列数据过滤不满足下推索引条件的数据行。
索引条件下推的意思就是筛选字段在索引中的where条件从server层下推到storage engine层,这样可以在存储引擎层过滤数据。由此可见,ICP可以减少存储引擎访问基表的次数和mysql server访问存储引擎的次数。
注意一下ICP的使用条件:
1.只能用于二级索引(secondary index)。
2.explain显示的执行计划中type值(join 类型)为range、 ref、 eq_ref或者ref_or_null。且查询需要访问表的整行数据,即不能直接通过二级索引的元组数据获得查询结果(索引覆盖)。
3.ICP可以用于MyISAM和InnnoDB存储引擎,不支持分区表(5.7将会解决这个问题)。
ICP的开启优化功能与关闭
MySQL5.6可以通过设置optimizer_switch([global|session],dynamic)变量开启或者关闭index_condition_push优化功能,默认开启。
mysql > set optimizer_switch=\'index_condition_pushdown=on|off\'
用explain查看执行计划时,如果执行计划中的Extra信息为"using index condition",表示优化器使用的index condition pushdown。
在mysql5.6以前,还没有采用ICP这种查询优化,where查询条件中的索引条件在某些情况下没有充分利用索引过滤数据。假设一个组合索引(多列索引)K包含(c1,c2,…,cn)n个列,如果在c1上存在范围扫描的where条件,那么剩余的c2,…,cn这n-1个上索引都无法用来提取和过滤数据(不管不管是唯一查找还是范围查找),索引记录没有被充分利用。即组合索引前面字段上存在范围查询,那么后面的部分的索引将不能被使用,因为后面部分的索引数据是无序。比如,索引key(a,b)中的元组数据为(0,100)、(1,50)、(1,100) ,where查询条件为 a < 2 and b = 100。由于b上得索引数据并不是连续区间,因为在读取(1,50)之后不再会读取(1,100),mysql优化器在执行索引区间扫描之后也不再扫描组合索引其后面的部分。
接下来我们来看看一个例子:

mysql> select version(); +-------------+ | version() | +-------------+ | 5.5.25a-log | +-------------+ 1 row in set (0.00 sec) mysql>
mysql> show create table rental\\G
*************************** 1. row ***************************
Table: rental
Create Table: CREATE TABLE `rental` (
`rental_id` int(11) NOT NULL AUTO_INCREMENT,
`rental_date` datetime NOT NULL,
`inventory_id` mediumint(8) unsigned NOT NULL,
`customer_id` smallint(5) unsigned NOT NULL,
`return_date` datetime DEFAULT NULL,
`staff_id` tinyint(3) unsigned NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`rental_id`),
UNIQUE KEY `rental_date` (`rental_date`,`inventory_id`,`customer_id`),
KEY `idx_fk_inventory_id` (`inventory_id`),
KEY `idx_fk_customer_id` (`customer_id`),
KEY `idx_fk_staff_id` (`staff_id`),
CONSTRAINT `fk_rental_customer` FOREIGN KEY (`customer_id`) REFERENCES `customer` (`customer_id`) ON UPDATE CASCADE,
CONSTRAINT `fk_rental_inventory` FOREIGN KEY (`inventory_id`) REFERENCES `inventory` (`inventory_id`) ON UPDATE CASCADE,
CONSTRAINT `fk_rental_staff` FOREIGN KEY (`staff_id`) REFERENCES `staff` (`staff_id`) ON UPDATE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=16050 DEFAULT CHARSET=utf8
1 row in set (0.03 sec)
mysql>
在没有使用ICP情况下的查询:
mysql> explain select * from rental where rental_date = \'2006-02-14 15:16:03\' and customer_id >= 300 and customer_id <= 400; +----+-------------+--------+------+--------------------------------+-------------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+--------------------------------+-------------+---------+-------+------+-------------+ | 1 | SIMPLE | rental | ref | rental_date,idx_fk_customer_id | rental_date | 8 | const | 181 | Using where | +----+-------------+--------+------+--------------------------------+-------------+---------+-------+------+-------------+ 1 row in set (0.00 sec) mysql>
优化器首先使用复合索引rental_date的首字段rental_date过滤出符合条件rental_date=\'2006-02-14 15:16:03\'的记录(执行计划中key字段显示rental_date),然后根据复合索引rental_date回表获取记录后,最终根据条件customer_id >= 300 and customer_id <= 400来过滤出最后的查询结果(执行计划中Extra字段显示为Using where)
下面看看开启ICP的情况(MySQL 5.6支持)
mysql> select version(); +-----------+ | version() | +-----------+ | 5.6.10 | +-----------+ 1 row in set (0.01 sec) mysql>
mysql> explain select * from rental where rental_date = \'2006-02-14 15:16:03\' and customer_id >= 300 and customer_id <= 400; +----+-------------+--------+------+--------------------------------+-------------+---------+-------+------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+--------------------------------+-------------+---------+-------+------+-----------------------+ | 1 | SIMPLE | rental | ref | rental_date,idx_fk_customer_id | rental_date | 5 | const | 181 | Using index condition | +----+-------------+--------+------+--------------------------------+-------------+---------+-------+------+-----------------------+ 1 row in set (0.00 sec) mysql>
Using index condition 就表示MySQL使用了ICP来优化查询,在检索的时候把条件customer_id的过滤操作下推到存储引擎层来完成。这样能降低不必要的IO访问。
1.首先存储引擎根据条件rental_date = \'2006-02-14 15:16:03\'和customer_id >= 300 and customer_id <= 400来过滤索引,在索引上过滤customer_id条件
2.根据索引过滤后的记录获取数据
参考资料
http://olavsandstaa.blogspot.co.uk/2011/04/mysql-56-index-condition-pushdown.html
以上是关于MySQL索引的Index method中btree和hash的区别的主要内容,如果未能解决你的问题,请参考以下文章