C++面试题合集
Posted 小丑快学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++面试题合集相关的知识,希望对你有一定的参考价值。
C++面试题
最近发现学习 C++ 遇到了一些瓶颈,所以打算有空就积累几道面试题,复习巩固一下之前学习的知识。
1.大端存储和小端储存?
大端模式: 数据的高字节保存在内存的低地址中。
小端模式:高字节保存在内存的高地址中。
总结起来就是小端存储方式中数据较高字节的放在储存器的较高的地址位置,数据的较低的字节放在较低的存储器位置。而大端存储方式则是数据较高的字节存放于存储器较低的地址中。
存储 0x12345678 如下:
大端
低地址 --------------------> 高地址
0x12 | 0x34 | 0x56 | 0x78
小端
低地址 --------------------> 高地址
0x78 | 0x56 | 0x34 | 0x12
应用场景: socket编程中网络字节序一般是大端存储,一般x86、ARM架构的平台中都是以小端存储,因此当我们在发送一个数据到网络之前需要使用系统提供的字节序转换函数htonl()将其转换成大端法存放的数值;
为什么要区分大小端:因为大小端有着各自的优点,比如小端存储当进行强制类型转换时不需要进行字节内容的调整,直接按照数据的大小尽心截断即可。而大端储存方式中符号位永远位于第一个字节,很方便判断正负。
判断大小端的方式:
1.通过强制类型转换实现截断查看数据值:
void enddian_test()
int a = 1;
char c = *(char*)&a;
if (1 == c)
cout << "little end" << endl;//小端
else
cout << "big end" << endl;
- 利用联合体的共享内存特性查看数据
union
int a;
char b;
c;
void enddian_test()
if(c.b == 1)
cout <<"little end"<< endl;
else
cout << "big end" << endl;
2. Virtual 关键字的作用 构造函数和析构函数能不能定义为虚函数?
virtual关键字在C++中主要有两种作用,分别为修饰函数为虚函数和指定继承为虚继承。
1. virtual修饰函数
被 virtual 关键字修饰的函数为虚函数,虚函数主要用于多态机制,也就是当我们在一个继承体系中想要用基类的指针或者引用去调用子类对象的某个函数,则该函数在该继承体系中应该声明为虚函数,这样才能够实现在运行期的动态绑定。而虚函数的实现机制则是由编译器维护一个虚函数表实现。往往友元函数 、构造函数、static函数不能用virtual关键字修饰。普通成员函数和析构函数可以用 virtual 关键字修饰。
虚析构函数
实际上在任何含有虚函数的继承体系中,我们应该把析构函数定义为虚函数,因为倘若我们通过一个基类指针去销毁一个子类的对象的时候,如果该类仅有非虚的析构函数那么我们将无法完成对子类部分的销毁,因而编译器将会表现出未定义行为。如果该继承体系中未涉及虚函数,那该继承体系一般不会用到多态,则我们不需要定义虚析构函数,因为虚函数将会导致编译器维护一张虚函数表,这显然是一种浪费。
详情请参考《Effective C++》中的条款07。
构造函数不能定义为虚函数
为什么说构造函数不能是虚函数呢?因为编译器对虚函数的实现机制是通过维护一张虚函数表实现的,而我们创建一个对象主要分为两个步骤,首先当然是调用 mallco 分配一块合适大小的内存空间,然后才是会调用构造函数对这块内存空间进行初始化,当然这个初始化步骤也包括虚函数表的维护,因此构造函数的调用要先于虚函数表的初始化,因而构造函数是不能定义为虚函数的。
特别注意 在析构函数和构造函数张中不能调用虚函数!!
因为在基类构造和析构期间,我们不能调用派生类的函数,也就是说,构造和析构期间的虚函数不在是虚函数。在调用基类的构造期间,对象的类型将会是基类,而非派生类,不仅仅是虚函数会被解析为基类的虚函数,包括dynamic_cast、dypeid等的解析结果也会将其解析为基类。 同样,这也适合析构函数,一旦基类的析构开始,派生类的对象将会表现为未定义行为。详情请参考《Effective C++》中的条款09。
2. virtual修饰继承
virtual 修饰继承则被称为虚继承,什么是虚继承呢?当涉及到多继承的时候,可能会出现一个基类对象被重复继承多次的现象,如 iosream 的继承体系中就用到了就涉及到虚机继承和多继承问题。下图中的继承方式:
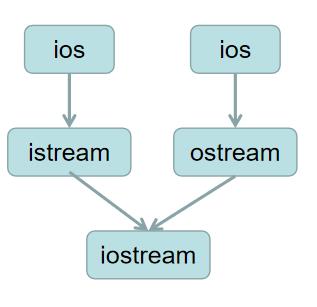
这种继承方式中就会出现 ios 被继承两次的情况,那么如果采用传统的继承方式我们就需要在 iostream 对象中保留两个 ios 的对象,从而导致内存空间的浪费。那么如果我们采用虚继承的方式我们则只会在 iosream 中保留一个 ios 对象,虚继承如下图:
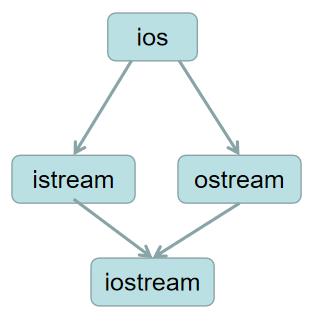
具体虚继承是如何实现的可参考《深入探索C++对象模型》第 116 页。
3. extern
1. extern 修饰变量或者函数
extern可以置于变量或者函数前,以标示变量或者函数的定义在别的文件中,提示编译器遇到此变量和函数时在其他模块中寻找其定义。
在一个文件中引用另一个文件的非静态全局变量或者函数,只要不是被 static 修饰的全局变量都是可以在其他文件中引用的。如下文件:main.c
#include<stdio.h>
extern int a;
extern void fun();
int main()
printf("%d\\n",a);
fun();
return 0;
a.c
#include<stdio.h>
int a = 10;
void fun()
printf("extren test\\n");
执行以下命令:
gcc -c a.c
gcc -c main.c
gcc a.o main.o -o test
./test
可以打印出结果为:
10
extren test
这儿 extern 只能将其他文件中的非静态全局变量引入,如果是局部变量或者说是静态全部变量则不行,因为 static 修饰全局变量则将会全局变量的作用域限制在它所在的文件内。注意 extern int a = 10; 这样的语句是不合法的,extern 只能将变量引入,但是不能在引入的同时进行赋值。
虽然说我们通过包含整个头文的方式也能访问某个文件中的变量,但是包含整个头文件的方式这就使得风险变大了,包含整个头文件有可能导致命名冲突或者使得数据的作用域变大,这不符合封装性的特点,而且也会给项目的编译带来一些问题。
2. extren “C”
参考链接:extern “C”
extern "C"的主要作用就是为了能够正确实现 C++ 代码调用其他C语言代码。加上 extern “C” 后,会指示编译器这部分代码按 C 语言的方式进行编译,而不是 C++ 的方式。作为一种面向对象的语言,C++支持函数重载,而 C 则不支持。C++实现重载技术的方式是将每个同名的重载函数重新以某种方式命名(往往该名字和函数的参数联系起来),使得该命名在符号表中全局唯一,这样程序链接期间便不会出问题,但是 C 语言中一直都不支持函数重载,因而在 C 编译器编译的函数在符号表中的名字和 C++ 编译器在符号表中的名字不同,因而就会导致链接过程失败,一般为符号未定义行为。所以 extern “C” 主要实现C++与 C 及其它语言的混合编程。
linux系统下同一个文件夹中分别编写以下文件:
- test.h
void test(int,int);
- test.c
#include<stdio.h>
#include"test.h"
void test(int a, int b)
printf("%d ,%d",a,b);
- mian.c
#include"test.h"
int main()
test(1,3);
return 1;
- main_cpp.cc
#include"test.h"
int main()
test(1,3);
return 1;
用命令
gcc -c test.c
gcc -c main.c
将上述文件分别编译成 test.o 和 main.o
使用命令 gcc main.o test.o -o test 发现用 c++ 编译器可以正常运行程序。 现在我们用 c++编译器 g++编译一个 main 函数的目标文件。
创建 C++文件 main_cpp.cc 内容和 main.c 文件一样。
使用命令:
g++ -c main_cpp.cc
编译生成文件 main_cpp.o,然后执行链接命令。
g++ main_cpp.o test.o -o test_cpp
这时将会的到
main_cpp.o: In function main': main_cpp.cc:(.text+0xf): undefined reference to test(int, int)’
collect2: error: ld returned 1 exit status
这样的错误。
现在我们将 test.h 改为这样:
#ifdef __cplusplus
extern "C"
#endif
void test(int,int);
#ifdef __cplusplus
#endif
现在重新执行以下命令:
g++ -c main_cpp.cc
g++ main_cpp.o test.o -o test_cpp
这时便可以得到可执行文件,并能成功的运行。
所以extern C 主要的作用便是让C++ 和 C 真正的”兼容“。
4. static 的作用
-
声明静态局部变量
所谓静态局部变量就是仅在某些局部的区域内可以访问,但是能够表现出全局变量的特性的变量。比如在某个函数的局部区域内定义变量时加上 static 则该变量被称为静态局部变量,该变量将会被分配到静态存储区域而不是分配函数的栈空间中,这样当下一次运行该函数静态局部变量的值将会保持上一次运行函数结束的值,也就是说改静态局部变量仅被初始化一次,在函数的区域内表现全局特性,这样便可以将该变量的访问区域减小,使得数据的封装性更好。 -
将函数或者变量限制在一个源文件内
被 static 关键字修饰的全局函数或者全局变量的作用域将会被限制到声明该变量的文件内,即使是使用 extern 关键字也不能将该变量引入到其他文件中。这样可以解决多文件中命名冲突的问题。 -
static 修饰类成员
当 static 修饰类成员时则表该变量属于整个类,而非属于某个特定的对象。换句话说就是该变量被所有的对象所共享,同时我们也可以通过类名和作用域运算符( : : )来访问该变量。特别的,当 static 修饰类成员函数时该函数在编译器的实现机制中将不会把 this 指针作为参数传入,因而静态成员函数就相当于是一个非成员函数,因而静态成员函数只能访问静态数据和静态成员函数,但是这个时候我们可以将某个静态成员函数作为泛型算法或者某个回掉函数的谓词。
5. C 和 C++ 的有什么区别?
借用《Effective C++》中的一段话解释。

以上是从全局的观点说出来 C 语言和 C++ 语言的不同和联系,我们也可以从具体的语法上来进行说明不同,像诸如 C 语言中没有引用、没有函数重载,C 语言中动态分配内存直接用 malloc 而 C++ 中则使用 new 运算来分配等等。
6. 指针和引用的区别
指针和引用最大的区别便是指针是一个变量类型,指针变量中存放的时一个地址,而引用则是一个变量的一个别名。
int a = 0;
int* p = &a;
int &b = a;
本质的区别:
上述的代码中的 p 便是一个指针,其存放的是变量 a 在内存中的地址,而 b 则是变量 a 的一个别名,也就是 a 和 b 实际上一个东西,就像鲁迅是周树人的一个笔名一样。因而我们对 b 执行任何操作实际上就是对 a 执行。我们如果对一个指针取地址则我们得到的便是在内存中存放这个指针的地址。如果我们对一个引用进行取地址我们则会得到这个引用所引用的变量的地址。
int a = 0;
int* p = &a;
int& b = a;
cout << &p << endl;// 输出存放指针p本身的地址
cout << p << endl;//输出指针指针指向的地址
cout << &b << endl;//输出引用 b 引用变量的地址
cout << &a << endl;//输出变量 a 的地址
上述的代码在我的主机上运行结果如下:
000000F5DF8FF9D8
000000F5DF8FF9B4
000000F5DF8FF9B4
000000F5DF8FF9B4
可以发现指针 p, &b, &a 三个结果是一样的,因为指针 p 指向 a , 而 b 和 a 本身是一样的,因而他们输出的地址是一样的。所以引用和变量本身映射到同一个内存地址中的,实际上当编译器在编译程序时会生成一个符号表,在符号表中指针符号对应的是指针本身的地址单元,而引用符号对应的则是引用变量的地址单元。也就是说上述程序中的 a 和 b 两个符号在符号表中对应的地址空间实际上是同一个内存地址单元,也就是存放变量 a 的地址单元。
使用的区别
- 引用必须在声明时初始化,也就是说引用的不能为空,而且一个引用一旦和一个变量绑定,则该引用将不能在和其他的变量绑定,也就是一个引一旦指定为一个变量的别名,则将不能改变。而指针则可以在任何时候初始化,非 const 指针可以在任何时候被重新赋值。
- 函数参数传递,我们实际上为了提高函数传递参数的效率,我们往往会采用传引用或者传指针的方式进行传递。但是指针有可能传入空指针,因而需要进行空指针判断,但是对于引用则不存在空引用一说,因而能提高一些效率。
7. 如何让 .h 文件不被重复引用
C/C++ 中的头文件如果被重复的包含轻则增加编译时间,重则会发生错误,特别是大型项目中,将会涉及到大量的头文件的,因而我们需要某种手段来避免头文件被重复的包含进进项目中。
1. #ifndef
一般采用的方式便是通过预定义的方式来实现。针对于每一个头文件,头文件中加上这样的条件编译框架。
#ifndef _HEADERFILENAME_H
#define _HEADERFILENAME_H
/*
..........
..........
头文件的内容
..........
..........
*/
#endif
上述条件编译中的 HEADERFILENAME 应该换为相应的头文件的名字,比如有一个文件为 test.h 则上述的框架应为如下:
#ifndef _TEST_H
#define _TEST_H
/*
..........
..........
头文件的内容
..........
..........
*/
#endif
这样当这个头文件被编译过后,那么宏 _ TEST_H 就已经定义过了,所以只有第一次编译该头文件的时候该宏才会被定义 ,那么当再次遇到该头文件时由于该宏已经定义过了,所以编译器就会忽略掉该头文件的内容。
2. #pragmaonce
上述的预定义方式来避免头文件被重复包含实在 C++ 语言层面解决了头文件重复包含的问题。而 #pragmaonce 则是在编译器层面解决头文件重复包含的问题,其具体使用方法为在头文件的开头出定义这样的语句便可。
#pragmaonce
/*
头文件内容
*/
#pragmaonce 通过标记一个头文件来避免头文件的重复包含,但是 #pragmaonce 不能对一个代码段进行声明,且如果某个编译器不支持 #pragmaonce 则使用该方式的代码则不能移植到这样的平台上,但是使用 #pragmaonce 则不要考虑宏名字冲突的问题。
8. i++ 和 ++i 的区别
参考链接: https://www.zhihu.com/question/19811087/answer/2165498847
实际上这个问题通过网上的查找得到的很多答案的争议也是挺大的,但是上述的链接是一个我认为比较靠谱的答案。
首先当仅仅是在使用 i++ 和 ++i 作为单独的运算的话,这两者实际上并没有区别,而在编译器下他们的会汇编代码也是一样的。就向下面的两个函数的汇编指令代码是一样的;
void fun()
int i = 0;
i++;
void fun_1()
int i = 0;
++i;
但是当 i++ 和 ++i 分别参与运算的时候这将会产生区别。将上述代码修改如下:
void fun()
int i = 0;
a = i++;
void fun_1()
int i = 0;
a = ++i;
修改后的代码 ++i 的函数的汇编代码将会比 i++ 的汇编代码少一到两条,这是因为 i++ 的实现将会产生一个临时变量,也就是说实际上会先产生一个临时变量记住 i 原有的值, 然后在将 i 自加 1,而之后参与运算的则是这个临时的变量。而 ++i 则是让 i 变量自加,然后让 i 变量本身参与运算。这也就是说 i++ 是一个右值, 而 ++i 则是一个左值。也许这对于一个 int 类型的数据来说可能这并不能体现出性能上的差异,毕竟一两条指令并不能说明什么。但是 C++ 语言是一门面向对象的语言,而且同时能够允许我们重载操作运算符,那么对于一个用户自定义的对象,我们应该怎样去重载 ++这个运算符呢? 在《More Effective C++》的 Item M6 中有这样的代码:
//前缀类型
UPInt& UPInt::operator++(int)
*this += 1; //增加
reurn *this; //取回值
// 后缀类型
const UPInt UPInt::operator++(int)
UPInt oldValue = *this; // 取回值
++(*this); // 增加
return oldValue; // 返回被取回的值
上述代码是对于 int 类型的两种类型的 ++ 操作运算符进行了重载,我们可以看出对于后缀形式的 ++ 运算符的重载会有一个临时变量,而对构造这个临时变量显然会使得程序的效率变得更低,特别是一个比较复杂的对象的临时变量的构造将会花费大量的时间,因而 这种情况下 ++ 前缀运算符的效率将会体现出来。
9. 指针函数和函数指针
区别:
指针函数:返回值为一个指针的函数,是一个函数。
函数指针:指向函数的指针,是一种指针类型。
指针函数:
实际上与普通的函数是一样的,只是其返回的是一个对象的指针,一旦函数返回的是指针或者引用的时候我们就应该注意我们不能返回一个局部与函数的对象的指针或者引用,因为一旦函数的调用结束,那么这些函数局部变量将会被释放,因为这些变量是分配到栈上的,而一旦函数调用结束那么函数占用的占空间将会被释放。如果我们返回的是一个局部变量的指针那么当函数结束后这个指针将会是一个指向内存被释放的地址,这就可能导致我们将回去访问一个未知的地址。因此指针函数返回的指针只能是指向全局变量、静态局部变量(两者均分配到全局存储区)、或者分配到堆上的变量(使用malloc 或者 new 分配的对象)。
函数指针:
函数指针是一个指向函数入口地址的指针,其声明形式和普通的指针有所区别,需要明确的包含函数的返回类型和参数类型,如下:
return_type (*pointer_name) (arg_name1, arg_name2, ... )
如下的函数:
void fun( int a, int b );
如果我们要定义一个指向函数 fun 的函数指针,则我们应该如下定义
void (*p) (int,int);
p = fun;//指向函数
p(4, 5);//等同于 fun(4, 5)
函数指针最大的用处就是作为回调函数,也就是说,我们可以将一个函数作为另一个函数的参数传入到函数中。比如Linux 下的线程函数就是通过回调函数的方式传入一个函数作为线程的任务。如下是一个线程的示例:
#include<stdio.h>
#include<pthread.h>
void* fun1(void)
printf("this is a test thread\\n");
return (void *)0;
int main(int argc,char *argv[])
pthread_t tid1;
if(pthread_create(&tid1,NULL, (void *)fun1, NULL))
printf("error\\n");
return 0;
//等待线程回收
pthread_join(tid1,NULL);
return 0;
当我们将fun1作为线程的任务时我们则需要将函数的名字传入到线程创建函数中,而函数名对应的参数则是一个函数指针。
10.什么是智能指针的循环引用?如何解决。
所谓的智能指针的循环引用指的是两个类相互含有指向对方的 shared_ptr,并且两个对象相互引用,这就会导致循环引用的问题。如下的代码:
class B;
class A
public:
shared_ptr<B> ptr;
class B
public:
shared_ptr<A>ptr;
shared_ptr<A> p_A(new A());
shared_ptr<B> p_B(new B());
P_A->ptr = p_B;
p_B->ptr = p_A;
像上述的代码就会出现循环引用的的问题,显然对于 类 A 而言,有两个智能指针引用其对象,同样对于 B 而言也是有两个指针指向其对象,当程序结束后,A 中的指向 B 的智能指针还在引用 B 的对象,因而 p_B 并不释放该对象。同理 p_A 也不会释放该其引用的对象。这就是智能指针的循环引用的问题。
循环引用问题的解决方案是利用 weak_ptr 进行解决的,wreak_ptr 就是只是引用对象,但是并不会增加对象的引用计数。我们只需要将上述类中的智能指针改为 weak_ptr 即可。代码如下:
class B;
class A
public:
weak_ptr<B> ptr;
class B
public:
weak_ptr<A>ptr;
shared_ptr<A> p_A(new A());
shared_ptr<B> p_B(new B());
P_A->ptr = p_B;
p_B->ptr = p_A;
因为 weak_ptr 仅仅是会引用对象的值而不会增加引用计数,因而当程序结束时将会成功的将两个分配到堆上的对象释放。
11.数组和指针的区别
指针和数组的最大区别便是指针是一个存放一个内存单元的变量,而数组则是可以理解为一块存放数据的连续内存。如果我们用 sizeof 计算数组的大小则我们可以得到数组的容量的大小,但是如果我们对一个指针用 sizeof 计算其大小则我们将会的到一个指针的大小,一般为
我们可以将一个指针指向不同的内存单元,但是我们不能将一个数组进行赋值。如下代码:
int * a;
int b[ 10 ];
a = b;//正确
b = a;//错误
如果我们要对一个数组进行赋值则我们需要对数组的每一个单元进行赋值,而不能对整个数组惊进行赋值。简单说来,就是数组是一个右值,而非常量的指针则是一个左值。实际上数组的名字可以理解为一个指向一块连续内存的 const 指针。因而我们不能对数组执行 ++ 运算或者 – 运算,但是如果我们将一个指针指向一个数组的首地址则我们可以通过这个指针来遍历这个数组的每一个单元。如果我们想要通过数组名来访问 数组的每一个单元,则我们可以用 [ ] 运算或者是 * (b + 5) 这种方式进行。
这里既然讲到到数组和指针的区别,那么我们可以顺便弄清楚数组指针和指针数组的区别;
指针数组:
指针数组则是指一个存放指针的数组,首先说明,指针数组是一个数组,其存放的元素为指针,因而叫做指针数组。其声明形式如下:
int* a[ 10 ];//存放十个 int* 的指针数组;
数组指针:
数组指针即为执行数组的指针,首先这是一个指针,然后该指针的类型为数组类型。也就是说这样的指针指向一个数组的首地址。
int (*p) [ n ];
int a[m][n];
p = a;
指针 p 是一个指向 int 类型大小为 n的数组指针, 也就是该指针指向 " 一行数据 "。对于上述代码,如果执行 p++ 则指针将会指向二位数组下一行。
12.可变参数模板的作用
可变参数模板参考链接:https://www.cnblogs.com/qicosmos/p/4325949.html
这题问的可变参数模板的作用,但是我们可以先整理一下可变参数有哪些方法:
C 语言可变参数宏
除了 C++ 中的可变参数包,实际上C 语言中也是支持可变参数的,像最常用的 printf( ) 函数,我们传入到函数中的参数的个数就是不定的,甚至类类型也是不定的。所以,在 C 语言中就已经有可变参数的使用了。C 语言中的可变数是通过宏定义实现的。
C 语言中的可变参数需要用到四个宏,其定义在头文件 stdarg.h:
va_list // 用于实现声明一个可变参数列表的变量。
void va_start(va_list ap, last_arg) // 初始化参数列表
type va_arg (va_list ap, type)// 用于读取可变参数,第二个参数为该参数的类型。
void va_end(va_list ap) // 清理工作,实际上是将 ap 置空。
求和范例:
int Sum(int count, ...)
int sum = 0;
va_list ap;
va_start(ap, count);
for (int i = 0; i < count; i++)
sum += va_arg(ap, int);
va_end(ap);
return sum;
上述代码中的参数 … 表示这可变参数列表,其只能放到函数参数的最后一个位置。采用这种宏定义的方式实现可变参数,必须要能指定参数的结束条件,否则将会无法判断可变参数的结束条件,而且给定的参数个数不能少于指定的 count,否则会产生指针越界。
C++可变参数模板
C++提供可变参数模板实现了函数参数不定的问题,可变参数模板同样支持函数参数可变和类模板参数可变。C++中的可变参数模板的声明方式如下:
template <class... T>
上述参数中的 … 表示这是一个可变参数的模板,其放到 class 的后面。
可变参数模板函数
可变参数模板函数的声明方式和普通的模板函数声明方式区别不是很大,只需要声明时加上 … 即可完成。
template <typename T_exp, typename... T>
void fun(T_exp t, T... args)
// function body
注意上述的声明中的 … 在模板参数 T 的后面,其中 args 为参数包的名称,在 C++ 中把可变参数称为参数包。这里我们需要特别小心上代表参数包的符号 … 的使用,当我们在声明的时候,不管是模板参数声明还是函数参数声明,都是将 … 放到类型的后面参数名的前面。但是当我们在调用函数传入参数包的时候则将 … 放到参数名称的后面,表示该参数是一个参数包。但是如果我们在参数包展开的时候希望对每个参数调用某个函数,则我们将 … 放到函数调用的后面。这个有点绕需要认真的辨别。详细请参考《C++ primer》第五版的 618 页。
//假如 args 是参数包,现在调用函数 fun应该这样调用
fun( args... ) // 调用的时候将 ...放入到参数名称 arg后面
//求参数参数包的大小。
sizeof()...(args); //求参数包中参数的数目
//如果希望在参数展开时调用某个函数, 假如为print ,则我们这样调用。
fun( print( args )... )
C++中的可变参数模板函数,语法较为复杂,很容易混淆,以及如何展开参数包等相关内容建议仔细阅读《C++ primer》第五版的 618 页的相关章节或者参考上述链接。
可变参数模板函数的应用
可变参数模板的应用主要是用于针对那些参数不定的函数的实现上。智能指针大家都挺熟悉的,shared_ptr 大家也挺熟悉的,那么说到 shared_ptr 肯定我们也用过make_shared< type >() 这个函数了。make_shared 这个函数适用于分配一个对象到堆上的函数,并返回一个智能指针指向它,在使用的时候我们将我们要分配的对象的类型指定为模板参数,将对象的构造参数作为函数的参数传入其中,那么对于不同的对象,他的构造参数和类型肯定都不一样,所以 make_shared 函数的实现就需要借助于可变参数模板实现。我们可以查看一下 STL 中关于 make_shared 函数的源码。
template <class _Ty, class... _Types>
_NODISCARD
#if _HAS_CXX20
enable_if_t<!is_array_v<_Ty>, shared_ptr<_Ty>>
#else // _HAS_CXX20
shared_ptr<_Ty>
#endif // _HAS_CXX20
make_shared(_Types&&..以上是关于C++面试题合集的主要内容,如果未能解决你的问题,请参考以下文章