智能文档处理文本识别OCR产品体验,多场景横向对比,哪家准确率最高
Posted 白水baishui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了智能文档处理文本识别OCR产品体验,多场景横向对比,哪家准确率最高相关的知识,希望对你有一定的参考价值。
过去,我们在图书馆里找到一篇绝妙的文章,一段重要的参考资料,一本我们想存留的书籍,或者一个无法编辑的电子文档,要么选择手动抄录它,或者键入它并保存到计算机上,但如果一篇文章特别长,那就需要很多时间。随着OCR技术的诞生,我们可以自动识别处理文本,即使是很长文本的识别过程也要不了几秒钟,这极大地方便了信息录入,识别后的文本只需要进行少许文字修改和结构整理即可归档成电子文件。这些生活中的用例无一不说明了智能文档处理和OCR识别给能够为生活带来非常大的便利。
然而,目前没有任何一款产品可以同时实现在多场景、多任务类型、多语言环境下高效稳定的处理。有些产品专注于文档处理和转换;有些产品可以很方便地对屏幕文本截图识别,但却无法处理手写文本;有些产品面面俱到却效果不佳。但今天我体验了一款给我带来惊艳的智能文档处理和OCR识别的产品平台,尽管之前对该平台的认识并不深刻,但它主页上写的为“扫描全能王”、“名片全能王”提供文字识别引擎引起了我充分的兴趣。
TextIn (https://www.textin.com/),是合合信息旗下的一站式OCR服务平台,该平台根据不同的业务场景和需求,将产品分为了通用识别、票据识别、企业证照识别、车辆相关识别、个人证件识别、港澳台证件识别、海外证件识别、文档格式转换和图像处理等,满足各种客户的图像识别和文档处理需求。本次产品体验将评测TextIn中所有服务的重点应用场景。
1. 通用识别
TextIn平台的通用识别涵盖了文字识别、表格识别并转换、印章提取并检测、文档(图文表)识别、二维码识别等场景。我们只需要上传任意带有文字的图像,服务端识别后就会返回文字识别的结果。
1.1. 文字识别
文字识别是任何OCR产品的重中之重,在本次体验中,我分别用了四种姿势测评TextIn的性能。同时,我选用了鹅厂和熊厂的文字识别引擎做对比,看看究竟是哪一款好。
- 普通横排文字识别
测试图片:

TextIn识别的结果:
| 鹅厂 | 熊厂 | TextIn |
|---|---|---|
 |  |  |
TextIn识别到的内容:
像海鸥和浪涛的欢聚一样,我们相遇相近。
海鸥飞走了,浪涛滚滚向前,而我们也该做别离。
Like the meeting of the seagulls and the waves we meet and
The seagulls fly off, the waves roll away and we depart.
在普通横排文字识别的测试中,熊厂和TextIn完整无误地识别出来了每一行,没有错行、漏字、错字的现象。鹅厂的效果最差,有串行现象。
- 手写横排文字识别
测试图片:

TextIn识别的结果:
| 鹅厂 | 熊厂 | TextIn |
|---|---|---|
 |  |  |
TextIn识别到的内容:
再别康桥
徐志摩
轻轻的我走了,正如我轻轻的来,我轻轻的招手,作别西天的云彩。
那河畔的金柳,是夕阳中的新娘,波光里的艳影,在我的心头荡漾。
软泥上的青荇,油油的在水底招摇,在康河的柔波里,我甘心做一条水草。
那榆荫下一潭,不是清泉,是天上虹,揉碎在浮藻间,沉淀着彩虹似的梦。
在手写横排文字识别的测试中,TextIn清晰无误地识别出来了每一行的所有手写字符,没有错行、漏字、错字的现象。鹅厂的效果最差,几乎全部乱码,熊厂识别出来了每一行,但是偶尔有错字。
例如:
鹅厂:H篝心我定了.西加领经经函来
熊厂:解多能我走了.正如我轻轻的来
TextIn: 轻轻的我走了,正如我轻轻的来
- 普通竖排文字识别
测试图片:

TextIn识别的结果:
| 鹅厂 | 熊厂 | TextIn |
|---|---|---|
 |  |  |
TextIn识别到的内容:
例如,较旧的条目应
该会有更完整的内容、
更平衡的观点,而较新
的条目可能经常会包含
明显的错误、非百科全
书的内容,或是单纯的
破坏。
在普通竖排文字识别的测试中,TextIn可以完美识别每一列的字符,没有错行、漏字、错字的现象。鹅厂不能识别竖排文字,熊厂可以识别竖排文字,但是输出却是从左往右,也就是倒序的。而一般情况下竖排文字都是从右往左读,这有些不合理。
例如:
鹅厂:破书明的更该坏的显条平会例。内的目衡有如…
熊厂(按段落从左往右输出):明显的错误非…更平衡的观点…例如,较旧的条目应
TextIn: 例如,较旧的条目应该会有更完整的内容…
- 多角度多国文字识别
测试图片:

TextIn识别的结果:
| 鹅厂 | 熊厂 | TextIn |
|---|---|---|
 |  |  |
TextIn识别到的内容:
ПриветT.
Ahoj.
Kaixo.
Bunǎ.
…(以下省略)
很显然,仅有TextIn可以识别每一种角度的所有语言的字符。鹅厂和熊厂都不能适应这种多角度多国文字的情况。以日语为例,鹅厂和熊厂都没能识别出日文字符,而TextIn可以识别出竖排的日文字符。
1.2. 表格识别并转换
对图片中的表格信息进行识别和转换,我没有用其他产品做对比,因为现有的能做这项工作的产品都是合合信息的,对比没有意义。
- 通用表格识别
TextIn支持识别图片/PDF格式文档中的表格内容,包括有线表格、无线表格、合并单元格表格,同时支持单张图片内的多个表格内容识别,返回各表格的表头表尾内容、单元格文字内容及其行列位置信息。例如有测试图片:
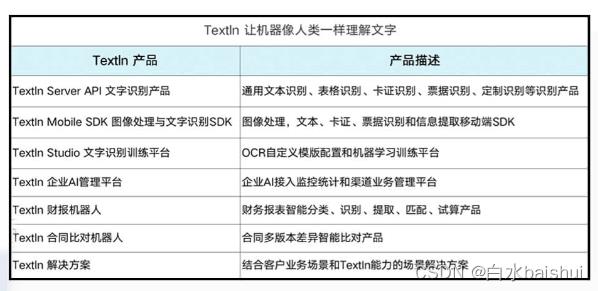
TextIn识别到的内容:
| Textln 产品 | 产品描述 |
|---|---|
| Textin Server API 文字识别产品 | 通用文本识别、表格识别、卡证识别、票据识别、定制识别等识别产品 |
| Textin Mobile SDK 图像处理与文字识别SDK | 图像处理,文本、卡证、票据识别和信息提取移动端SDK |
| Textln Studio 文字识别训练平台 | OCR自定义模版配置和机器学习训练平台 |
| Textin企业AI管理平台 | 企业AI接入监控统计和渠道业务管理平台 |
| Textln 财报机器人 | 财务报表智能分类、识别、提取、匹配、试算产品 |
| Textln 合同比对机器人 | 财务报表智能分类、识别、提取、匹配、试算产品 |
| Textln 解决方案 | 结合客户业务场景和Textin能力的场景解决方案 |
2.简历等复杂表格
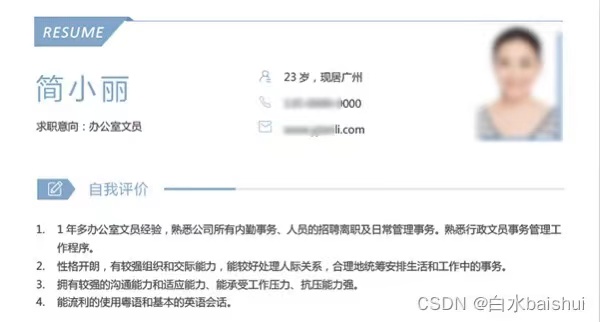
TextIn识别到的内容:
RESUME
简小丽
23岁,现居广州
135-0000-0000
www.yjianli.com
求职意向:办公室文员
自我评价
1.1年多办公室文员经验,熟悉公司所有内勤事务、人员的招聘离职及日常管理事务。熟悉行政文员事务管理工作程序。
2.性格开朗,有较强组织和交际能力,能较好处理人际关系,合理地统筹安排生活和工作中的事务。
3.拥有较强的沟通能力和适应能力、能承受工作压力、抗压能力强。
4.能流利的使用粤语和基本的英语会话。
1.3. 印章提取并检测
测试图片:

TextIn识别到的内容:

从识别结果可以看出,TextIn提供的印章检测功能可以识别并提出图像中的印章,以及辨认印章的所属单位。实际上不仅如此,TextIn还支持检测并识别多行业合同文件和票据中的印章,结构化返回票据等样本上单个/多个印章上文字,支持红章/黑章,常规印章(圆章/方章等),可控制印章切图外扩留白范围。
1.4. 文档(图文表)识别
仅仅对单图做识别是不够的,现在来整点高难度的活儿,我们对带有图文表的文档进行识别,看看效果怎么样。在这里,我们选用某知名国产办公软件的图片转文字工具作为对比。
测试图片:

TextIn识别的结果:
| 知名国产办公软件 | TextIn |
|---|---|
 |  |
在图片转文字\\文档这个功能上,TextIn识别的的结果和*山国产办公软件几乎在同一水平线上,可以说不相上下。
1.5. 二维码识别
另外,TextIn还提供了二维码识别的功能,不过博客上发二维码会被吞图,这里直接给出TextIn的测试范例的识别结果,给大家做参考:
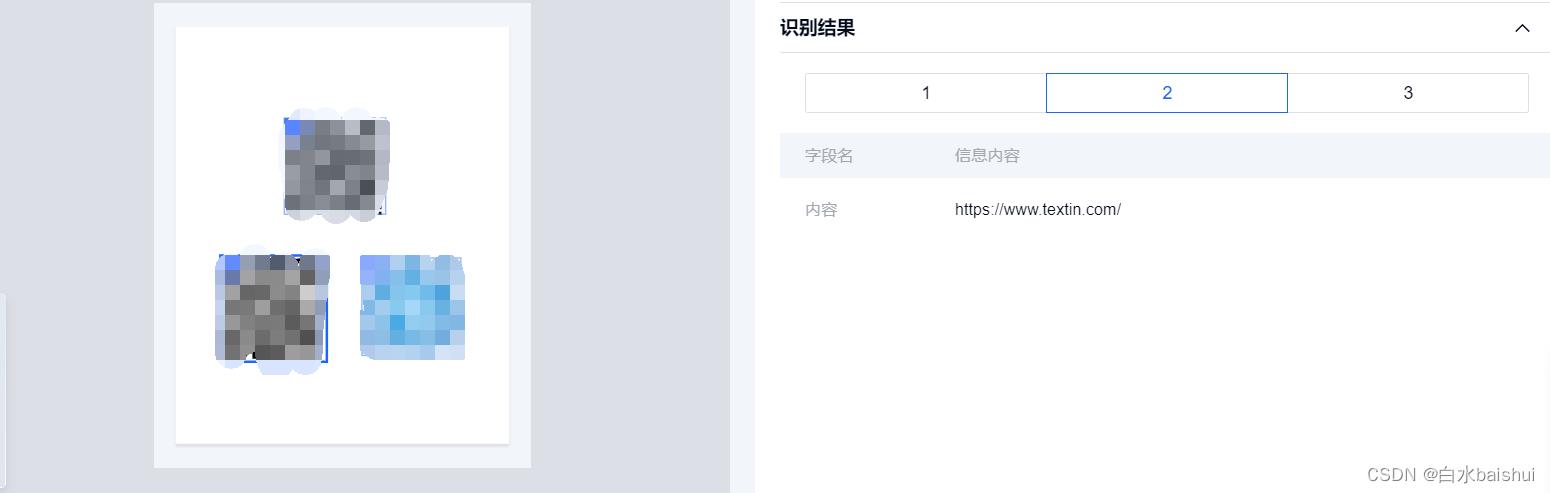
TextIn对于在同一画面内的多个二维码可以做到分别识别,如“识别结果”中的1、2、3所示,我们只需要在返回的识别结果中选择我们需要的对应二维码的识别内容即可。
2. 证照文本识别
2.1. 个人证件
- 身份证
和二维码一样,发身份证也会被吞图,所以我们直接给出TextIn的demo上对身份证的识别结果,:

TextIn可以对身份证正反面的全部字段进行结构化识别,包括姓名、性别、民族、出生日期、地址、身份证号、有效期限、签发机关,同时可返回头像切片位置信息,进行头像检测。然后返回结构化的识别结果,在某些情况,例如识别的后续任务是自动填写表单的时候,可以直接将识别结果赋值到表单中。
- 驾驶证
和身份证的识别一样,TextIn支持对驾驶证正副页全部字段进行结构化识别,包括姓名、类型、驾驶证证号、性别、国籍、住址、出生日期、初次领证日期、准驾车型、有限期限始(至)、总计有效期限。例如我们对下面的测试图片进行识别:

TextIn识别到的内容:
| 字段名 | 信息内容 |
|---|---|
| 住址 | 河北省邯郸市肥乡县肥乡镇 |
| 出生日期 | 1988-12-12 |
| 准驾车型 | C1 |
| 国籍 | 中国 |
| 记录 | |
| 档案编号 | |
| 初次领证日期 | 2017-05-12 |
| 发证机关 | 北京市公安局公安交通管理局 |
| 姓名 | 王飞飞 |
| 性别 | 男 |
| 类型 | 中华人民共和国机动车驾驶证 |
| 有限期始(至) | 2017-05-12至2023-05-12 |
- 银行卡
在使用各大银行的小程序和APP时,总是会要求填写银行卡号,我想想不少人都和我一样希望能够直接对银行卡进行拍照识别,所以我测试了TextIn对银行卡的识别能力:
测试图片:

返回的识别结果:
| 字段名 | 信息内容 |
|---|---|
| 卡类型 | 贷记卡 |
| 卡号 | 6225 7888 8888 8888 |
| 有效期 | 88/88 |
| 持有人 | XIANG RI KUI |
| 发卡机构代号 | 03080000 |
| 卡号校验 | False |
可以看到,TextIn支持对银行卡中的6个关键字段的进行结构化识别,包括类型、发卡机构、发卡机构代号、有效期、卡号、持有人。更让我感到惊讶的是,在识别文本信息的同时TextIn还可以返回图像切边图像和定位点的位置信息,虽然这只是一个基础功能,但对于习惯保存卡片信息的人来说确实是很有帮助了,同样的功能还可以用在个人名片的拍照保存上。

- 护照
TextIn还支持对中国大陆护照个人资料页所有字段进行结构化识别,包括护照号码、姓名拼音、姓名、性别、出生日期、有效期、签发日期等14个字段。同样的,TextIn提供护照的切边头像及资料页切边图像。对于经常离境的朋友们来说,这个功能应该是比较实用的。
测试图片:

TextIn识别的的内容:
| 护照号码 | G43243244 |
|---|---|
| 姓 | 陈/CHEN |
| 名 | 小小/XIAOXIAO |
| 性别 | M |
| 出生地点 | 湖北/HUBEI |
| 签发地点 | 湖北/HUBEI |
| 出生日期 | 10–2001 |
| 有效期 | 2020-10-10 |
| 护照下方第一行 | PPPHHHHEN<<JIIIIII<<<<<<<<<<<<<<<<<<<<<<<<< |
| 护照下方第二行 | G494364200CHN0100101M201010101010101<<<<<<38 |
| 签发机关 | 公安部出入境管理局 |
| 国家码 | CHN |
2.2. 车牌号
老生常谈的OCR任务,车牌号识别,这几乎是判断一款OCR模型是否成熟的标杆。TextIn的文档指明了它支持单个或批量上传的多种类型车牌自动识别,包括蓝牌、黄牌、绿牌、警牌、使馆车牌等。于是我尝试一次性输入五张车牌号的图像,也就是输入了五组测试数据:
| 车牌图像 | 字段名 | 信息内容 |
|---|---|---|
 | 普通蓝牌 | 晋L90388 |
 | 新能源车----绿色 | 京AD66266 |
 | 普通蓝牌 | 浙AB0002 |
 | 白色*牌 | 京A7726* |
 | 普通单层黄牌 | 渝BR9703 |
我原以为TextIn只能识别车牌号,没想到还能根据车票颜色判断车牌类型。
2.3. 海外证照
多文字识别是TextIn的特色之一,从我个人的体验结果来说是很惊讶的。因为对于某些常用国家(例如:印度尼西亚、马来西亚、日本、菲律宾)的证件,TextIn不仅做到了文本的识别,还针对性的返回了结构化的信息。
例如这张日本驾驶证:

TextIn针对日本的驾驶证信息定义了一套结构化模板,识别的内容都套入模板后返回:
| 字段名 | 信息内容 |
|---|---|
| 姓名 | 緒小 小百百 |
| 住所 | 熊本県熊本市西区野中2丁目2-2古城ハイツ |
| 生日 | 平成22年08月29日 |
| 交付日期 | 平成22年08月29日 |
| 有效期 | 平成36年06月19日 |
| 个人番号 | 933387873333 |
3. 票据识别
会计和财务人员非常需要票据识别的功能,但总是担心识别准确率的问题,因为错误的内容要比空白的内容更难处理。那么我们来试试TextIn对票据的识别效果:
| 票据类型 | 票据图片 | 识别结果 |
|---|---|---|
| 增值税发票 |  |  |
| 国内通用票据混检(行程单、通用定额发票、火车票) |  | 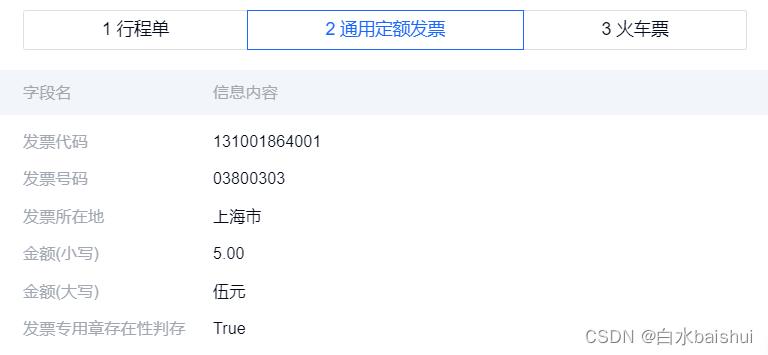 |
| 车辆通行费票据 |  | 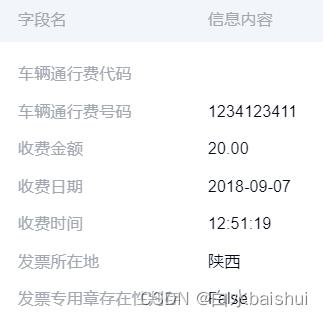 |
从测试结果中可以看到,TextIn具有很高的识别准确率,几乎无误,而且可以同时识别多张票据。但同时,为了方便财务工作者筛查可能存在的错误,TextIn针对每种票据都定义了结构模板,依赖模板的文本提取可以保证及时发现并轻松地修改潜在的错误识别内容。
总的来说,TextIn支持对多种票据类型(多票据)进行票据切分、票据分类、票据识别,同时支持在混贴报销场景下对多种票据检测以及关键信息提取,并返回结构化的文本信息。当前支持27种票据类型。
4. 图像处理和PS检测
4.1. 切边矫正和切边增强
切边矫正和增强可以让文本内容聚焦,带来更好的展示(美观度)。更重要的是为下游任务(OCR识别,信息抽取等)带来准确率的提升。个人认为TextIn的切边增强功能十分强大,相较于其他类似产品如s**pro,虽然s*pro也可以进行切边矫正,但是会出现损毁变形,甚至因为角度而出现吞字漏字的情况。话不多说,直接上图:
| 待切边图像 | 切边矫正和增强后的图像 |
|---|---|
 |  |
 |  |
 |  |
从个人体验来说,TextIn的切边增强和弯曲矫正技术是独一无二的。参考论文 DocUNet(CVPR2018) 和 DewarpNet(ICCV2019) ,TextIn所用的文档矫正系统应用了一种基于偏移场学习的方法SOTA算法。
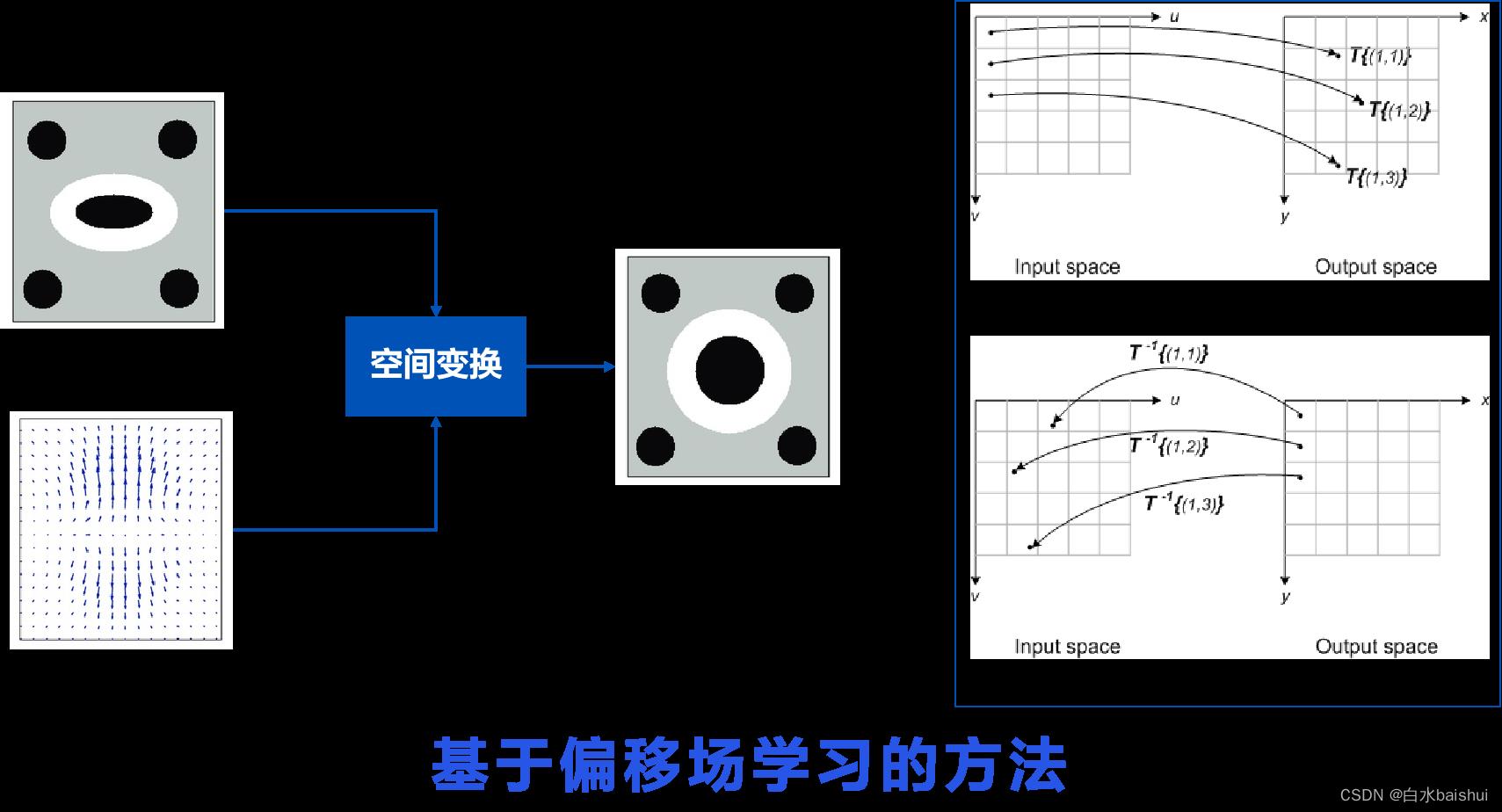

4.2. 去除屏幕摩尔纹
所谓摩尔纹,它主要是由于光的干涉引发的一种波纹现象。常见于对电脑屏幕的翻拍图像,去除屏幕纹是TextIn的特色技术之一,消除屏幕摩尔纹对提高图像、文字清晰度有巨大的促进作用的。使用TextIn去除屏幕摩尔纹的效果如下:
| 测试图像 去除摩尔纹前 | 测试图像 去除摩尔纹后 |
|---|---|
 |  |
效果很好,我好奇地看了一下TextIn的摩尔纹去除系统算法,找到一张框架图:
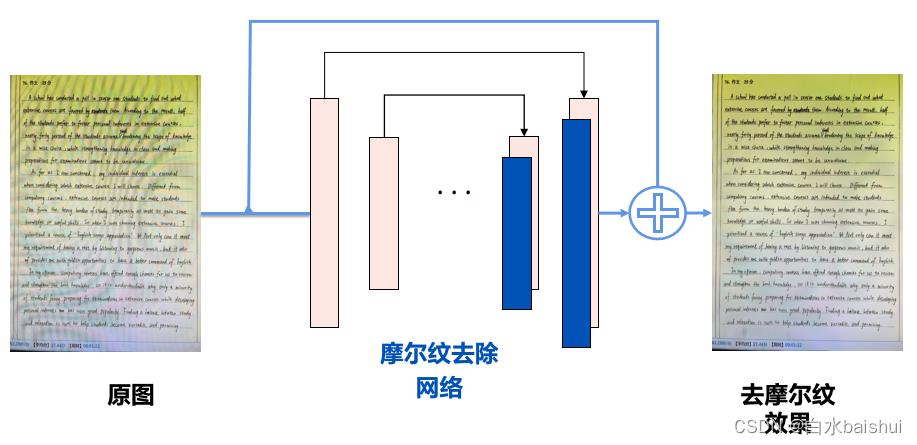
虽然没有公布具体的实现细节,不过看起来像是构造了一种特殊的滤波器网络实现了摩尔纹的过滤,从大批量样本的测试结果来看,这个算法具有很好的泛化性,点赞。
4.3. PS痕迹检测
TextIn的PS痕迹检测是一个让我感到很惊艳的点,要知道通常检测图像是否被篡改只能通过Exif信息来检查,但如果图片只是经过PS,GMIP等图像编辑软件的格式改动,但未篡改具体内容的情况下容易误判,另外如果图片被篡改后,用第三方软件或工具抹除Exif信息,也会造成误判。
TextIn通过自己提出的 CNN Tamper Detector 来检测RGB域和噪声域存在痕迹的篡改,例如擦除、擦除重打印文本、重打印文本、复制-移动、拼接等痕迹,同时融合SRM、BayarConv、ELA等方法提升CNN Tamper Detector性能,获得了很好的检测可靠性。另外,他们提出了 DCT Transformer Detector 用于检测频域存在痕迹的篡改,例如复制-移动、拼接等痕迹。
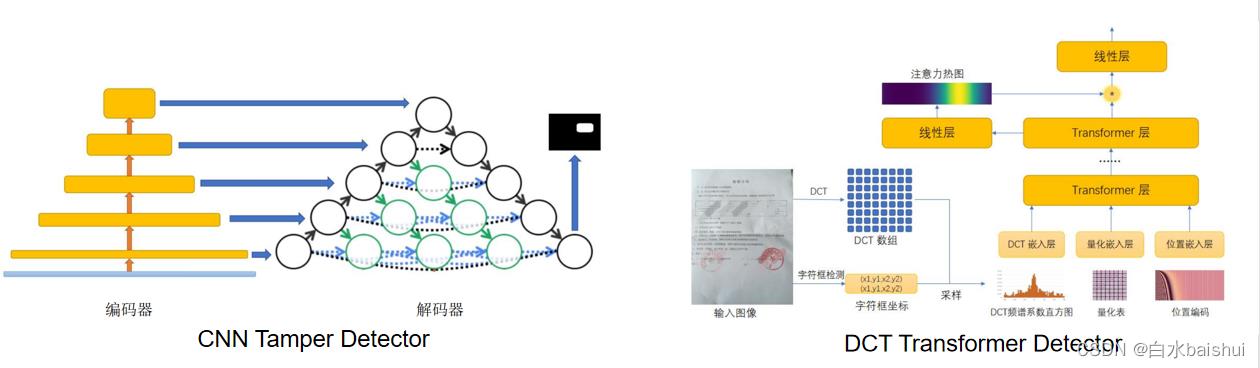
关于CNN Tamper Detector和DCT Transformer Detector的文献,可以在 CAT-Net(WACV2021) 和 Mantra-net(CVPR2019) 下载到。
那么效果究竟如何呢,我们来试试看效果:
| 被篡改图像 | 检测结果图像 | 检测结果 |
|---|---|---|
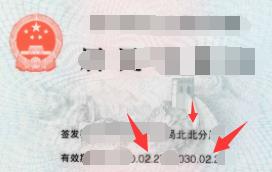 | 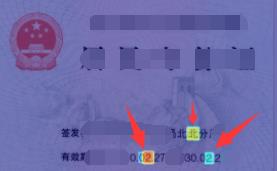 | 有篡改 |
 |  | 有篡改 |
 |  | 有篡改 |
从测试结果来看,虽然TextIn标记的篡改位置不够准确,但都可以检测出有篡改痕迹。据我调查,目前并没有任何一款产品能够在图像篡改检测超越TextIn,希望之后TextIn能继续改进,争取早日做出更加完美的篡改检测系统。
5. 文档格式转换
TextIn提供了多种文档格式转换的工具,其中如Word转PDF、Excel转PDF等都是很成熟的功能,无需赘述。但现如今还没有任何一家的产品那个完美地实现 PDF转Word 和 PDF转Excel。在这里,我们将TextIn与某国产办公软件和口碑较好的PDF转换工具cle**pdf做个对比。
5.1. PDF 转Word
TextIn为用户提供了高并发高可靠的API,将PDF文档转换为Word。转换出的文件尽可能保持PDF原有格式,强化易读性。
以如下待转换PDF为例:

PDF转换为Word的结果:
| 国产办公软件 | cle**pdf | TextIn |
|---|---|---|
 | 失败 (只有一张不可编辑的图片) |  |
5.2. PDF 转Excel
TextIn为用户提供了高并发高可靠的API,将PDF文档转换为Excel。转换出的文件尽可能保持PDF原有格式,强化易读性。
以如下待转换PDF为例:
PDF转换为Excel的结果:
| 国产办公软件 | cle**pdf | TextIn |
|---|---|---|
 | 失败(空表) |  |
可以看到,在PDF转换为Word的能力上,TextIn与某知名国产办公软件的转换能力在同一水平,但在PDF转换为Excel的能力上,TextIn在转换后含有更少的乱码。
一个有意思的发现是,如果TextIn转换表格失败,那可以转用PDF转换为Word的功能,这时你会发现,TextIn能在Word中生成一张相当完整的表,之后我们再将该表从Word中复制到Excel中,就可以得到转换后的Excel表格了。
6. API和文档支持
那么TextIn到底如何使用呢?TextIn为广大的开发者提供了丰富的文档支持,例如当我们调用通用文本识别的API时,只需要一段简单的代码就可以实现,以php为例:
<?php
/**
* Post请求
*
* @param string $url 地址
* @param array $headers Http Header
* @param string $body 内容
* @return string
*/
function post($url, $headers, $body)
$ch = curl_init();
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_HEADER, false);
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $body);
$response = curl_exec($ch);
curl_close($ch);
return $response;
// 请登录后前往 “工作台-账号设置-开发者信息” 查看 x-ti-app-id
// 示例代码中 x-ti-app-id 非真实数据
const APP_ID = 'c81f*************************e9ff';
// 请登录后前往 “工作台-账号设置-开发者信息” 查看 x-ti-secret-code
// 示例代码中 x-ti-secret-code 非真实数据
const SECRET_CODE = '5508***********************1c17';
// 通用文字识别
const URL = 'https://api.textin.com/ai/service/v2/recognize';
$headers = [
'x-ti-app-id:' . APP_KEY,
'x-ti-secret-code:' . APP_SECRET
];
$fileData = file_get_contents('example.png'); // 读取文件
$response = post(URL, $headers, $fileData);
$ocrResult = json_decode($response, true);
// 获取 身份证号 和 姓名
$result = $ocrResult['result'] ? $ocrResult['result'] : '';
if ($result)
$list = $result['item_list'];
if ($list && count($list))
var_dump($list);
图片上传后返回的内容记录在一个json包内,包括识别时间、图像角度和宽高、文本内容和类型,识别置信度等内容。我按照文档给出的示例代码对TextIn的77个API进行了逐一进行尝试,所有API都正常接收请求并返回处理结果。
| TextIn支持的77个API | ||||||
| 组织机构代码证识别 | 自动除手写文字 | 证件分类 | 增值税发票识别 | 营业执照识别 | 印章检测识别 | 印尼身份证识别 |
| 银行卡识别 | 银行回执单识别 | 医疗证件票据分类 | 行驶证识别 | 香港身份证识别 | 文档图像切边矫正 | 卫生许可证识别 |
| 完税证明识别 | 图像水印去除 | 图片切边增强 | 通用文字识别 | 通用机打发票识别 | 通用表格识别 | 通用NLP信息抽取 |
| 台湾身份证识别 | 台湾居民来往大陆通行证识别 | 台湾健保卡识别 | 税务登记证识别 | 事业单位法人证识别 | 身份证识别 | 社保卡识别 |
| 商铺小票识别 | 日本驾驶证识别 | 去屏幕纹 | 票据分类 | 名片识别 | 马来西亚身份证识别 | 开户许可证识别 |
| 军官证识别 | 卷式发票识别 | 结婚证识别 | 驾驶证识别 | 机动车购车发票识别 | 火车票识别 | 护照识别 |
| 户口本识别 | 海关进出口货物报关单识别 | 国内通用票据识别 | 公路客运发票识别 | 港澳台通行证识别 | 港澳台居民居住证 | 港澳居民来往内地通行证识别 |
| 菲律宾身份证识别 | 飞机行程单识别 | 房产证识别 | 发票验真 | 二维码识别 | 二手车购车发票识别 | 定额发票识别 |
| 电子承兑汇票识别 | 出租车发票识别 | 出生证明识别 | 车牌号识别 | 车辆通行费票据识别 | 车辆合格证识别 | 车辆登记证识别 |
| 车辆VIN码识别 | 不动产权证书识别 | 办公文档识别 | 澳门身份证识别 | PS检测 | Word转图片 | 图片转Word |
| PDF转Word | PDF转Excel | PDF转PPT | PDF转图片 | Word转PDF | Excel转PDF | 图片转PDF |
上海合合信息科技股份有限公司是行业领先的人工智能及大数据科技企业,致力于通过智能文字识别及商业大数据领域的核心技术、C端和B端产品以及行业解决方案为全球企业和个人用户提供创新的数字化、智能化服务。16年来深耕智能文字识别+商业大数据领域,在C端推出了多款深受全球用户喜爱的效率产品,例如:名片全能王、扫描全能王、启信宝等。在B端积极服务于AI+大数据赋能数字化转型,服务了超过30+个行业和2000+全球企业。


以上是关于智能文档处理文本识别OCR产品体验,多场景横向对比,哪家准确率最高的主要内容,如果未能解决你的问题,请参考以下文章