《大数据开发》MapReduce强化
Posted Steve_Abelieve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《大数据开发》MapReduce强化相关的知识,希望对你有一定的参考价值。
1.wordCount
任务:统计acticle.txt,每个单词出现个数。
word_count_demo

2.数据去重
任务:对ip数据进行去重。
192.168.70.49
192.168.70.78
192.168.70.49
192.168.70.49
192.168.70.23
192.168.70.49
192.168.70.49
192.168.70.49
192.168.70.25
192.168.70.49
192.168.70.49
192.168.70.26
192.168.70.49
…
192.168.70.27
3.分组求平均值
任务:每个班的历史成绩求平均值
class01 69
class01 84
class01 68
class02 89
class02 90
class02 81
class02 75
class03 83
class03 90
....
class03 78
4.求最大最小值
假设我们需要处理一批有关天气的数据,其格式如下:
按照ASCII码存储,每行一条记录。每行共24个字符(包含符号在内)
第9、10、11、12字符为年份,第20、21、22、23字符代表温度,求每年的最高温度
2329999919500515070000
9909999919500515120022
9909999919500515180011
9509999919490324120111
6509999919490324180078
9909999919370515070001
9909999919370515120002
9909999919450515180001
6509999919450324120002
8509999919450324180078
5.序列化机制
集群工作过程中,需要用到RPC通信,所以MR处理的对象必须可以进行序列化/反序列操作。Hadoop利用的是avro实现的序列化和反序列,并且在其基础上提供了便捷的API要序列化的对象必要实现相关的接口:(需要补充什么是序列化和反序列化)

案例:购物金额统计
phone address name consum
13877779999 bj zs 2145
13766668888 sh ls 1028
13766668888 sh ls 9987
13877779999 bj zs 5678
13544445555 sz ww 10577
13877779999 sh zs 2145
13766668888 sh ls 9987
6.分区
按地区分为三个分区:
phone address name consum
13877779999 bj zs 2145
13766668888 sh ls 1028
13766668888 sh ls 9987
13877779999 bj zs 5678
13544445555 sz ww 10577
13877779999 sh zs 2145
13766668888 sh ls 9987
7.combiner
合并的目的是减少Reduce端迭代的次数combiner是实现Mapper端进行key的归并,combiner具有类似本地的reduce功能。如果不用combiner,那么所有的结果都是reduce完成,效率会很低。使用combiner先做合 并,然后发往reduce。

任务:对wordCount 进行combiner操作
8.排序和全排序
基于电影评分,对电影进行排序。
需求说明
利用3个reduce来处理,并且生成的三个结果文件,是整体有序的。生成的三个结果文件:不同位数一个文件。

源数据:
93 239 231
23 22 213
613 232 614
213 3939 232
4546 565 613
231 231
2339 231
1613 5656 657
61313 4324 213
613 2 232 32
9.多文件合并
任务: 计算每个人三个月,每一课的总成绩。
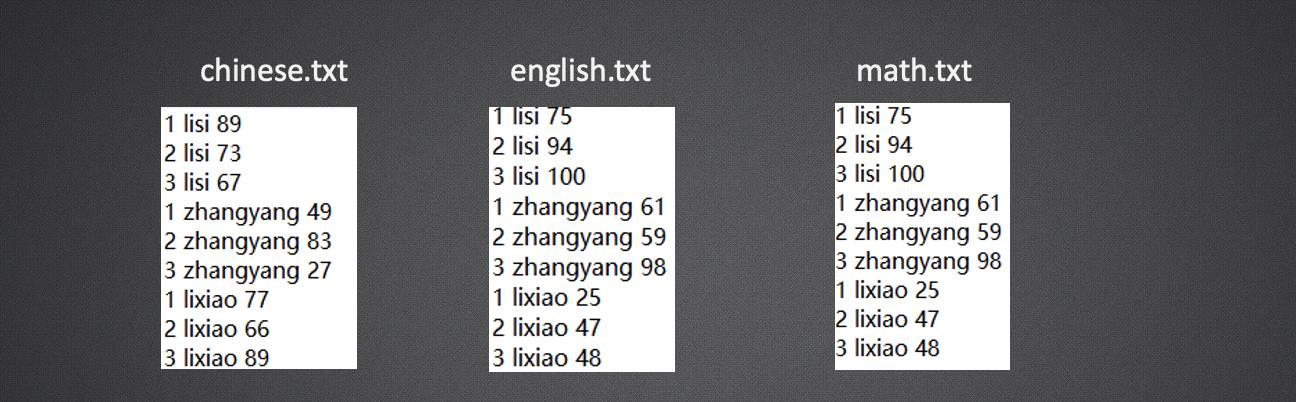
lisi Student [ name=li, chinese=232, english=253, math=188]
lixiao Student [ name=wang, chinese=159, english=194, math=237]
zhangyang Student [ name=zhang, chinese=229, english=199, math=239]
10.多级MR
案例:计算企业一个季度的利润并按照利润进行排序,总收入-总支出。第二列-第三列。
(用一个company类来封装)

11.相似好友查询

12.MR实现kmenas
13.MR实现基于用户的协同过滤(提升篇)
14. 小练习
user_log.csv
id:代表数据集的第几条数据,从1到11376681。
target:代表该视频是否被用户点击了,1代表点击,0代表未点击。
timestamp:代表改用户点击改视频的时间戳,如果未点击则为NULL。
deviceid:用户的设备id。
newsid:视频的id。
guid:用户的注册id。
pos:视频推荐位置。
app_version:app版本。
device_vendor:设备厂商。
netmodel:网络类型。
osversion:操作系统版本。
lng:经度。
lat:维度。
device_version:设备版本。
ts:视频暴光给用户的时间戳。
1.统计每个用户点击物品的次数,以及每个用户的点击率(点击/曝光)
2.找出用户最近观看的10个视频id。
3.请统计每个用户曝光的视频数量
4.找出每个用户最常用(观看视频最多)的设备。
5.基于用户的经度、维度,对用进行区域聚类。
以上是关于《大数据开发》MapReduce强化的主要内容,如果未能解决你的问题,请参考以下文章