java字节流对汉字输出为乱码的问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java字节流对汉字输出为乱码的问题相关的知识,希望对你有一定的参考价值。
package IoOut;
import java.io.*;
public class App14_1
public static void main(String args[]) throws IOException //read()方法抛出IOException异常,在此交给JVM处理
FileInputStream fr =new FileInputStream("c:\\aaa.txt"); //ok,但不能正 确读取出汉字
int ch;
int count=0;
ch=fr.read(); //read()方法返回的是一个整型数字
while(ch!=-1)
System.out.print((char)ch);
ch=fr.read();
count++;
fr.close();
System.out.println("\n共读取了:"+count+"个字符");
在aaa.txt中有汉字,但输出为乱码,字符输出正常,为什么?
BufferedReader bre = null;
try
String file = "D:/test/test.txt";
bre = new BufferedReader(new FileReader(file));//此时获取到的bre就是整个文件的缓存流
while ((str = bre.readLine())!= null) // 判断最后一行不存在,为空结束循环
System.out.println(str);//原样输出读到的内容
;
备注: 流用完之后必须close掉,如上面的就应该是:bre.close(),否则bre流会一直存在,直到程序运行结束。 参考技术A 首先确认你的字符编码,gbk编码中文是2个字节,utf编码是3个字节代表一个字符
read读到的是一个节,一个中文,当然就读半个字节了,不完全当然是乱码了本回答被提问者采纳 参考技术B txt 的字符是gb2312的 控制台 喷出的字符一般要经过转码 转成utf-8 就行了吧 参考技术C 先请看我修改后的源代码:
package IoOut;
import java.io.*;
public class App14_1
public static void main(String args[]) throws IOException //read()方法抛出IOException异常,在此交给JVM处理
FileInputStream fr =new FileInputStream("c:\\aaa.txt"); //ok,但不能正 确读取出汉字
int ch;
int count=0;
ch=fr.read(); //read()方法返回的是一个整型数字
while(ch!=-1)
System.out.write(ch);
ch=fr.read();
count++;
fr.close();
System.out.println("\n共读取了:"+count+"个字符");
其实只改了一处地方,
System.out.print((char)ch);
改为
System.out.write(ch);
前者是按字符格式写,后者是按字节格式写。汉字、图片、音频等应该按字节处理,否则会出现所谓的乱码。
实际上没有所谓的乱码,只是不同Unicode编码组合表示的字符而已。 参考技术D 热一天我也吧
Javaweb 响应字节流输出中文乱码问题
文章目录
问题:使用字节流输出,产生了中文乱码?
举个栗子
如下面的形式就会输出中文乱码
public class ResponseDemo1 extends HttpServlet {
/**
* 演示字节流输出的乱码问题
*/
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String str = "字节流输出中文的乱码问题";//UTF-8的字符集,此时浏览器显示也需要使用UTF-8的字符集。
//1.拿到字节流输出对象
ServletOutputStream sos = response.getOutputStream();
//2.把str转换成字节数组之后输出到浏览器
sos.write(str.getBytes("UTF-8"));
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
原因:存和取用的不是同一个码表
- 在保存时用的是IDEA创建文件使用的字符集
UTF-8。 - 到浏览器上显示,chrome浏览器和ie浏览器默认的字符集是
GB2312(其实就是GBK),存和取用的不是同一个码表,就会产生乱码。
解决办法:把存和取的码表统一
第一种解决办法:
修改浏览器的编码,使用右键——编码——改成UTF-8。(不推荐使用,我们的应用尽量不要求用户取做什么事情)
ie和火狐浏览器可以直接右键设置字符集。而chrome需要安装插件,很麻烦。
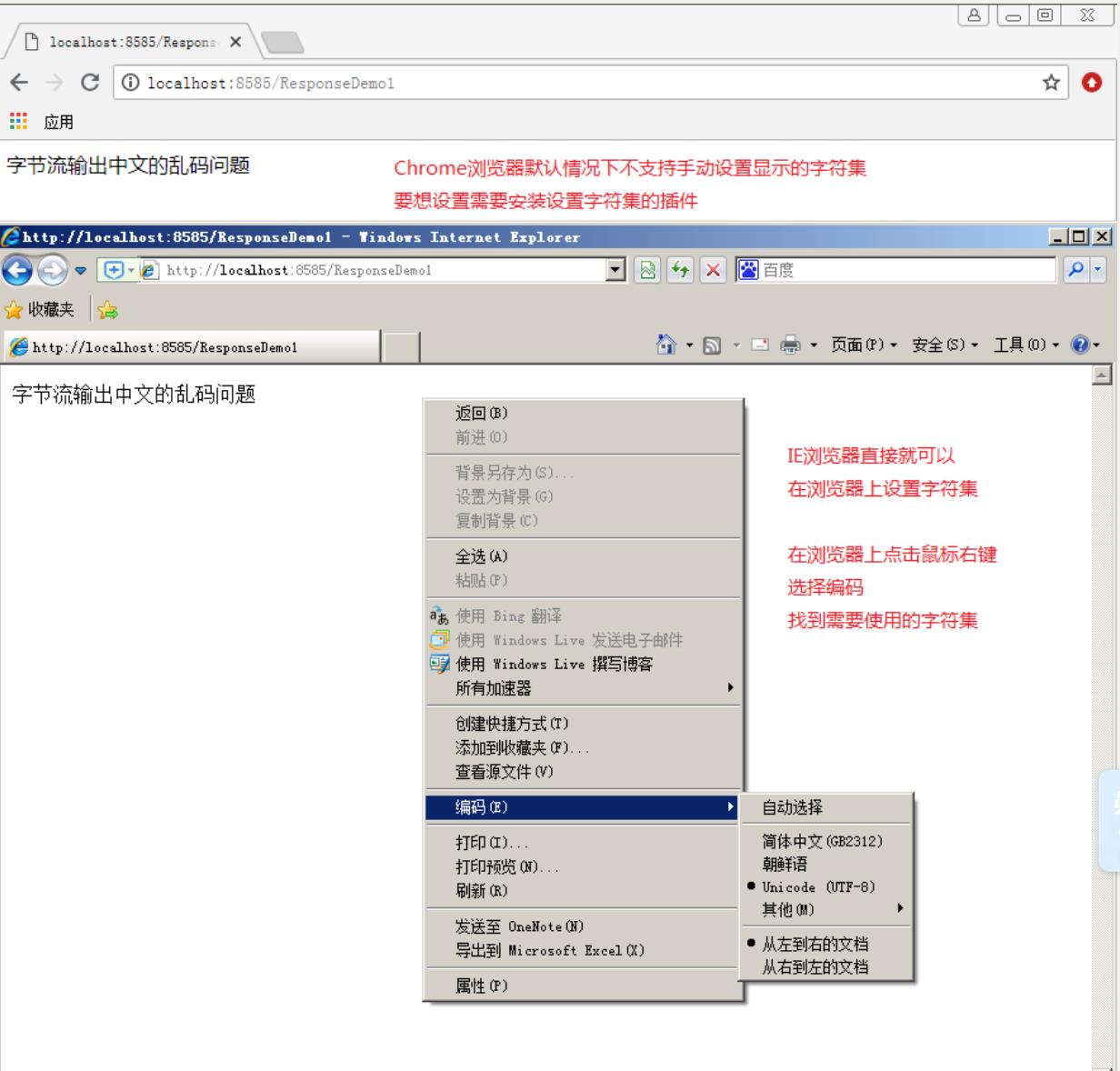
第二种解决办法: (不建议使用,因为不好记)
向页面上输出一个meta标签,内容如下:
<meta http-equiv="content-type" content="text/html;charset=UTF-8">
其实它就是指挥了浏览器,使用哪个编码进行显示。
在java中是这样写的:
//1.拿到字节流输出对象
ServletOutputStream sos = response.getOutputStream();
sos.write("<meta http-equiv='content-type' content='text/html;charset=UTF-8'>".getBytes());
第三种解决办法:
设置响应消息头,告知浏览器响应正文的MIME类型和字符集
response.setHeader("Content-Type","text/html;charset=UTF-8");
在Java中是这样实现的:
//1.拿到字节流输出对象
ServletOutputStream sos = response.getOutputStream();
response.setHeader("Content-Type","text/html;charset=UTF-8");
第四种解决办法:我们推荐使用的办法
它的本质就是设置了一个响应消息头
response.setContentType("text/html;charset=UTF-8");
在java中是这样实现的
//1.拿到字节流输出对象
ServletOutputStream sos = response.getOutputStream();
response.setContentType("text/html;charset=UTF-8");
//2.把str转换成字节数组之后输出到浏览器
sos.write(str.getBytes("UTF-8"));
案例
上述四种解决办法的案例:
public class ResponseDemo1 extends HttpServlet {
/**
* 演示字节流输出的乱码问题
*/
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
/**
* 问题:
* String str = "字节流中文乱码问题";
* 使用字节流输出,会不会产生中文乱码?
* 答案:
* 会产生乱码
* 原因:
* String str = "字节流中文乱码问题"; 在保存时用的是IDEA创建文件使用的字符集UTF-8。
* 到浏览器上显示,chrome浏览器和ie浏览器默认的字符集是GB2312(其实就是GBK),存和取用的不是同一个码表,就会产生乱码。
*
* 引申:
* 如果产生了乱码,就是存和取用的不是同一个码表
* 解决办法:
* 把存和取的码表统一。
*/
String str = "字节流输出中文的乱码问题";//UTF-8的字符集,此时浏览器显示也需要使用UTF-8的字符集。
//1.拿到字节流输出对象
ServletOutputStream sos = response.getOutputStream();
/**
* 解决办法:
* 第一种解决办法:
* 修改浏览器的编码,使用右键——编码——改成UTF-8。(不推荐使用,我们的应用尽量不要求用户取做什么事情)
* ie和火狐浏览器可以直接右键设置字符集。而chrome需要安装插件,很麻烦。
* 第二种解决办法: (不建议使用,因为不好记)
* 向页面上输出一个meta标签,内容如下: <meta http-equiv="content-type" content="text/html;charset=UTF-8">
* 其实它就是指挥了浏览器,使用哪个编码进行显示。
* 第三种解决办法:
* 设置响应消息头,告知浏览器响应正文的MIME类型和字符集
* response.setHeader("Content-Type","text/html;charset=UTF-8");
* 第四种解决办法:我们推荐使用的办法
* 它的本质就是设置了一个响应消息头
* response.setContentType("text/html;charset=UTF-8");
*/
//第二种解决办法:sos.write("<meta http-equiv='content-type' content='text/html;charset=UTF-8'>".getBytes());
//第三种解决办法:response.setHeader("Content-Type","text/html;charset=UTF-8");
//第四种解决办法:
response.setContentType("text/html;charset=UTF-8");
//2.把str转换成字节数组之后输出到浏览器
sos.write(str.getBytes("UTF-8"));
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
问题解决后案例:正常输出中文
public class ResponseDemo2 extends HttpServlet {
/**
* 字符流输出中文乱码
* @param request
* @param response
* @throws ServletException
* @throws IOException
*/
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String str = "字符流输出中文乱码";
//response.setCharacterEncoding("UTF-8");
//设置响应正文的MIME类型和字符集
response.setContentType("text/html;charset=UTF-8");
//1.获取字符输出流
PrintWriter out = response.getWriter();
//2.使用字符流输出中文
/**
* 问题:
* out.write(str); 直接输出,会不会产生乱码
* 答案:
* 会产生乱码
* 原因:
* 存用的什么码表:UTF-8
* 在浏览器取之前,字符流PrintWriter已经获取过一次了,PrintWriter它在取的时候出现了乱码。
* 浏览器取默认用的是GBK。(本地系统字符集)
*
* UTF-8(存)————>PrintWriter ISO-8859-1(取) 乱
* PrintWirter ISO-8859-1(存)————>浏览器 GBK(取) 乱
*
* 解决办法:
* 改变PrintWriter的字符集,PrintWriter是从response对象中获取的,其实设置response的字符集。
* 注意:设置response的字符集,需要在拿流之前。
* response.setCharacterEncoding("UTF-8");
*
* response.setContentType("text/html;charset=UTF-8");
* 此方法,其实是做了两件事:
* 1.设置响应对象的字符集(包括响应对象取出的字符输出流)
* 2.告知浏览器响应正文的MIME类型和字符集
*/
out.write(str);
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
以上是关于java字节流对汉字输出为乱码的问题的主要内容,如果未能解决你的问题,请参考以下文章