121 11 个案例掌握 Python 数据可视化--星际探索
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了121 11 个案例掌握 Python 数据可视化--星际探索相关的知识,希望对你有一定的参考价值。
参考技术A 星空是无数人梦寐以求想了解的一个领域,远古的人们通过肉眼观察星空,并制定了太阴历,指导农业发展。随着现代科技发展,有了更先进的设备进行星空的探索。本实验获取了美国国家航空航天局(NASA)官网发布的地外行星数据,研究及可视化了地外行星各参数、寻找到了一颗类地行星并研究了天体参数的相关关系。
输入并执行魔法命令 %matplotlib inline, 设置全局字号,去除图例边框,去除右侧和顶部坐标轴。
本数据集来自 NASA,行星发现是 NASA 的重要工作之一,本数据集搜集了 NASA 官网发布的 4296 颗行星的数据,本数据集字段包括:
导入数据并查看前 5 行。
截至 2020 年 10 月 22 日 全球共发现 4296 颗行星,按年聚合并绘制年度行星发现数,并在左上角绘制 NASA 的官方 LOGO 。
从运行结果可以看出,2005 年以前全球行星发现数是非常少的,经计算总计 173 颗,2014 和 2016 是行星发现成果最多的年份,2016 年度发现行星 1505 颗。
对不同机构/项目/计划进行聚合并降序排列,绘制发现行星数目的前 20 。
2009 年至 2013 年,开普勒太空望远镜成为有史以来最成功的系外行星发现者。在一片天空中至少找到了 1030 颗系外行星以及超过 4600 颗疑似行星。当机械故障剥夺了该探测器对于恒星的精确定位功能后,地球上的工程师们于 2014 年对其进行了彻底改造,并以 K2 计划命名,后者将在更短的时间内搜寻宇宙的另一片区域。
对发现行星的方式进行聚合并降序排列,绘制各种方法发现行星的比例,由于排名靠后的几种方式发现行星数较少,因此不显示其标签。
行星在宇宙中并不会发光,因此无法直接观察,行星发现的方式多为间接方式。从输出结果可以看出,发现行星主要有以下 3 种方式,其原理如下:
针对不同的行星质量,绘制比其质量大(或者小)的行星比例,由于行星质量量纲分布跨度较大,因此采用对数坐标。
从输出结果可以看出,在已发现的行星中,96.25% 行星的质量大于地球。(图中横坐标小于 e 的红色面积非常小)
通过 sns.distplot 接口绘制全部行星的质量分布图。
从输出结果可以看出,所有行星质量分布呈双峰分布,第一个峰在 1.8 左右(此处用了对数单位,表示大约 6 个地球质量),第二个峰在 6.2 左右(大概 493 个地球质量)。
针对不同发现方式发现的行星,绘制各行星的公转周期和质量的关系。
从输出结果可以看出:径向速度(Radial Velocity)方法发现的行星在公转周期和质量上分布更宽,而凌日(Transit)似乎只能发现公转周期相对较短的行星,这是因为两种方法的原理差异造成的。对于公转周期很长的行星,其运行到恒星和观察者之间的时间也较长,因此凌日发现此类行星会相对较少。而径向速度与其说是在发现行星,不如说是在观察恒星,由于恒星自身发光,因此其观察机会更多,发现各类行星的可能性更大。
针对不同发现方式发现的行星,绘制各行星的距离和质量的关系。
从输出结果可以看出,凌日和径向速度对距离较为敏感,远距离的行星大多是通过凌日发现的,而近距离的行星大多数通过径向速度发现的。原因是:近距离的行星其引力对恒星造成的摆动更为明显,因此更容易观察;当距离较远时,引力作用变弱,摆动效应减弱,因此很难借助此方法观察到行星。同时,可以观察到当行星质量更大时,其距离分布相对较宽,这是因为虽然相对恒星的距离变长了,但是由于行星质量的增加,相对引力也同步增加,恒星摆动效应会变得明显。
将所有行星的质量和半径对数化处理,绘制其分布并拟合其分布。
由于:
因此,从原理上质量对数与半径对数应该是线性关系,且斜率为定值 3 ,截距的大小与密度相关。
从输出结果可以看出:行星质量和行星半径在对数变换下,具有较好的线性关系。输出 fix_xy 数值可知,其关系可以拟合出如下公式:
拟合出曲线对应的行星平均密度为:
同样的方式绘制恒星质量与半径的关系。
从输出结果可以看出,恒星与行星的规律不同,其质量与半径在对数下呈二次曲线关系,其关系符合以下公式:
同样的方式研究恒星表面重力加速度与半径的关系。
从输出结果可以看出,恒星表面对数重力加速度与其对数半径呈现较好的线性关系:
以上我们分别探索了各变量的分布和部分变量的相关关系,当数据较多时,可以通过 pd.plotting.scatter_matrix 接口,直接绘制各变量的分布和任意两个变量的散点图分布,对于数据的初步探索,该接口可以让我们迅速对数据全貌有较为清晰的认识。
通过行星的半径和质量,恒星的半径和质量,以及行星的公转周期等指标与地球的相似性,寻找诸多行星中最类似地球的行星。
从输出结果可以看出,在 0.6 附近的位置出现了一个最大的圆圈,那就是我们找到的类地行星 Kepler - 452 b ,让我们了解一下这颗行星:
数据显示,Kepler - 452 b 行星公转周期为 384.84 天,半径为 1.63 地球半径,质量为 3.29 地球质量;它的恒星为 Kepler - 452 半径为太阳的 1.11 倍,质量为 1.04 倍,恒星方面数据与太阳相似度极高。
以下内容来自百度百科。 开普勒452b(Kepler 452b) ,是美国国家航空航天局(NASA)发现的外行星, 直径是地球的 1.6 倍,地球相似指数( ESI )为 0.83,距离地球1400光年,位于为天鹅座。
2015 年 7 月 24 日 0:00,美国国家航空航天局 NASA 举办媒体电话会议宣称,他们在天鹅座发现了一颗与地球相似指数达到 0.98 的类地行星开普勒 - 452 b。这个类地行星距离地球 1400 光年,绕着一颗与太阳非常相似的恒星运行。开普勒 452 b 到恒星的距离,跟地球到太阳的距离相同。NASA 称,由于缺乏关键数据,现在不能说 Kepler - 452 b 究竟是不是“另外一个地球”,只能说它是“迄今最接近另外一个地球”的系外行星。
在银河系经纬度坐标下绘制所有行星,并标记地球和 Kepler - 452 b 行星的位置。
类地行星,是人类寄希望移民的第二故乡,但即使最近的 Kepler-452 b ,也与地球相聚 1400 光年。
以下通过行星的公转周期和质量两个特征将所有行星聚为两类,即通过训练获得两个簇心。
定义函数-计算距离
聚类距离采用欧式距离:
定义函数-训练簇心
训练簇心的原理是:根据上一次的簇心计算所有点与所有簇心的距离,任一点的分类以其距离最近的簇心确定。依此原理计算出所有点的分类后,对每个分类计算新的簇心。
定义函数预测分类
根据训练得到的簇心,预测输入新的数据特征的分类。
开始训练
随机生成一个簇心,并训练 15 次。
绘制聚类结果
以最后一次训练得到的簇心为基础,进行行星的分类,并以等高面的形式绘制各类的边界。
从运行结果可以看出,所有行星被分成了两类。并通过上三角和下三角标注了每个类别的簇心位置。
聚类前
以下输出了聚类前原始数据绘制的图像。
python根据json数据画疫情分布地图
目录

注:数据集在文章最后
一.基础地图使用
1.掌握使用pyecharts构建基础的全国地图可视化图表
演示
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts
map=Map()
data=[
("北京",99),
("上海",199),
("湖南",299),
("台湾",199),
("安徽",299),
("广州",399),
("湖北",599)
]
map.add("地图",data,"china")
map.set_global_opts(
visualmap_opts=VisualMapOpts(
is_show=True
)
)
map.render("1.html")
结果是
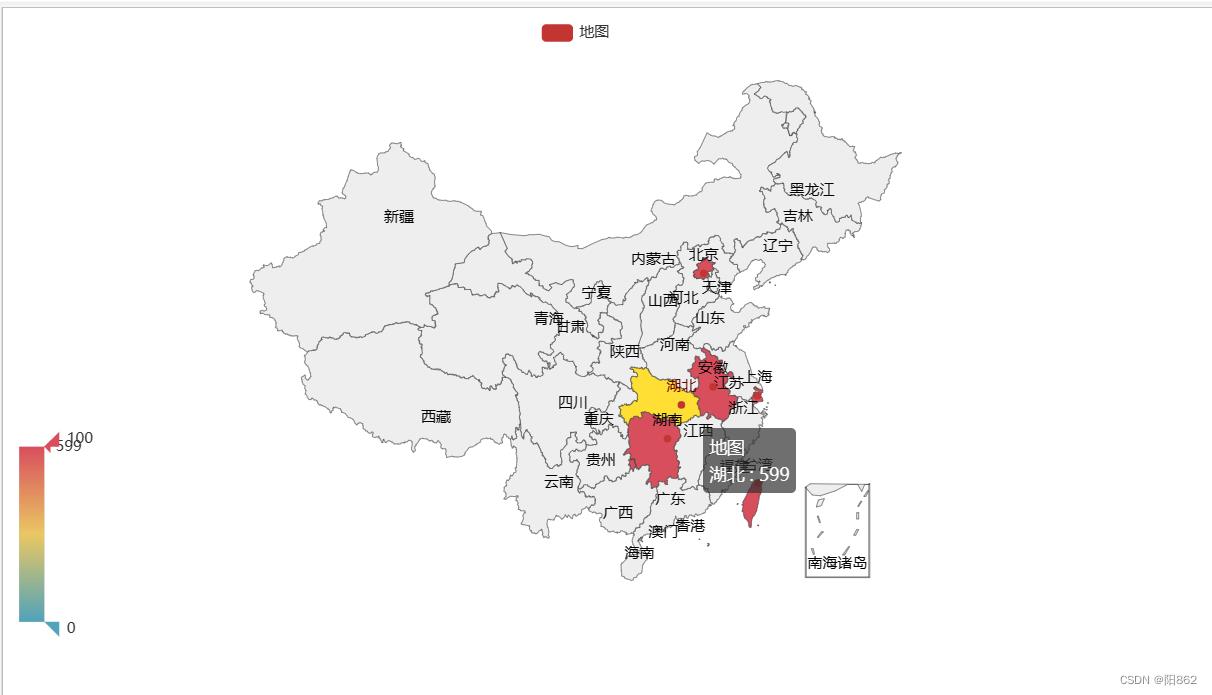
这里有个问题

is_show=True表示展示图例,但是不准怎么办?
这就需要手动校准范围
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts
map=Map()
data=[
("北京",99),
("上海",199),
("湖南",299),
("台湾",199),
("安徽",299),
("广州",399),
("湖北",599)
]
map.add("地图",data,"china")
map.set_global_opts(
visualmap_opts=VisualMapOpts(
is_show=True,
is_piecewise=True,
pieces=[
"min": 1, "max": 9, "label": "1-9人", "color": "#CCFFFF",
"min": 10, "max": 99, "label": "10-99人", "color": "#FFFF99",
"min": 100, "max": 499, "label": "100-499人", "color": "#FF9966",
"min": 500, "max": 999, "label": "500-999人", "color": "#FF6666",
"min": 1000, "max": 9999, "label": "1000-9999人", "color": "#CC3333",
"min": 10000, "label": "10000以上", "color": "#990033",
]
)
)
map.render("1.html")
结果是

这样就可以了
再解释一下颜色的设置


这样就可以查询相应的颜色
二.疫情地图——国内疫情地图
1.案例效果
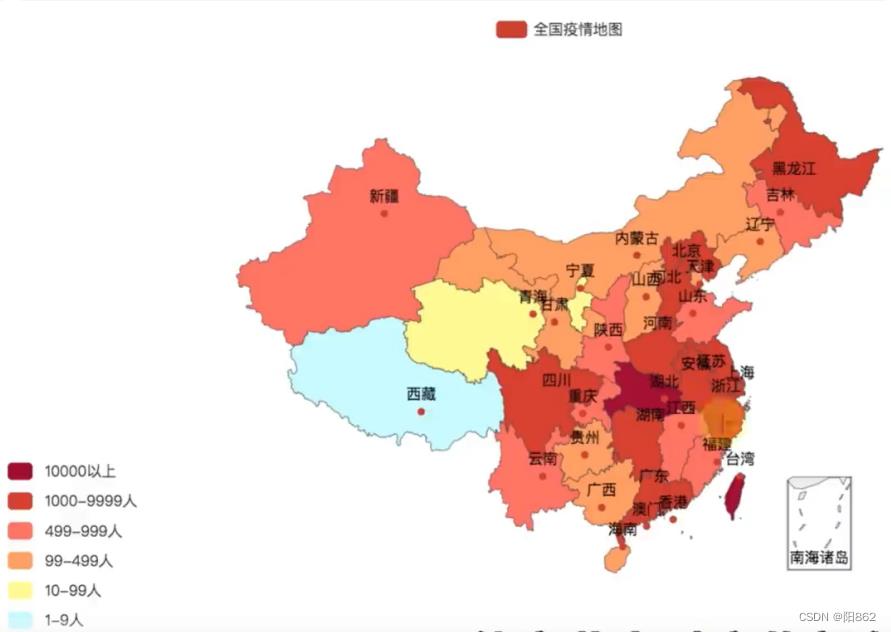
演示

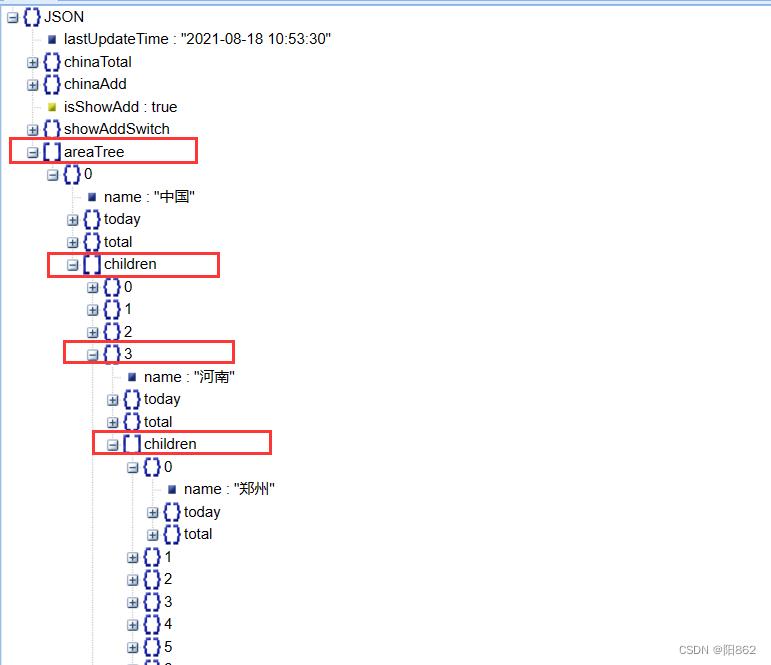
利用json在线在线解析工具可以看到
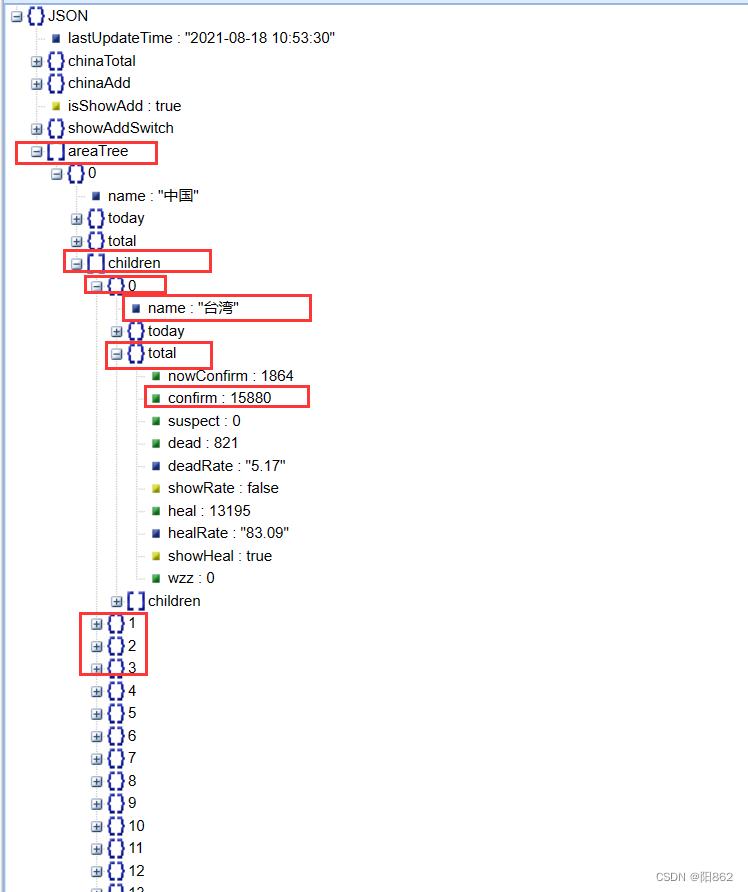
那么我们就可以知道该怎么去提取
#从字典中取出省份数据
province_data_list=data_dict["areaTree"][0]["children"]代码
import json
from pyecharts.charts import Map
from pyecharts.options import *
#读取文件
f=open("D:/疫情.txt","r",encoding="utf-8")
data=f.read()
#关闭文件
f.close()
#获取各省数据
#将字符串json转化为python的字典
data_dict=json.loads(data)
#从字典中取出省份数据
province_data_list=data_dict["areaTree"][0]["children"]
#组装每个省份和确诊人数为元组,并各个省的数据都封装如列表
data_list=[]#绘图需要用到数据列表
for province_data in province_data_list:
province_name=province_data["name"]#省份名称
province_confirm=province_data["total"]["confirm"]#确诊人数
data_list.append((province_name,province_confirm))#这里注意列表里面嵌套的是元组
print(f"type(data_list)\\ndata_list")
#创建地图对象
map=Map()
#添加数据
map.add("各省份确诊人数",data_list,"china")
#设置全局配置,定制分段到1视觉映射
map.set_global_opts(
title_opts=TitleOpts("全国疫情地图",pos_left="center",pos_bottom="1%"),
visualmap_opts=VisualMapOpts(
is_show=True,#是否显示
is_piecewise=True,#是否分段
pieces=[
"min": 1, "max": 9, "label": "1-9人", "color": "#CCFFFF",
"min": 10, "max": 99, "label": "10-99人", "color": "#FFFF99",
"min": 100, "max": 499, "label": "100-499人", "color": "#FF9966",
"min": 500, "max": 999, "label": "500-999人", "color": "#FF6666",
"min": 1000, "max": 9999, "label": "1000-9999人", "color": "#CC3333",
"min": 10000, "label": "10000以上", "color": "#990033",
]
)
)
map.render("全国疫情地图.html")结果是
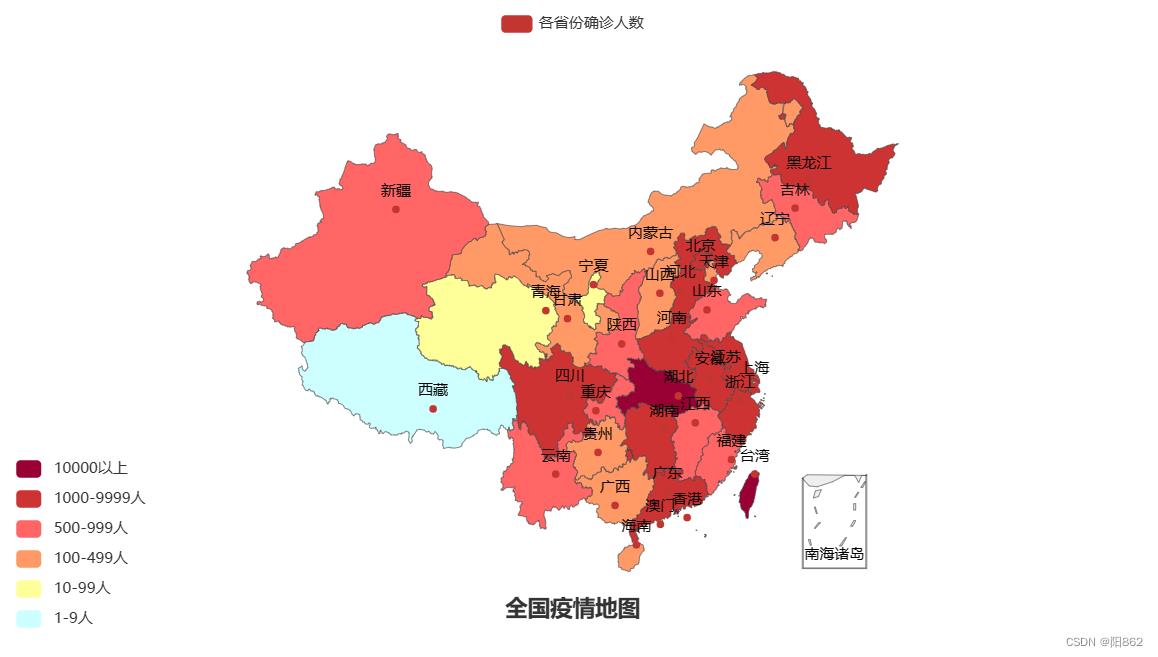
三.疫情地图——省级疫情地图
以河南省为例
代码
import json
from pyecharts.charts import Map
from pyecharts.options import *
f=open("D:/疫情.txt","r",encoding="utf-8")
data=f.read()
#关闭文件
f.close()
#json数据转化为python字典
data_dict=json.loads(data)
#取到河南省数据
cities_data=data_dict["areaTree"][0]["children"][3]["children"]
#准备数据为元组并放入list
data_list=[]
for city_data in cities_data:
city_name=city_data["name"]+"市"
city_confirm=city_data["total"]["confirm"]
data_list.append((city_name,city_confirm))
#构建地图
map=Map()
map.add("河南省疫情分布",data_list,"河南")
#设置全局选项
map.set_global_opts(
title_opts=TitleOpts(title="河南疫情地图"),
visualmap_opts=VisualMapOpts(
is_show=True,#是否显示
is_piecewise=True,#是否分段
pieces=[
"min": 1, "max": 9, "label": "1-9人", "color": "#CCFFFF",
"min": 10, "max": 99, "label": "10-99人", "color": "#FFFF99",
"min": 100, "max": 499, "label": "100-499人", "color": "#FF9966",
"min": 500, "max": 999, "label": "500-999人", "color": "#FF6666",
"min": 1000, "max": 9999, "label": "1000-9999人", "color": "#CC3333",
"min": 10000, "label": "10000以上", "color": "#990033",
]
)
)
map.render("河南疫情地图.html")结果是
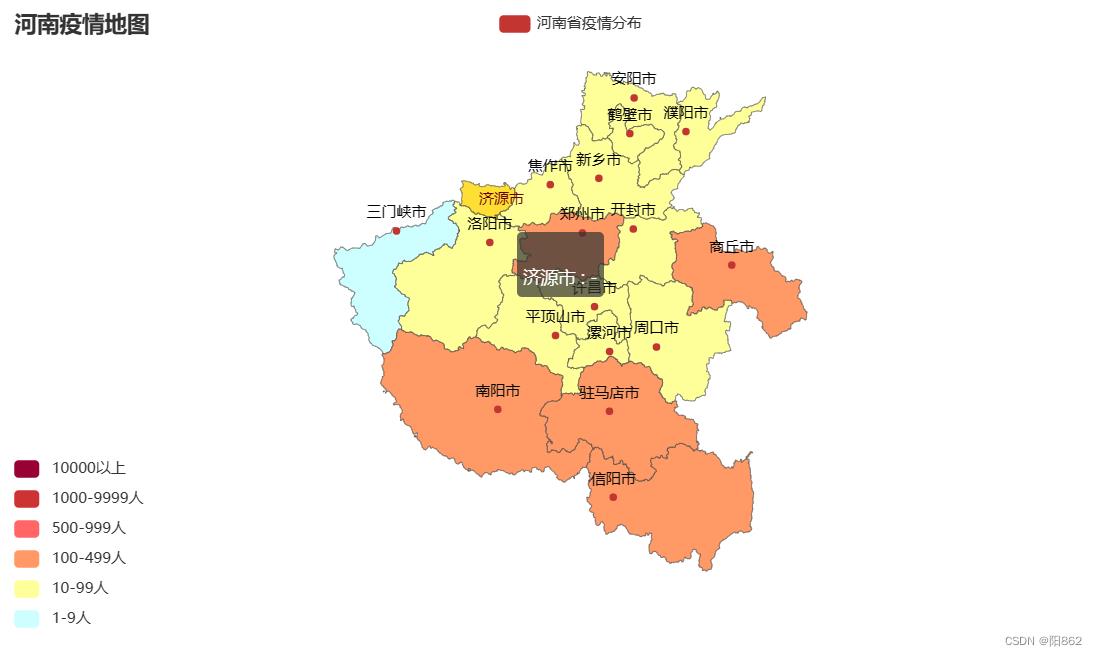
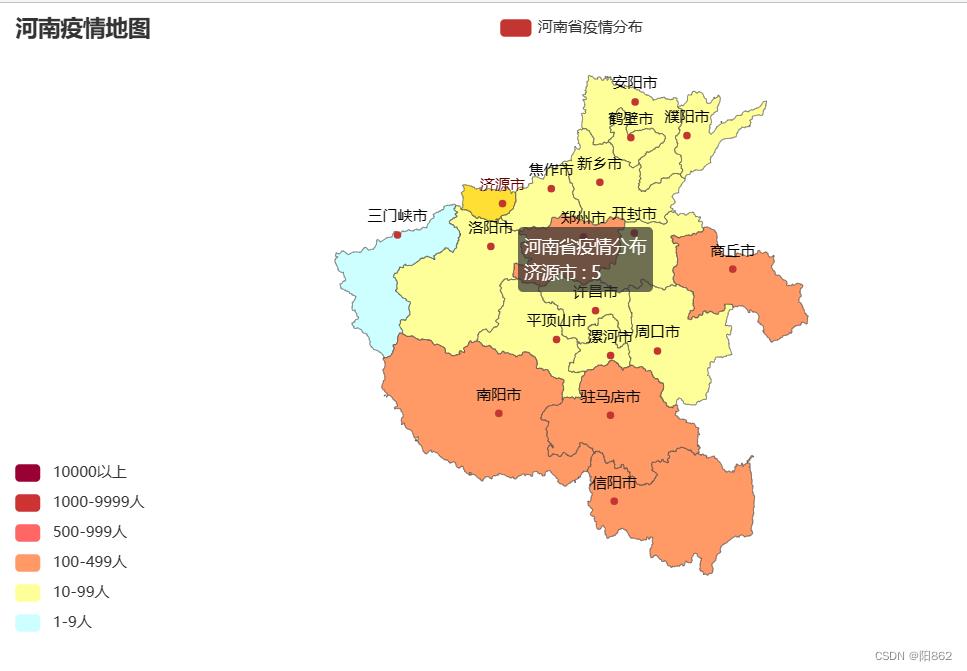
有个问题:济源市因为数据集中没有相应数据,所以需要我们手动加上去

这样就可以了
结果是
四.数据集
链接:https://pan.baidu.com/s/1wX9hTrpwM42FAwqyb6O7fg
提取码:1234


以上是关于121 11 个案例掌握 Python 数据可视化--星际探索的主要内容,如果未能解决你的问题,请参考以下文章