c语言里面的float是啥意思
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了c语言里面的float是啥意思相关的知识,希望对你有一定的参考价值。
请通俗一点
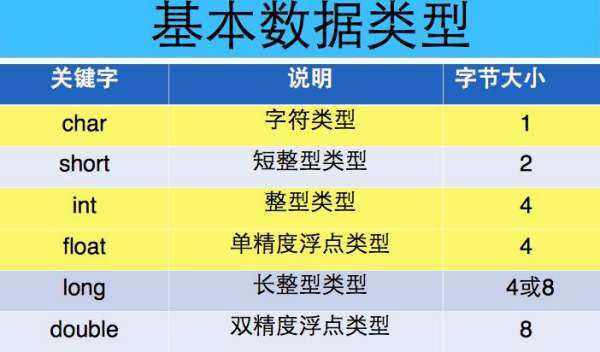
C语言中float浮点型数据类型,FLOAT数据类型用于存储单精度浮点数或双精度浮点数。
浮点数使用 IEEE(电气和电子工程师协会)格式。浮点类型的单精度值具有 4 个字节,包括一个符号位、一个
8 位 excess-127 二进制指数和一个 23 位尾数。
尾数表示一个介于 1.0 和 2.0 之间的数。由于尾数的高顺序位始终为 1,因此它不是以数字形式存储的。此表示形式为 float 类型提供了一个大约在 -3.4E+38 和 3.4E+38 之间的范围。
扩展资料
float造成的影响:
1、对其兄弟元素(浮动)的影响
当一个浮动元素在浮动过程中碰到同一个方向的浮动元素时,它会紧跟在它们后面,可以用这样一个形象的比喻来描述: 在一个购票中心里,某人从一条购票队列跑到旁边的一条购票队列中排队,那自然先跑过去的会先占据前面的位置。
2、float对自身元素的影响
float对象将被视作块对象(block-level),即display属性等于block。
3、float对子元素的影响
我们知道当一个元素浮动时,在没有清楚浮动的情况下,它无法撑开其父元素,但它可以让自己的浮动子元素撑开它自身,并且在没有定义具体宽度情况下,使自身的宽度从100%变为自适应(浮动元素display:block)。其高度和宽度均为浮动元素高度和非浮动元素高度之间的最大值。
参考资料来源:百度百科-FLOAT
意思是浮点型数据类型,通俗点讲利用指数使小数点的位置可以根据需要而上下浮动,从而可以灵活地表达更大范围的实数。
float 占用32位存储空间的单精度(single-precision )值。在一些处理器上比双精度更快而且只占用双精度一半的空间,但是当值很大或很小的时候,它将变得不精确。当你需要小数部分并且对精度的要求不高时,浮点型的变量是有用的。
在计算机系统的发展过程中,曾经提出过多种方法表示实数,但是到目前为止使用最广泛的是浮点表示法。相对于定点数而言,浮点数利用指数使小数点的位置可以根据需要而上下浮动,从而可以灵活地表达更大范围的实数。
扩展资料:
1、float的作用:
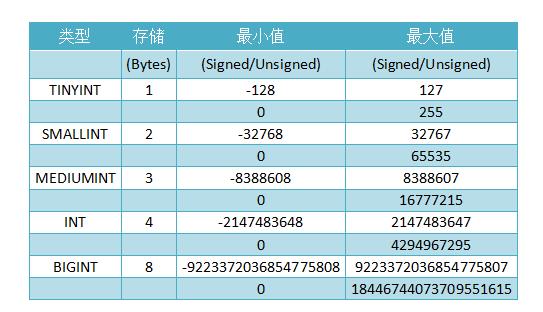
FLOAT 数据类型用于存储单精度浮点数或双精度浮点数,浮点数使用 IEEE(电气和电子工程师协会)格式。
浮点类型的单精度值具有 4 个字节,包括一个符号位、一个 8 位 excess-127 二进制指数和一个 23 位尾数,尾数表示一个介于 1.0 和 2.0 之间的数,由于尾数的高顺序位始终为 1,因此它不是以数字形式存储的。
此表示形式为 float 类型提供了一个大约在 -3.4E+38 和 3.4E+38 之间的范围。
2、如果存储比精度更重要,请考虑对浮点变量使用 float 类型。相反,如果精度是最重要的条件,则使用 double 类型。
参考资料:百度百科-FLOAT
百度百科-浮点型
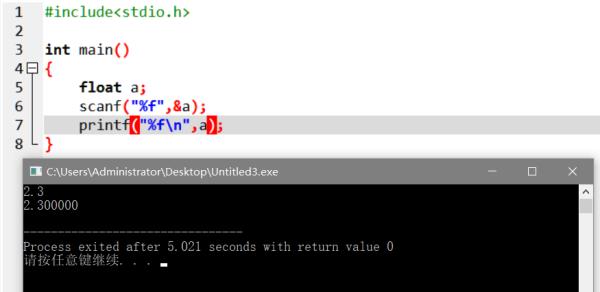
float是单精度数据类型,占4个字节的存储单元。
定义输入输出举例如下:
拓展资料
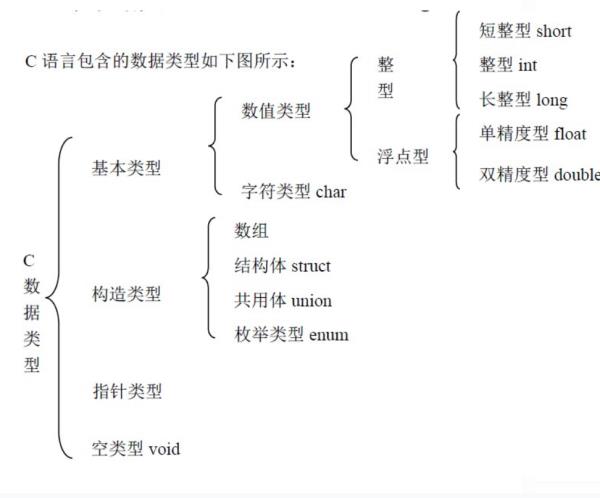
C语言是一门通用计算机编程语言,广泛应用于底层开发。C语言的设计目标是提供一种能以简易的方式编译、处理低级存储器、产生少量的机器码以及不需要任何运行环境支持便能运行的编程语言。
尽管C语言提供了许多低级处理的功能,但仍然保持着良好跨平台的特性,以一个标准规格写出的C语言程序可在许多电脑平台上进行编译,甚至包含一些嵌入式处理器(单片机或称MCU)以及超级电脑等作业平台。
二十世纪八十年代,为了避免各开发厂商用的C语言语法产生差异,由美国国家标准局为C语言制定了一套完整的美国国家标准语法,称为ANSI C,作为C语言最初的标准。 [1] 目前2011年12月8日,国际标准化组织(ISO)和国际电工委员会(IEC)发布的C11标准是C语言的第三个官方标准,也是C语言的最新标准,该标准更好的支持了汉字函数名和汉字标识符,一定程度上实现了汉字编程。
C语言是一门面向过程的计算机编程语言,与C++,Java等面向对象的编程语言有所不同。
其编译器主要有Clang、GCC、WIN-TC、SUBLIME、MSVC、Turbo C等。
其定义与初始化操作如下:
float a; // 定义一个float类型的变量a
float b=5.36 // 定义一个float类型的变量b,并赋值为5.36 参考技术D 就是浮点类型,通俗来说就是小数,精确到几位我忘记了,double也是显示小数的,不过double精度很高
c语言中double是啥意思
double是C语言的一个关键字,代表双精度浮点型。
结构:
1.从存储结构和算法上来讲,double是64位的,所以double能存储更高的精度。
2.目前C/C++编译器标准都遵照IEEE制定的浮点数表示法来进行float,double运算。这种结构是一种科学计数法,用符号、指数和尾数来表示。
3.由于通常C编译器默认浮点数是double型的,下面以double为例:
共计64位,折合8字节。由最高到最低位分别是第63、62、61、……、0位:
最高位63位是符号位,1表示该数为负,0正;
62-52位,一共11位是指数位;
51-0位,一共52位是尾数位。
按照IEEE浮点数表示法,下面将把double型浮点数38414.4转换为十六进制代码。
把整数部和小数部分开处理:整数部直接化十六进制:960E。小数的处理:
0.4=0.5*0+0.25*1+0.125*1+0.0625*0+……
实际上这永远算不完,这就是著名的浮点数精度问题。所以直到加上前面的整数部分算够53位就行了(隐藏位技术:最高位的1不写入内存)。
手工算到53位那么应该是:38414.4(10)=1001011000001110.0110101010101010101010101010101010101(2)
科学记数法为:1.001……乘以2的15次方。指数为15。
于是来看阶码,一共11位,可以表示范围是-1024 ~ 1023。因为指数可以为负,为了便于计算,规定都先加上1023,在这里,
15+1023=1038。二进制表示为:100 00001110 。
符号位:正— 0 。
合在一起(尾数二进制最高位的1不要):
01000000 11100010 11000001 11001101
01010101 01010101 01010101 01010101
按字节倒序存储的十六进制数就是:
55 55 55 55 CD C1 E2 40
在C语言中, double 输入输出使用格式字符%lf 参考技术B 回答
您好,对方要双份的吧Double[ˈdəb(ə)l]adj. 供两者用的;两倍的;成双的;双层的;双写的;双重的;重瓣的adv. 两倍地;重叠地pron. 两倍vt. 把⋯增加一倍;把⋯对折;双写;握紧;重复;把⋯加倍vi. 增加一倍;兼作;兼任;兼奏;做替身演员;叫加倍n. 酷似的人;替身演员;一杯双份的烈酒;双份物;复式下注;叫加倍;双倍;双点;两次获胜npl. 双打
参考技术C double是C语言中的双精度浮点数类型,用来表示实数。1 定义:
double var_name;
这样定义一个名字为var_name的double类型变量。
2 赋值:
var_name = 100.325;
同其它类型的赋值语句一样,对var_name赋值用=运算符,右侧可以是任意表达式。
3 输入:
scanf("%lf", &var_name);
%lf格式符号对应double,可以用来对double类型输入,以下输出类似。
4 输出:
printf("%lf", var_name);本回答被提问者采纳 参考技术D double是指双精度浮点数类型。float指单精度浮点数类型。
它们的区别是精度的不同,double类型的精度约等于float的两倍。
精度指精确到小数点后多少位。
都是用来声明变量或常量类型的。
以上是关于c语言里面的float是啥意思的主要内容,如果未能解决你的问题,请参考以下文章
c里面,double a=0.65f 这样的赋值是啥意思,是错的吗?