hadoop2.9.2安裝
Posted 叶子8324
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop2.9.2安裝相关的知识,希望对你有一定的参考价值。
hadoop安装-centsos7
创建用户
[root@master .ssh]# useradd hadoop
[root@master .ssh]# password hadoop
bash: password: command not found…
[root@master .ssh]# passwd hadoop
Changing password for user hadoop.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
[root@master .ssh]# su hadoop
修改hostname
vi /etc/hostname
输入master
修改IP地址
cd /etc/sysconfig/network-scripts/
vi ifcfg-eno16777736
原:
TYPE=Ethernet
BOOTPROTO=dhcp
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
IPV6_FAILURE_FATAL=no
NAME=eno16777736
UUID=55cdf40e-3990-47be-ba94-79a7d98ce611
DEVICE=eno16777736
ONBOOT=no
修改后:
TYPE=Ethernet
BOOTPROTO=static
IPADDR=192.168.2.201
BROADCAST=192.168.2.1
DNS1=192.168.2.1
NETMASK=255.255.255.0
NM_CONTROLLED=no
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
UUID=55cdf40e-3990-47be-ba94-79a7d98ce611
DEVICE=eno16777736
ONBOOT=yes
PEERDNS=yes
PEERROUTES=yes
修改host映射
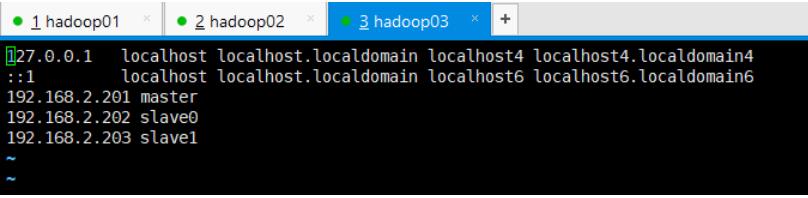
vi /etc/hosts
192.168.2.201 master
192.168.2.202 slave0
192.168.2.203 slave1
查看防火墙状态
systemctl status firewalld.service

linux默认启动是启动防火墙的,这里我们需要关掉防火墙
systemctl stop firewalld.service
关闭防火墙自启
systemctl disable firewalld.service

安装jdk
在root账号下安装jdk
下载jdk拖拽到admin下
授权
chmod 777 jdk jdk-8u161-linux-x64.tar.gz
创建jdk保存目录,并将
mkdir /usr/java
移动安装包
mv jdk-8u161-linux-x64.tar.gz /usr/java
解压
tar -zxvf jdk-8u161-linux-x64.tar.gz
配置环境变量
vi /etc/profile
末尾添加
export JAVA_HOME=/usr/java/jdk1.8.0_161
export JRE_HOME=/usr/java/jdk1.8.0_161/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH
重新加载/etc/profile
source /etc/profile

验证成功
免登录配置
master节点配置s
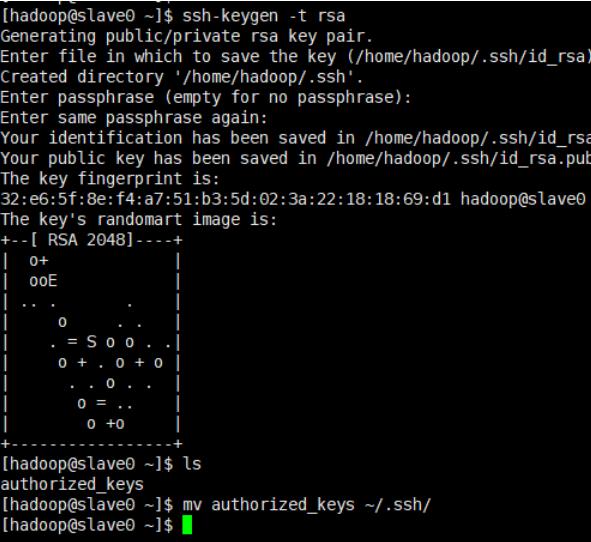
生成秘钥
ssh-keygen -t rsa
然后一路回车就好
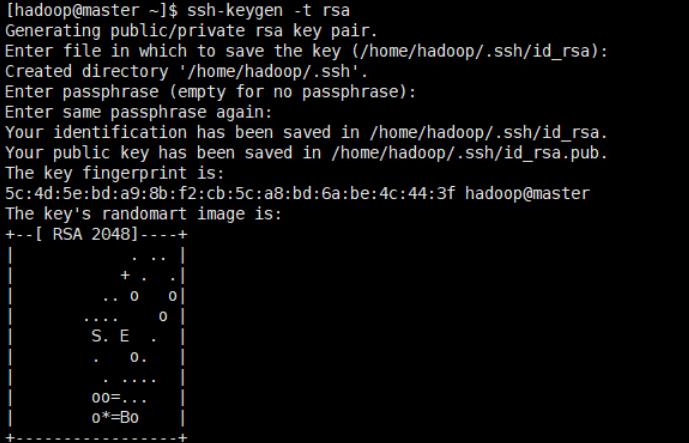
生成的秘钥在.ssh目录下/home/hadoop/.ssh/id_rsa.pub
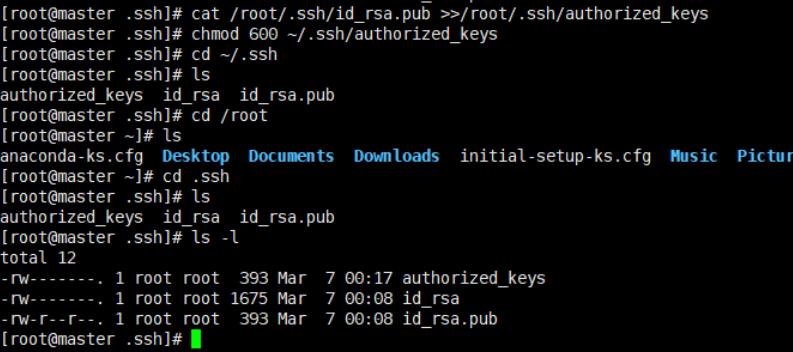
将公钥文件复制到已授权目录
cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys
修改文件权限
chmod 600 ~/.ssh/authorized_keys
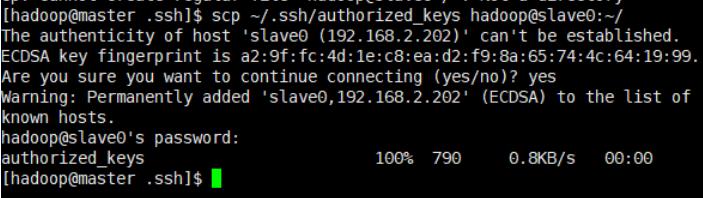
复制文件到slave节点
scp ~/.ssh/authorized_keys hadoop@slave0:~/
创建slave0秘钥,并移动从主节点传递过来的秘钥
ssh-keygen -t rsa
mv authorized_keys ~/.ssh/
cd ~/.ssh
chmod 600 authorized_keys
slave1同上配置
scp ~/.ssh/authorized_keys hadoop@slave1:~/
配置完毕后再master测试
ssh slave0

如图效果,不用输入密码说明成功
退出 exit即可
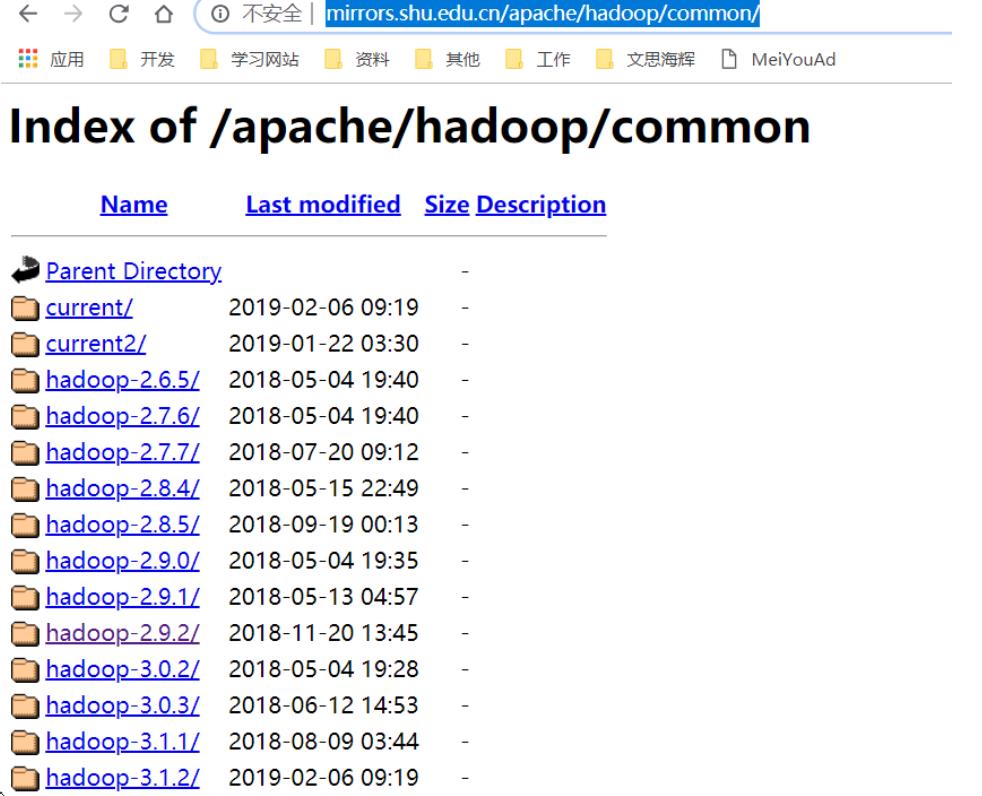
hadoop安装
下载hadoop并解压
http://mirrors.shu.edu.cn/apache/hadoop/common/
解压
tar -zxvf ~/hadoop/hadoop-2.9.2.tar.gz
配置hadoop-env.sh
cd ~/hadoop-2.9.2/etc/hadoop/
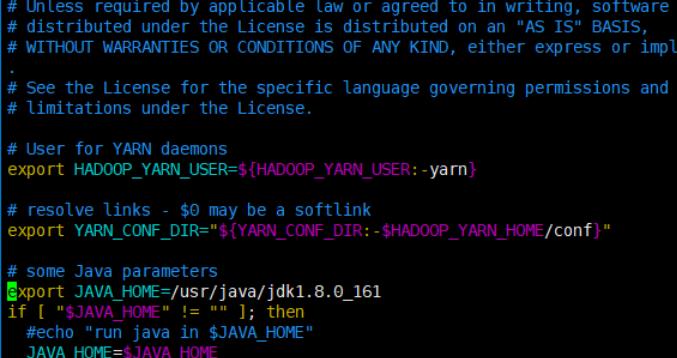
修改java路径
/usr/java/jdk1.8.0_161

yarn环境
vi yarn-env.sh
核心文件core-site.xml
vi core-site.xml
中间添加内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoopdata</value>
</property>

配置文件系统
vi hdfs-site.xml
<name>dfs.replication</name>
<value>1</value>

配置yarn-site.xml文件
vi yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>

配置mapreduce
拷贝并重命名
cp mapred-site.xml.template mapred-site.xml
修改文件
vi mapred-site.xml
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

配置master的slaves
vi slaves
删除之前的localhost
复制master上的hadoop到slave节点
scp -r /home/hadoop/hadoop-2.9.2 hadoop@slave0:~/
scp -r /home/hadoop/hadoop-2.9.2 hadoop@slave1:~/
su root
mkdir /usr/java
scp -r /usr/java/jdk1.8.0_161 hadoop@slave0:/usr/java/
scp -r /usr/java/jdk1.8.0_161 hadoop@slave1:/usr/java/
配置系统环境变量
su hadoop
vi ~/.bash_profile
这里是该用户下的配置环境变量,不是系统全局变量,换个用户就不起作用了
将hadoop配置信息加入
#hadoop
export HADOOP_HOME=/home/hadoop/hadoop-2.9.2
export PATH=$HADOOP_HOME/bin:$PATH

刷新配置项
source ~/.bash_profile
创建hadoop数据目录
mkdir /home/hadoop/hadoopdata
注意和之前core-site.xml配置的路径一致
格式化文件系统
hdfs namenode -format
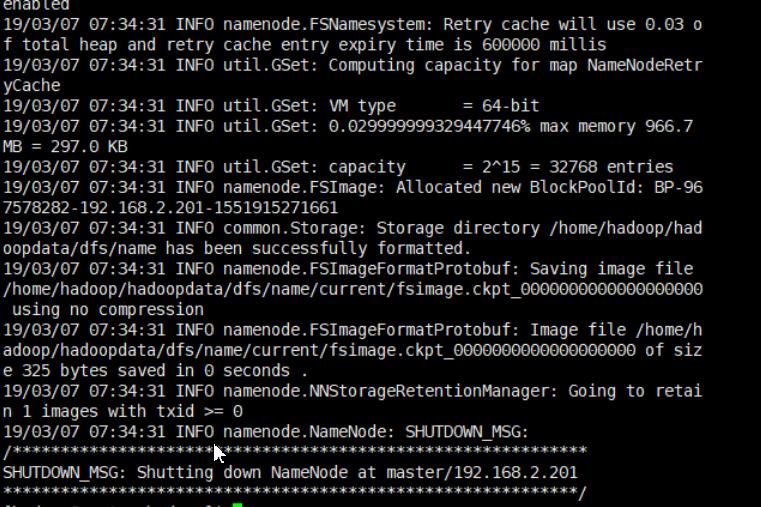
如果没有出现Error或者Exception说明格式化正确
启动和关闭hadoop
进入hadoop安装目录然后执行
cd ~/hadoop-2.9.2
sbin/start-all.sh
~/hadoop-2.9.2/sbin/start-all.sh

验证是否启动成功
jps
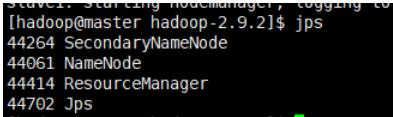
如图出现
SecondaryNameNode、 NameNode、 ResourceManager、 Jps说明启动成功
访问地址http://master:18088/
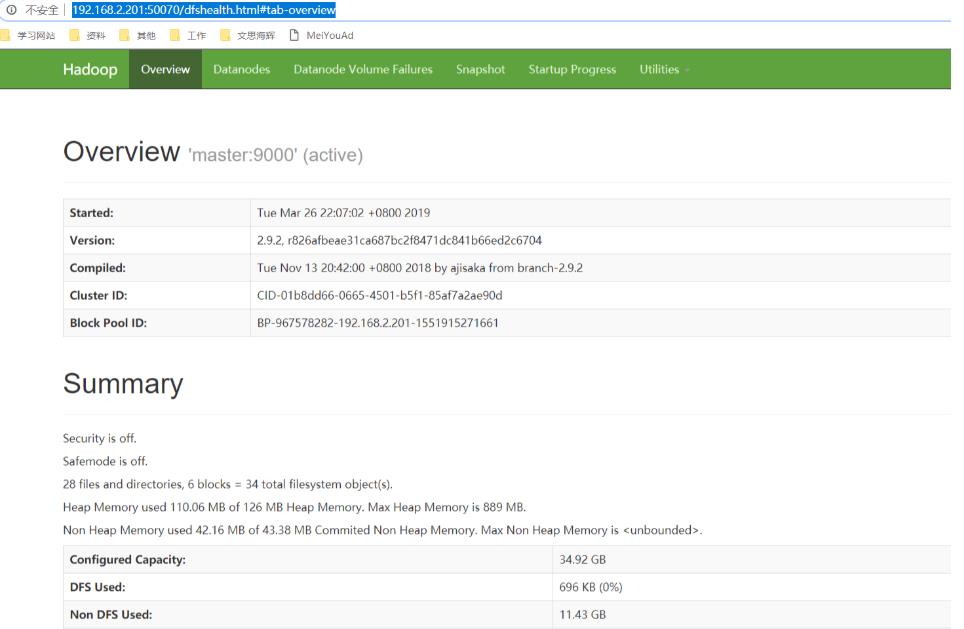
查看hadoop运行状态

http://192.168.2.201:50070/dfshealth.html#tab-overview
这里展示hdfs
mapreduce例子在该目录
/home/hadoop/hadoop-2.9.2/share/hadoop/mapreduce

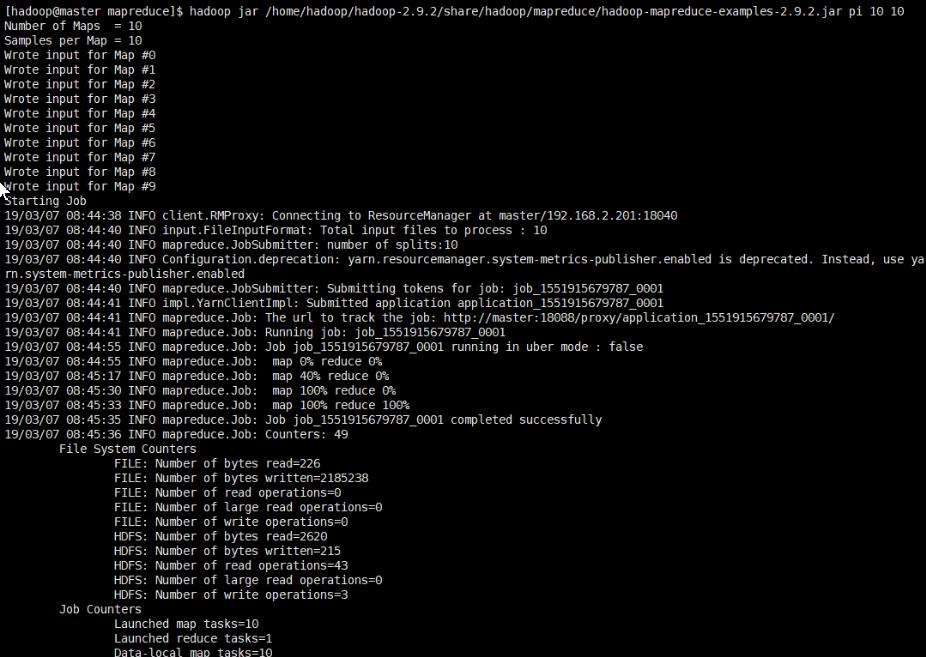
运行MapReduce程序
hadoop jar /home/hadoop/hadoop-2.9.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar pi 10 10
pi是类型,第一个10表示map次数,第二个10表示随机生成点的次数(与计算机原理有关)
hadoop常用命令
hdfs基本命令
命令均有bin/hadoop脚本引发,不指定参数运行hadoop脚本将显示所有命令的描述,可通过hadoop fs -help查看所有命令的帮助文件。
[hadoop@master ~]$ hadoop fs -help
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] -n name | -d [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [-b|-k -m|-x <acl_spec> <path>]|[--set <acl_spec> <path>]]
[-setfattr -n name [-v value] | -x name <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
-appendToFile <localsrc> ... <dst> :
Appends the contents of all the given local files to the given dst file. The dst
file will be created if it does not exist. If <localSrc> is -, then the input is
read from stdin.
-cat [-ignore
- 查看hdfs文件列表
hadoop fs -ls /

- 创建目录
hadoop fs -mkdir /test
hadoop fs -mkdir /test/input
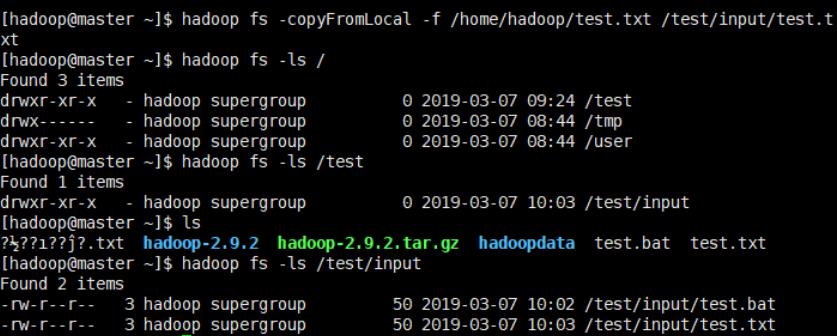
- 本地上传文件到hdfs
两种hadoop fs -put和hadoop fs -copyFromLocal
hadoop fs -put /home/hadoop/test.bat /test/input/test.bat
hadoop fs -copyFromLocal -f /home/hadoop/test.txt /test/input/test.txt

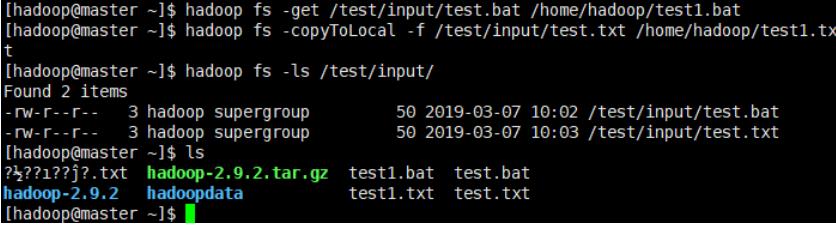
- hdfs文件下载到本地
hdoop fs -get或者hadoop fs -copyToLocal
hadoop fs -get /test/input/test.bat /home/hadoop/test1.bat
hadoop fs -copyToLocal -f /test/input/test.txt /home/hadoop/test1.txt
 - 查看hdfs文件内容
- 查看hdfs文件内容
hadoop fs -cat /test/input/test.txt

可以将cat换成text或者tail
- 删除hdfs文件
hadoop fs -rm /test/input/test.txt

以上是关于hadoop2.9.2安裝的主要内容,如果未能解决你的问题,请参考以下文章