使用Hive SQL查询Iceberg表的正确姿势
Posted 咬定青松
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Hive SQL查询Iceberg表的正确姿势相关的知识,希望对你有一定的参考价值。
本文首发微信公众号:码上观世界
Iceberg作为一种表格式管理规范,其数据分为元数据和表数据。元数据和表数据独立存储,元数据目前支持存储在本地文件系统、HMS、Hadoop、JDBC数据库、AWS Glue和自定义存储。表数据支持本地文件系统、HDFS、S3、MinIO、OBS、OSS等。元数据存储基于HMS比较广泛,在这篇文章中,表数据存储基于MinIO、元数据存储主要基于HMS。实际上,基于HMS存储的元数据也只是很少的信息存储在HMS中,主体元数据还是存储在外部系统,如HDFS、MinIO等,所以这里也不得不提基于Hadoop存储的方式。
Iceberg的元数据管理通过Catalog类型指定,我们主要关注hive、hadoop和location_based_table这三种。
如果不指定任何Catalog类型,直接创建表会怎么样呢?
add jar /Users/deepexi/.m2/repository/org/apache/iceberg/iceberg-hive-runtime/0.13.2/iceberg-hive-runtime-0.13.2.jar;
SET hive.vectorized.execution.enabled=false;
CREATE TABLE default.sample_local_hive_table_1(
id bigint, name string
)
PARTITIONED BY(
dept string
)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';借助HiveIcebergStorageHandler,此时会在本地HMS(hive-site.xml中配置) 中存储元数据,元数据表table_params显示,当前表的存储位置使用了本地HMS (hive-site.xml中配置)的文件存储路径:

这符合创建Hive表的常规动作。来看看,如果指定hive的Catalog,并配置远程的HMS,会怎么样?
注册hive类型的Catalog
这里注册了一个远端的HMS地址:
SET iceberg.catalog.another_hive.type=hive;
SET iceberg.catalog.another_hive.uri=thrift://10.201.0.202:49153;
SET iceberg.catalog.another_hive.warehouse=s3a://faas-ethan/warehouse/;
SET hive.vectorized.execution.enabled=false;在当前HiveCli创建Hive Iceberg 表,同时指定location 存储位置,使用上面注册的hive类型的Catalog:
CREATE TABLE default.sample_hive_table_1(
id bigint, name string
)
PARTITIONED BY(
dept string
)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
location 's3a://faas-ethan/warehouse/default/sample_hive_table_1'
TBLPROPERTIES ('iceberg.catalog'='another_hive');到本地HMS(hive-site.xml中配置) table_params元数据表中确认当前表的存储参数:

Location信息存储在SDS表中。该表存储类型为MANAGED_TABLE。再到远程HMS(another_hive指定)的元数据表table_params看存储内容:
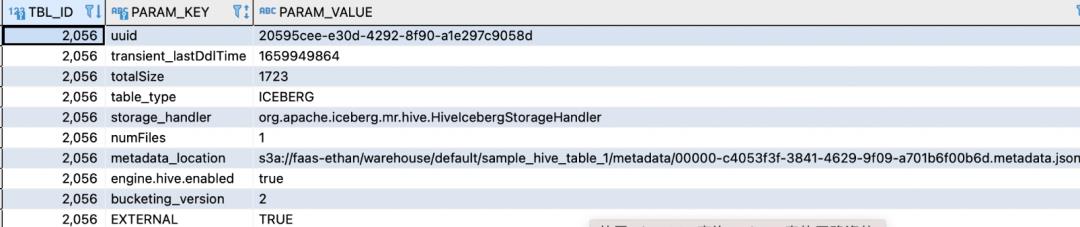
除了本地HMS存储的信息外,还多了有关Iceberg的统计信息、元数据位置信息。Location信息也同步复制了一份,存储在SDS表中,但该表存储类型变成了EXTERNAL_TABLE。由此可见,在Hive中创建Iceberg表,会在两边HMS分别存储一份元数据,只有这样,远端HMS中的Iceberg表才对本地HMS可见,所以必须保证远端HMS存在对应的数据库。如果在当前Hive Cli查看建表语句,会得到下面的输出:
show create table sample_hive_table_1;
CREATE TABLE `sample_hive_table_1`(
`id` bigint COMMENT 'from deserializer',
`name` string COMMENT 'from deserializer',
`dept` string COMMENT 'from deserializer')
ROW FORMAT SERDE
'org.apache.iceberg.mr.hive.HiveIcebergSerDe'
STORED BY
'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
WITH SERDEPROPERTIES (
'serialization.format'='1')
LOCATION
's3a://faas-ethan/warehouse/default/sample_hive_table_1'
TBLPROPERTIES (
'bucketing_version'='2',
'external.table.purge'='TRUE',
'iceberg.catalog'='another_hive',
'table_type'='ICEBERG',
'transient_lastDdlTime'='1659949858')
Time taken: 5.45 seconds, Fetched: 18 row(s)这表示,Hive Cli返回的信息来自本地HMS,同普通Hive类似。
问题:如果只有远端HMS的Iceberg表,如何在本地HMS访问?
此时可以通过如下创建external外表的形式在本地HMS生成元数据:
CREATE EXTERNAL TABLE default.sample_hive_table_1(
id bigint, name string
)
PARTITIONED BY(
dept string
)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
location 's3a://faas-ethan/warehouse/default/sample_hive_table_1'
TBLPROPERTIES ('iceberg.catalog'='another_hive');这有什么作用?试试下面的语句:
select * from default.sample_local_hive_table_1,sample_hive_table_1;看到没?它通过Hive SQL实现了跨HMS的联邦查询!
注册Hadoop类型的Catalog
SET iceberg.catalog.hadoop_cat.type=hadoop;
SET iceberg.catalog.hadoop_cat.warehouse=s3a://faas-ethan/warehouse;用注册的hadoop类型的Catalog,创建hadoop Iceberg表:
CREATE TABLE default.sample_hadoop_table_1(
id bigint, name string
) PARTITIONED BY (
dept string
)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 's3a://faas-ethan/warehouse/default/sample_hadoop_table_1'
TBLPROPERTIES ('iceberg.catalog'='hadoop_cat');如果你去看存储的元数据,会发现它跟使用hive类型的Catalog创建的表,少了metadata_location属性:

同时在MinIo中的metadata元数据文件多了version-hint.text:

这是因为两者管理当前最新元数据的版本机制不同。所以你不能基于hadoop类型的Catalog ,创建hive类型的Catalog 的Iceberg表。反过来也一样不行。
问题:当前表通过Hive Cli创建,所以会在HMS存储元数据,假如Iceberg表通过Iceberg API创建,HMS完全没有相关信息,那如何才能访问这种hadoop Iceberg表呢?
此时通过location指定hadoop中存储表的路径,然后通过EXTERNAL将在HMS中注册元数据,Hive会自动从中推断表Schema:
SET iceberg.catalog.hadoop_cat.type=hadoop;
SET iceberg.catalog.hadoop_cat.warehouse=s3a://faas-ethan/warehouse;
CREATE EXTERNAL TABLE default.sample_hadoop_table_1
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
location 's3a://faas-ethan/warehouse/default/sample_hadoop_table_1'
TBLPROPERTIES ('iceberg.catalog'='hadoop_cat');此时location必须符合格式:$iceberg.catalog.hadoop_cat.warehouse/$dbName/$tableName,否则无法识别存储格式。
上述创建外表的方式也可以使用下面的方式实现:
CREATE EXTERNAL TABLE default.sample_hadoop_table_1
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
location 's3a://faas-ethan/warehouse/default/sample_hadoop_table_1'
TBLPROPERTIES ('iceberg.catalog'='location_based_table');In a nutshell
使用Hive SQL 创建 Iceberg表,你可以基于hive、hadoop和location_based_table类型的catalog创建Iceberg表,其中location_based_table可以看做hadoop类型的简化形式,并将外部HMS中的表通过外表的形式注册到当前HMS,从而实现Hive 的联邦查询,但是hive和hadoop类型的表在版本管理上略有不同,所以只能在同类型的catalog表上映射外表。另外,由于Hive 版本跨度较大,存在较多的不同版本的HMS兼容性问题,如HMS 3.x无法读取HMS 2.x的元数据等。
参考
https://iceberg.apache.org/docs/0.13.2/hive/
以上是关于使用Hive SQL查询Iceberg表的正确姿势的主要内容,如果未能解决你的问题,请参考以下文章