如何用Python处理小程序功能
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用Python处理小程序功能相关的知识,希望对你有一定的参考价值。
参考技术A 你好,下面是一个微信小程序自动回复的程序,希望可以帮助你。主要是利用itchat登录微信后,注册消息方法。itchat将根据接收到的消息类型寻找对应的已经注册的方法。如果一个消息类型没有对应的注册方法,该消息将会被舍弃。在这里我们主要注册的是文字类型的消息方法。然后判断消息来源,如果不是自己发出的消息,则将消息转发到文件助手,然后自动回复对方。代码如下:
# encoding = utf8
import itchat,time,re
from itchat.content import *
# 如果对方发的是文字,则我们给对方回复以下的东西
@itchat.msg_register([TEXT])
def text_reply(msg):
match = re.search('年',msg['Text'])
if match:
itchat.send(('那我就祝你狗年大吉大利,新的一年事事顺心'),msg['FromUserName'])
# 如果对方发送的是图片,音频,视频和分享的东西我们都做出以下回复。
@itchat.msg_register([PICTURE,RECORDING,VIDEO,SHARING])
def other_reply(msg):
itchat.send(('那我就祝你狗年大吉大利,新的一年事事顺心'),msg['FromUserName'])
itchat.auto_login(hotReload=True)
itchat.run()
如何用python爬取两个span之间的内容
Python用做数据处理还是相当不错的,如果你想要做爬虫,Python是很好的选择,它有很多已经写好的类包,只要调用,即可完成很多复杂的功能,此文中所有的功能都是基于BeautifulSoup这个包。
1 Pyhton获取网页的内容(也就是源代码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址所对应的源代码,urllib2是需要用到的包,以上三句代码就能获得网页的整个源代码
2 获取网页中想要的内容(先要获得网页源代码,再分析网页源代码,找所对应的标签,然后提取出标签中的内容)
2.1 以豆瓣电影排名为例子
网址是http://movie.douban.com/top250?format=text,进入网址后就出现如下的图
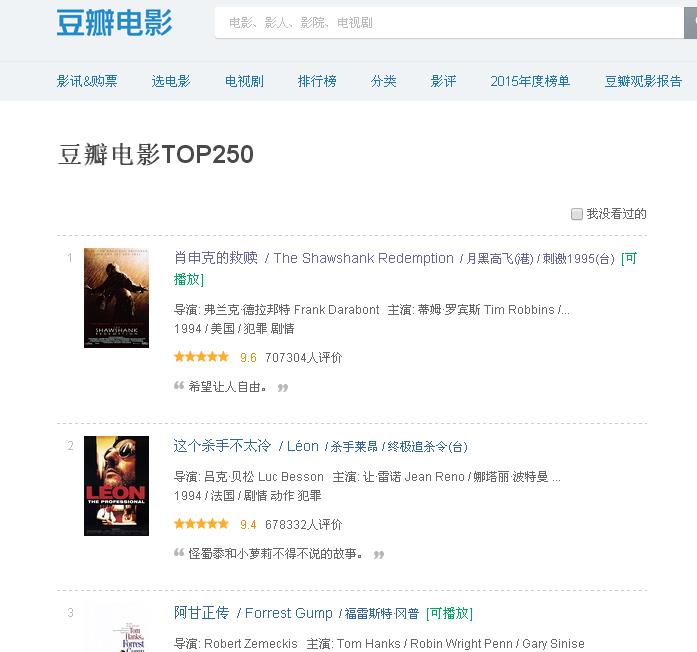
现在我需要获得当前页面的所有电影的名字,评分,评价人数,链接

由上图画红色圆圈的是我想得到的内容,画蓝色横线的为所对应的标签,这样就分析完了,现在就是写代码实现,Python提供了很多种方法去获得想要的内容,在此我使用BeautifulSoup来实现,非常的简单
控制台输出,你也可以写入文件中

前三行代码获得整个网页的源代码,之后开始使用BeautifulSoup进行标签分析,find_all方法是找到所有此标签的内容,然后在在此标签中继续寻找,如果标签有特殊的属性声明则一步就能找出来,如果没有特殊的属性声明就像此图中的评价人数前面的标签只有一个‘span’那么就找到所有的span标签,按顺序从中选相对应的,在此图中是第三个,所以这种方法可以找特定行或列的内容。代码比较简单,很容易就实现了,如果有什么地方不对,还请大家指出,大家共同学习。
源代码地址:http://download.csdn.net/detail/danielntz/9577390
转自:https://blog.csdn.net/danielntz/article/details/51861168
以上是关于如何用Python处理小程序功能的主要内容,如果未能解决你的问题,请参考以下文章