openGauss主备流程与参数的详细介绍
Posted 胖虎是只mao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了openGauss主备流程与参数的详细介绍相关的知识,希望对你有一定的参考价值。
一、openGauss主备
介绍openGauss的主备架构、如何修改事务提交方式(同步、异步)、解释了主备日志复制的相关GUC参数、以及对openGauss3.0新添加的CM工具进行了介绍。
注意点:
opengauss 是支持单机和一主多备部署方式。(不支持集群)
gaussdb支持集群。是分布式数据库。
1. 主备架构
openGauss的主备HA架构图如下。
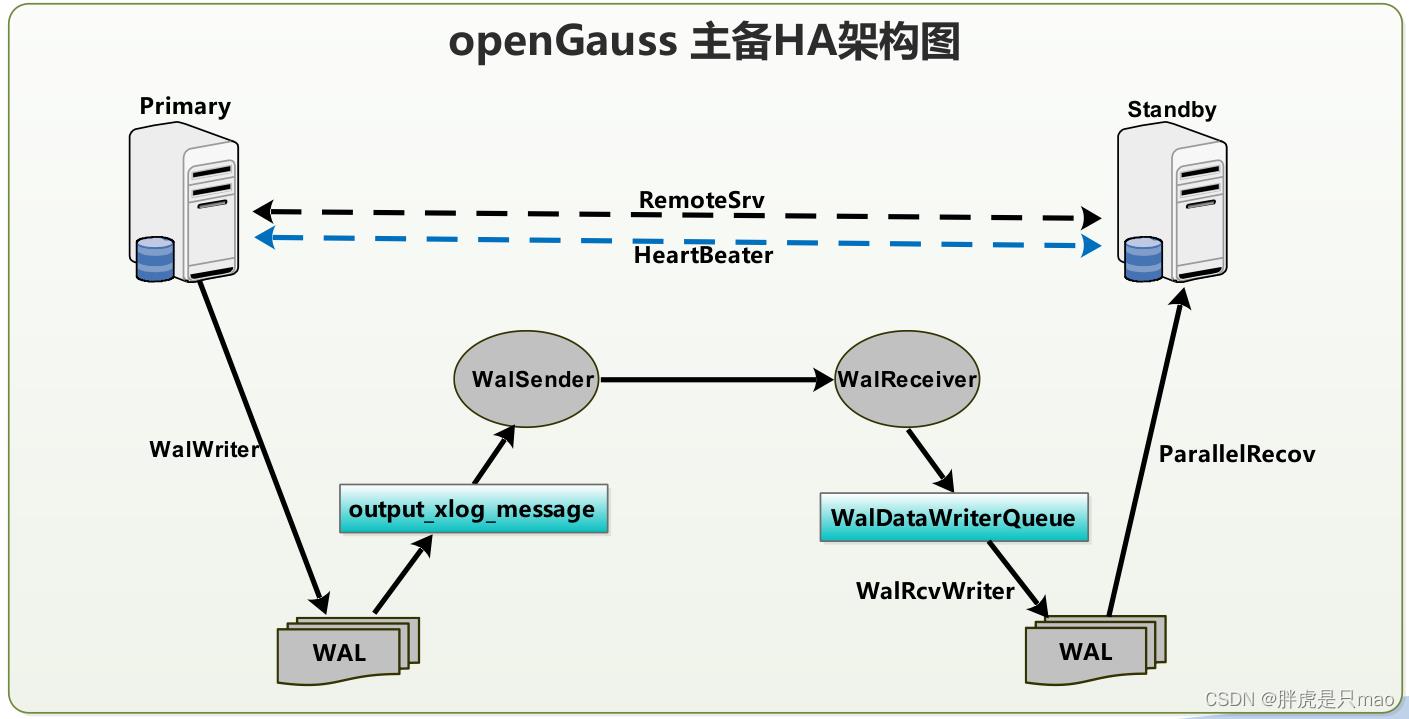
ParallelRecov:支持备机并行日志恢复
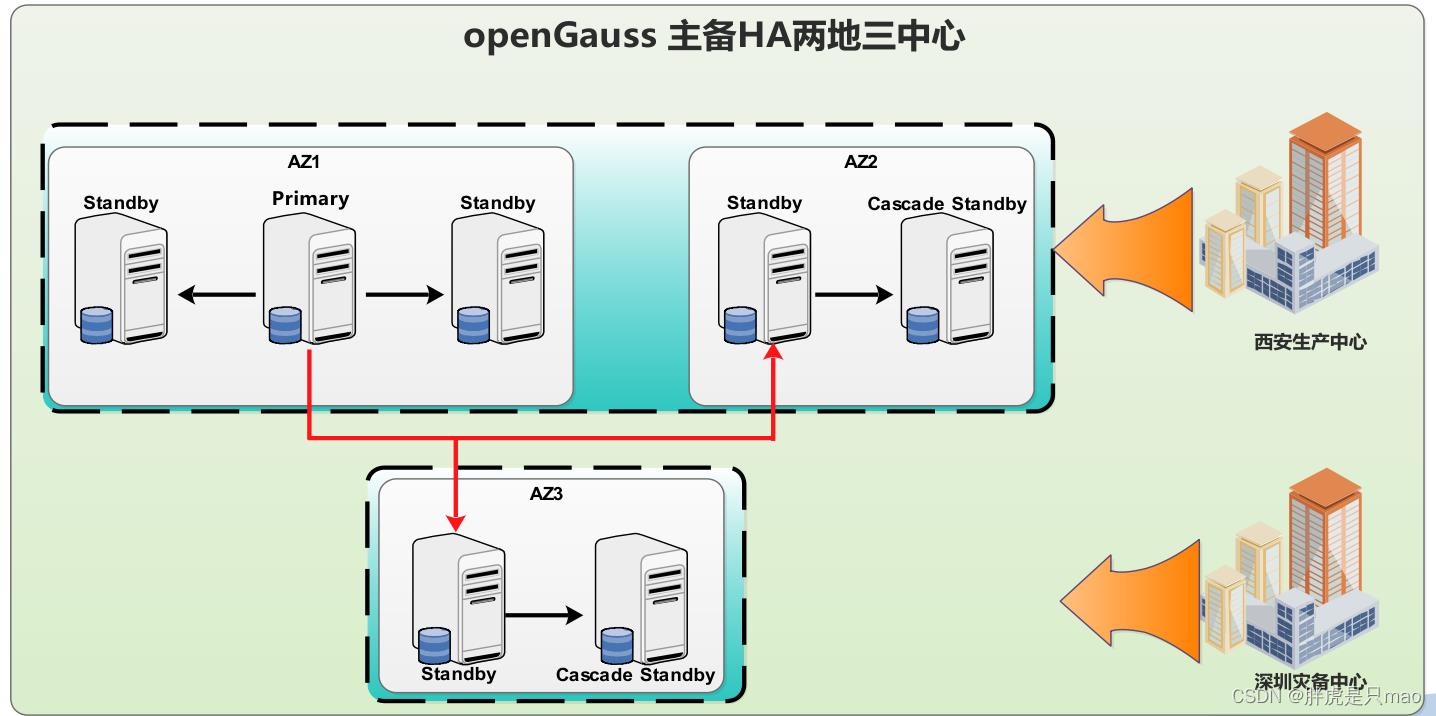
两地三中心的部署架构,如下图。
2. 术语解释
官方文档:https://opengauss.org/zh/docs/3.0.0/docs/Glossary/Glossary.html
AZ:Available Zone,通常指一个机房。
HA:高可用性(HighAvailability),通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性。
CM: Cluster Manager,数据库管理模块。管理和监控系统中各个功能单元和物理资源的运行情况,确保整个系统的稳定运行。
OM: Operations Management,运维管理模块。提供数据库日常运维、配置管理的管理接口、工具。
core文件: 当程序出现内存越界、断言失败或者访问非法内存时,操作系统会中止进程,并将当前内存状态导出到core文件中,以便进一步分析。(欧拉22.03自带的数据库,进行多节点部署的时候就遇到过,只支持集群部署)
core文件包含内存转储,支持全二进制和指定端口格式。core文件名称由字符串core以及操作系统进程ID组成。
core文件不依赖于任何平台。
检查点:将数据库内存中某一时刻的数据存到磁盘的机制。openGauss定期将已提交的事务数据和未提交的事务数据存到磁盘,这些数据用来和Redo日志一起在数据库重启和崩溃时恢复数据库。
节点: 将构成openGauss数据库环境的各台服务器(物理机或虚拟机)称为数据库节点,简称节点。
基于时间点恢复: PITR(Point-In-TIme Recovery),基于时间点恢复是openGauss备份恢复的一个特性,是指在备份数据和WAL日志正常的情况下,数据可以恢复到指定时间点。
逻辑复制: 数据库主备或两个数据库间的数据同步方式。区别于通过物理日志回放方式的物理复制,逻辑复制在两个数据库间传输逻辑日志或通过逻辑日志对应的SQL语句实现数据同步。
逻辑日志::数据库修改的日志记录,可直接对应为SQL语句,一般为行级记录。区别于物理日志,物理日志是记录物理页面修改的日志。
逻辑解码: 逻辑解码是一种通过对xlog日志的反解实现将数据库表的所有持久更改抽取到一种清晰、易于理解的格式的处理过程。
逻辑复制槽: 在逻辑复制的环境下,逻辑复制槽用以防止Xlog被系统或Vaccum回收。openGauss中用于记录逻辑解码位置的对象,提供创建、删除、读取、推进等多个SQL接口函数。
逻辑节点: 一个物理节点上可以安装多个逻辑节点。一个逻辑节点是一个数据库实例。
强一致性: 任何查询不会瞬时的看到一个事务的中间状态。
全量同步: openGauss双机方案中的一种数据同步机制,是指把主机中的所有数据同步给备机。
增量备份: 基于上次有效备份之后对文件修改的备份。
增量同步: openGauss双机方案中的一种数据同步机制,是指把主机中数据增量同步给备机,即只同步主备间有差异的数据。
数据库实例: 一个数据库实例是一个openGauss进程以及它控制的数据库文件。openGauss在一个物理节点上安装多个数据库实例。一个数据库实例也被称为一个逻辑节点。
数据库双机: openGauss提供的高可靠性双机方案。在此方案中,每个openGauss逻辑节点标识为主机或备机。在同一时间内,只有一个openGauss被标识为主机。双机初次建立时,主机会对每个备机数据做全量同步,然后做增量同步。双机建立之后的运行过程中,主机能接受数据读和写的操作请求,备机只做日志同步。
主机: openGauss数据库双机系统中接受数据读写操作的节点,和所有备机一起协同工作。在同一时间内,双机系统中只有一个节点被标识为主机。
物理节点: 一个物理机器称为一个物理节点。
系统表: 存储数据库元信息的表,元信息包括数据库中的用户表、索引、列、函数和数据类型等。
脏页面: 已经被修改且未写入持久性设备的页面。
最小恢复点:最小恢复点是openGauss提供的数据一致性保障手段之一。最小恢复点特性可以在openGauss启动时检查出WAL日志和持久化到磁盘的数据的不一致性,并提示用户进行处理。
Failover:指当某个节点出现故障时,自动切换到备节点上的过程。反之,从备节点上切换回来的过程称为Failback。
REDO日志: 记录对数据库进行操作的日志,这些日志包含重新执行这些操作所需要的信息。当数据库故障时,可以利用REDO日志将数据库恢复到故障前的状态。
Postmaster:数据库服务启动时启动的一个线程。用于侦听来自数据库其它节点或客户端的连接请求。主机上侦听到备机连接请求,并接受后,就会创建一个WAL Sender线程,用于处理与备机的交互。
WAL:Write-Ahead Logging,也称为 XLog,预写日志系统。实现事务日志的标准方法,是指对数据文件(表和索引的载体)持久化修改之前必须先持久化相应的日志。
WAL Receiver:数据库复制时备机创建的一个线程的名称。此线程用于从主机接收数据、命令,并反馈确认信息至主机。一个备机只有一个WALReceiver线程。
WAL Sender:数据库复制过程中,主机接受到备机的连接请求后创建的一个线程的名称。此线程用于发送命令、数据到备机,并从备机接收信息。一个主机可能会有多个WAL Sender线程,每一个WAL Sender线程对应一个备机的一个连接请求。
WAL Writer: 数据库启动时创建的一个写Redo日志的线程,用于将内存中的日志写入到持久性设备(如:磁盘)。
Xlog: 表示事务日志,一个逻辑节点中只有一个,不允许创建多个Xlog文件。
核心流程:
目前一主多备方式架构,主机通过walsender线程向备机同步日志,备机通过walreceiver线程接受日志,并刷到本地盘,备机读取redo日志,完成主备之间的数据同步。主备机之间walsender与walreceiver一一对应。
3. 事务提交方式(主备日志同步方式)
通常情况下,一个事务产生的日志的同步顺序如下:
1. 主机将日志内容写入本地内存。
2. 主机将本地内存中的日志写入本地文件系统。
3. 主机将本地文件系统中的日志内容刷盘。
4. 主机将日志内容发送给备机。
5. 备机接受到日志内容,存入备机内存。
6. 备机将备机内存中的日志写入备机文件系统。
7. 备机将备机文件系统中的日志内容刷盘。
8. 备机回放日志,完成对数据文件的增量更新。
事务提交方式由参数synchronous_commit决定,共有6种提交方式,如下:
- on:表示主机事务提交需要等待备机将对应日志刷新到磁盘。
- off:表示主机事务提交无需等待主机自身将对应日志刷新到磁盘,通常也称为异步提交。
- local:表示主机事务提交需要等待主机自身将对应日志刷新到磁盘,通常也称为本地提交。
- remote_write:表示主机事务提交需要等待备机将对应日志写到文件系统(无需刷新到磁盘)
- remote_receive:表示主机事务提交需要等待备机接收到对应日志数据(无需写入文件系统)
- remote_apply:表示主机事务提交需要等待备机完成对应日志的回放操作。
默认值:on
上述6种提交方式中,off和local属于非同步提交,其他均为同步提交。
下面给出on和local两种方式的事务提交时序图。
1、synchronous_commit = on(默认值)
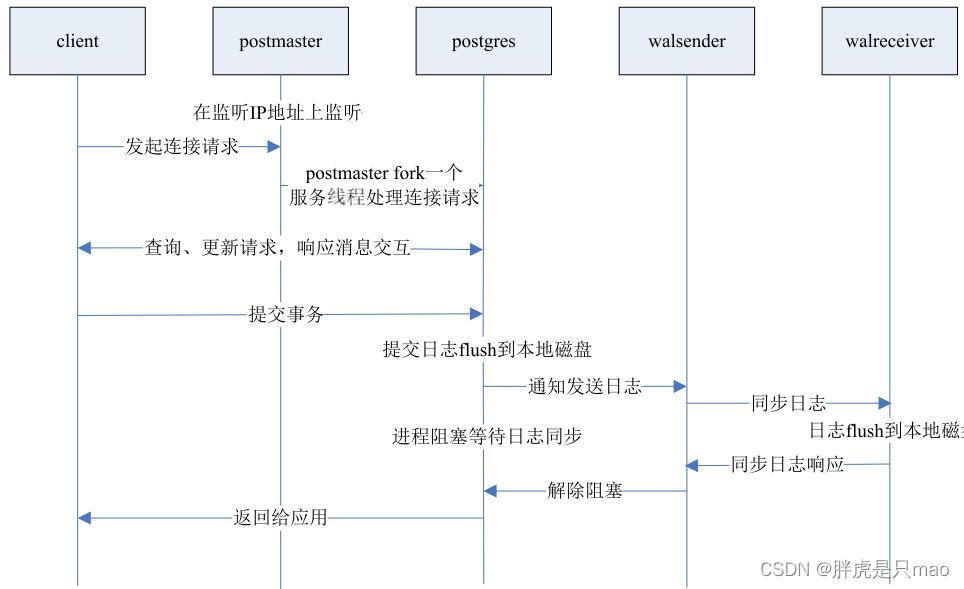
该方式有性能损耗,可靠性高。
2、synchronous_commit = local
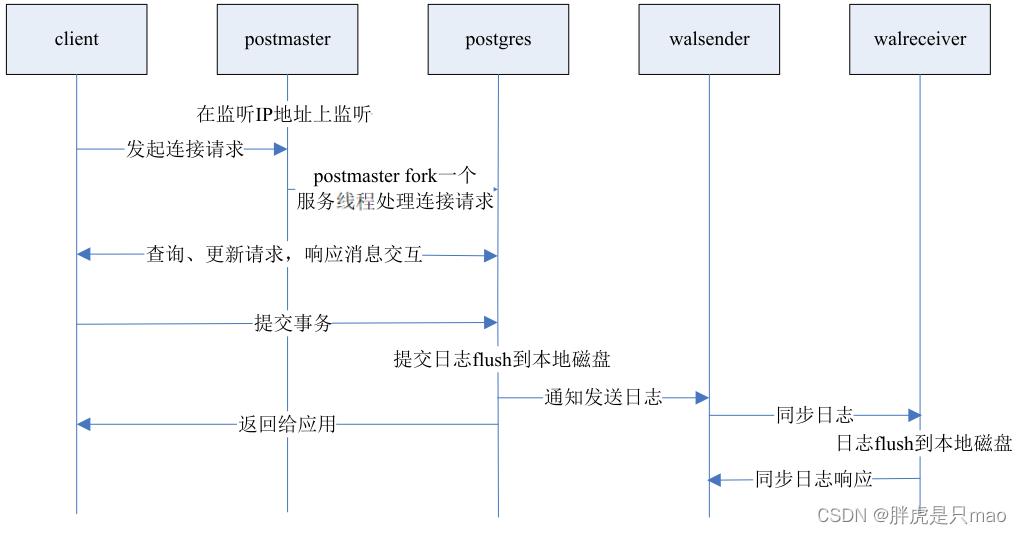
该方式性能高,可靠性差。
4. 主备日志复制的相关GUC参数
GUC: Grand Unified Configuration,数据库运行参数。配置这些参数可以影响数据库系统的行为。
更多GUC参数可查看:GUC参数说明
修改GUC参数的方法:重设GUC参数
1、wal_writer_delay
参数说明: WalWriter进程的写间隔时间。如果时间过长可能造成WAL缓冲区的内存不足,时间过短会引起WAL不断写入,增加磁盘I/O负担。
取值范围:整型, 1~10000(毫秒)
默认值: 200ms
2、checkpoint_segments
**参数说明:**设置checkpoint_timeout周期内所保留的最少WAL日志段文件数量。每个日志文件大小为16MB。
取值范围:整型,最小值1
提升此参数可加快大数据的导入速度,但需要结合checkpoint_timeout、shared_buffers这两个参数统一考虑。这个参数同时影响WAL日志段文件复用数量,通常情况下pg_xlog文件夹下最大的复用文件个数为2倍的checkpoint_segments个,复用的文件被改名为后续即将使用的WAL日志段文件,不会被真正删除。
默认值: 64
shared_buffers
参数说明: 设置openGauss使用的共享内存大小。增加此参数的值会使openGauss比系统默认设置需要更多的System V共享内存。
默认值: 8MB
3、checkpoint_timeout
参数说明: 设置自动WAL检查点之间的最长时间。
取值范围:整型, 30~3600(秒)
在提升checkpoint_segments以加快大数据导入的场景也需将此参数调大,同时这两个参数提升会加大shared_buffers的负担,需要综合考虑。
默认值: 15min
4、max_redo_log_size
参数说明: 备DN表示当前回放的最新检查点位置和当前日志回放位置之间日志量的期望值,主DN表示恢复点到当前最新日志之间日志量的期望值,关注RTO的情况下,这个值建议不宜过大。
取值范围:整型,163840~2147483647,单位为KB
默认值: 1GB
5、recovery_max_workers
参数说明: 设置最大并行回放线程个数。
取值范围:整型,0~20
默认值: 1(安装工具默认设置为4,以获得更好地性能)
6、max_wal_senders
参数说明: 指定事务日志发送进程的并发连接最大数量。不可大于等于max_connections。
wal_level必须设置为archive、hot_standby或者logical以允许备机的连接。
取值范围:整型,0 ~ 1024(建议取值范围:8 ~ 100)
默认值: 16
7、wal_keep_segments
参数说明: Xlog日志文件段数量。设置“pg_xlog”目录下保留事务日志文件的最小数目,备机通过获取主机的日志进行流复制。
**取值范围:**整型,2 ~ INT_MAX
默认值: 16
设置建议:
- 当服务器开启日志归档或者从检查点恢复时,保留的日志文件数量可能大于wal_keep_segments设定的值。
- 如果此参数设置过小,则在备机请求事务日志时,此事务日志可能已经被产生的新事务日志覆盖,导致请求失败,主备关系断开。
- 当双机为异步传输时,以COPY方式连续导入4G以上数据需要增大wal_keep_segments配置。以T6000单板为例,如果导入数据量为50G,建议调整参数为1000。您可以在导入完成并且日志同步正常后,动态恢复此参数设置。
- 若synchronous_commit级别小于LOCAL_FLUSH,重建备机时,建议调大改参数为1000,避免重建过程中,主机日志回收导致重建失败。
个人思考:1)被产生的新事务日志覆盖、2)主机日志回收,这两个关键语句,意味着主机的WAL日志已经被覆盖了,丢失了旧的数据,如果此时有备机要重建,读取主机WAL日志进行回放,就会丢失数据,与主机数据不一致!因此,我觉得这个参数决定了在备机故障断连的情况下,主机的WAL日志的保存上限。
5. CM
5.1 CM是什么?
CM,即Cluster Manager,数据库管理模块。管理和监控系统中各个功能单元和物理资源的运行情况,确保整个系统的稳定运行。
5.2 CM 能做什么?
5.2.1 CM的架构及核心组件
CM 提供了丰富的集群管理能力,如集群、节点、实例级的启停,集群状态查询、选主、主备切换、日志管理等。
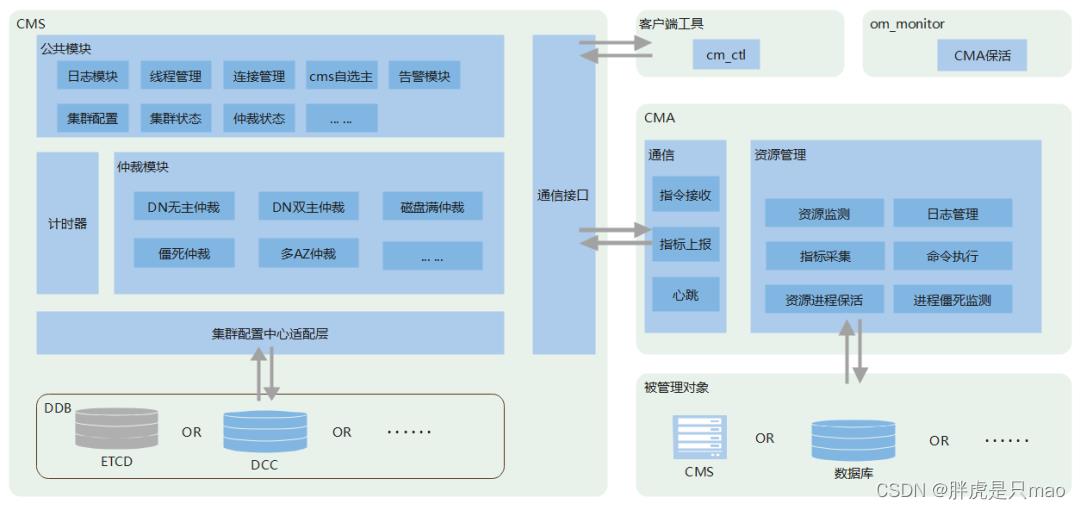
CM 架构图如上所示,组件包括 4 个可执行文件:
cm_server:(cms)cm 的服务端,负责收集 cma 上报的状态,并作为仲裁中心和全局配置中心,集群能否稳定运行以及在发生单点故障后,备实例能否正常切换为主来保证集群的可用性,都与 CMS 是否稳定相关。
cm_agent:(cma)通常集群中的每台机器都安装一个,负责管理本节点所有实例的状态检测和上报以及 cms下发命令的执行。
om_monitor:通常集群中的每台机器都安装一个,负责保障本节点 cm_agent 进程的健康。
cm_ctl:cm 的客户端工具,提供集群管理操作。
5.2.2 进程监控
cm 接管集群后,会周期性的对集群中的所有进程 (包括 cma,cms,openGauss 等进程) 进行探测监控,负责集群进程的保活及僵死恢复。
5.2.3 数据库状态采集
cma 会周期性的采集 openGauss 数据库的运行状态,采集指标包括主备状态,日志位置及回放速率,日志发送接收进度等信息,并汇总在 cms,这些信息将被用于选主仲裁及工具展示。
5.2.4 日志压缩
cma 提供了日志管理能力,通过日志文件总大小,日志文件数量,日志时间等维度对日志目录进行监控,自动归档,清理日志。
5.2.5 可靠的选主仲裁
当数据库主机发生不可恢复的故障而无法继续提供服务时,集群管理会感知并基于 qurom 协议,进行选主仲裁。CM 的仲裁都是使用的状态机模式,依据当前数据库状态进行仲裁逻辑的推进。
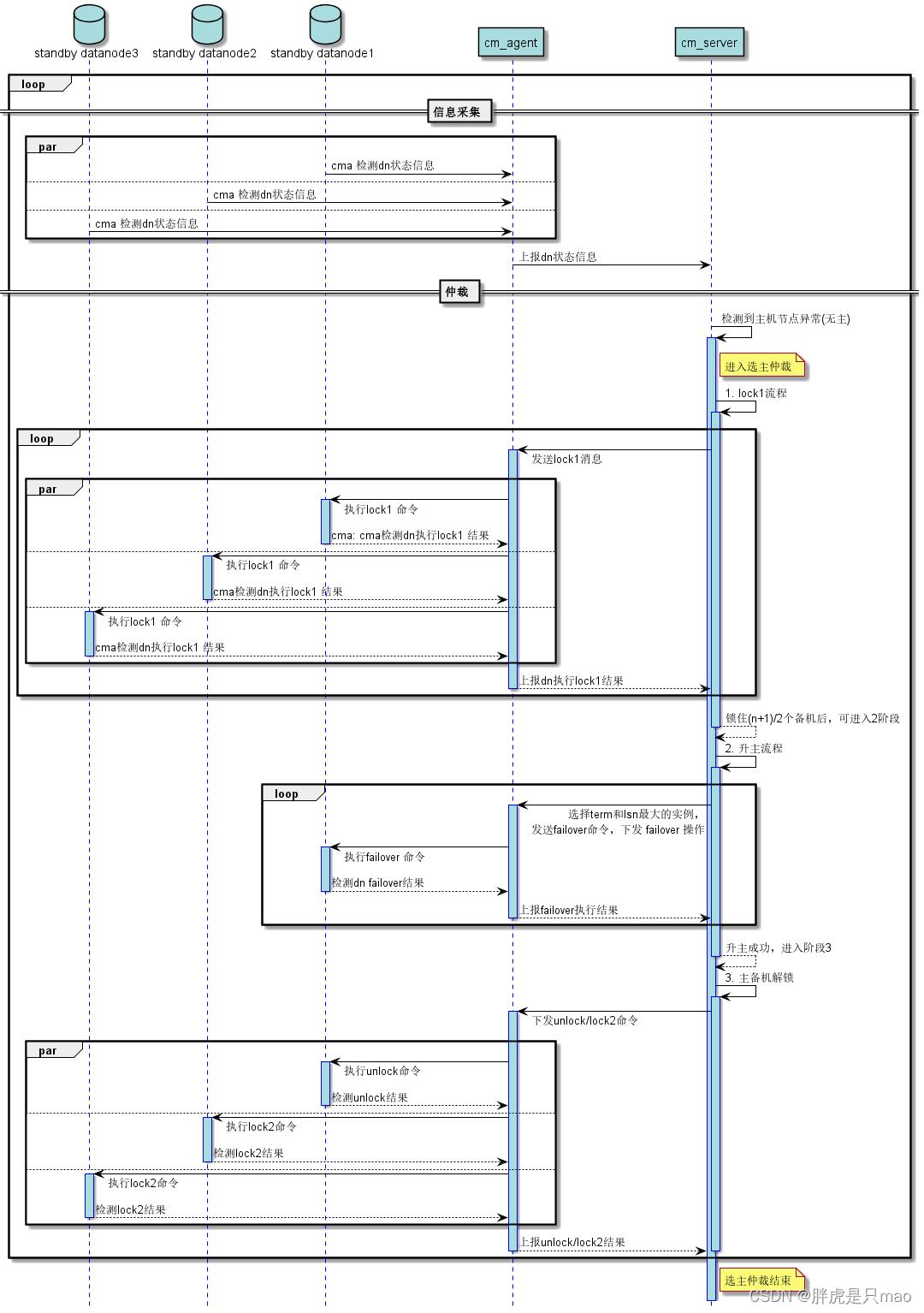
以上是 CMS 选主仲裁的时序图,总体流程包含上报和仲裁两大部分 (仲裁命令实际实时都是通过信息上报获取的,图中返回结果只是为了方便理解)。
信息采集上报:
每个数据库实例的状态都会被 cma 定时采集并上报 cms。
选主仲裁:
cms 周期性的检测数据库的主备状态,如果发现主机不能够正常提供服务,则会触发选主仲裁。
1. 状态: 无主。
操作: 给所有备机发送命令,使其进入 LOCK1 状态。
说明: 如果备机此时连接主机,则 lock1 不会成功。Lock1 状态成功主要有两个条件:
1)备机与主机复制链路永久断开且不再主动重连。
2)备机日志全部回放结束,不再增加。
2. 状态:(n+1)/2 个备机已经进入 LOCK1 状态。
操作: 选合适的主,发送 failover
说明: 根据 qurom 的特点,当 (n+1)/2 个备机进入 LOCK1 状态后,这几个备机中一定有至少 1 个同步备,cms 从这几个备机中找到日志最多的节点 (一定是同步备),发送升主命令。如果有多个满足条件的备机,则按照以下策略:
a) 原主能起来,则选原主
b) 选择与原主同 AZ 的
c) 按节点顺序
3. 状态: 新主升主成功。
操作: 给主备机发送 unlock/lock2 消息,恢复成正常状态
说明: 果主机处于 lock1 状态,则给主机发送 unlock 消息使其退出 lock1 状态,如果备机处于 lock1 状态,则给备机发送 lock2 消息,指定新主 ip,使其连接新主。
通过以上逻辑,CM 保证了集群永远只有一个可写主机,且 RPO=0。
5.3 CM 集群的安装说明
在安装带 CM 的 openGauss 之前,需要创建 clusterconfig.xml 配置文件。XML 文件包含部署 openGauss+CM 的服务器信息、安装路径、IP 地址以及端口号等。用于告知 openGauss、CM 如何部署。用户需根据不同场配置对应的 XML 文件,带 CM 的安装,除安装配置文件需要添加 CM 外,其余步骤与 openGauss 安装完全相同。
下面以一主二备的部署方案为例,说明如何创建带 CM 的 openGauss 集群 XML 配置文件。
集群安装 xml 样例
<?xml version="1.0" encoding="UTF-8"?>
<ROOT>
<!-- openGauss整体信息 -->
<CLUSTER>
<PARAM name="clusterName" value="Cluster_template" />
<PARAM name="nodeNames" value="node1_hostname,node2_hostname,node3_hostname" />
<PARAM name="gaussdbAppPath" value="/opt/huawei/install/app" />
<PARAM name="gaussdbLogPath" value="/var/log/omm" />
<PARAM name="tmpMppdbPath" value="/opt/huawei/tmp"/>
<PARAM name="gaussdbToolPath" value="/opt/huawei/install/om" />
<PARAM name="corePath" value="/opt/huawei/corefile"/>
<PARAM name="backIp1s" value="192.168.0.1,192.168.0.2,192.168.0.3"/>
</CLUSTER>
<!-- 每台服务器上的节点部署信息 -->
<DEVICELIST>
<!-- node1上的节点部署信息 -->
<DEVICE sn="node1_hostname">
<PARAM name="name" value="node1_hostname"/>
<PARAM name="azName" value="AZ1"/>
<PARAM name="azPriority" value="1"/>
<!-- 如果服务器只有一个网卡可用,将backIP1和sshIP1配置成同一个IP -->
<PARAM name="backIp1" value="192.168.0.1"/>
<PARAM name="sshIp1" value="192.168.0.1"/>
<!--CM节点部署信息-->
<PARAM name="cmsNum" value="1"/>
<PARAM name="cmServerPortBase" value="15000"/>
<!--CM Server用于侦听CM Agent连接请求或DBA管理请求的IP地址-->
<PARAM name="cmServerListenIp1" value="192.168.0.1,192.168.0.2,192.168.0.3"/>
<PARAM name="cmServerHaIp1" value="192.168.0.1,192.168.0.2,192.168.0.3"/>
<!-- cmServerlevel目前只支持1 -->
<PARAM name="cmServerlevel" value="1"/>
<PARAM name="cmServerRelation" value="node1_hostname,node2_hostname,node3_hostname"/>
<PARAM name="cmDir" value="/opt/huawei/data/cmserver"/>
<!--dn-->
<PARAM name="dataNum" value="1"/>
<PARAM name="dataPortBase" value="15400"/>
<PARAM name="dataNode1" value="/opt/huawei/install/data/dn,node2_hostname,/opt/huawei/install/data/dn,node3_hostname,/opt/huawei/install/data/dn"/>
<PARAM name="dataNode1_syncNum" value="0"/>
</DEVICE>
<!-- node2上的节点部署信息,其中“name”的值配置为主机名称 -->
<DEVICE sn="node2_hostname">
<PARAM name="name" value="node2_hostname"/>
<PARAM name="azName" value="AZ1"/>
<PARAM name="azPriority" value="1"/>
<!-- 如果服务器只有一个网卡可用,将backIP1和sshIP1配置成同一个IP -->
<PARAM name="backIp1" value="192.168.0.2"/>
<PARAM name="sshIp1" value="192.168.0.2"/>
<!-- cm -->
<PARAM name="cmServerPortStandby" value="15000"/>
<PARAM name="cmDir" value="/opt/huawei/data/cmserver"/>
</DEVICE>
<!-- node3上的节点部署信息,其中“name”的值配置为主机名称 -->
<DEVICE sn="node3_hostname">
<PARAM name="name" value="node3_hostname"/>
<PARAM name="azName" value="AZ1"/>
<PARAM name="azPriority" value="1"/>
<!-- 如果服务器只有一个网卡可用,将backIP1和sshIP1配置成同一个IP -->
<PARAM name="backIp1" value="192.168.0.3"/>
<PARAM name="sshIp1" value="192.168.0.3"/>
<!-- cm -->
<PARAM name="cmServerPortStandby" value="15000"/>
<PARAM name="cmDir" value="/opt/huawei/data/cmserver"/>
</DEVICE>
</DEVICELIST>
</ROOT>
部分参数说明如下表: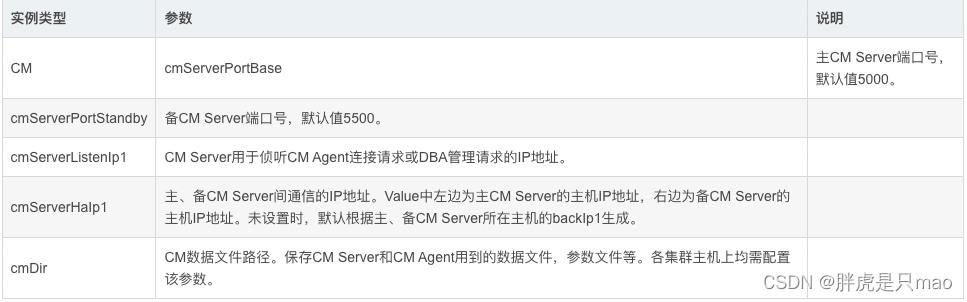
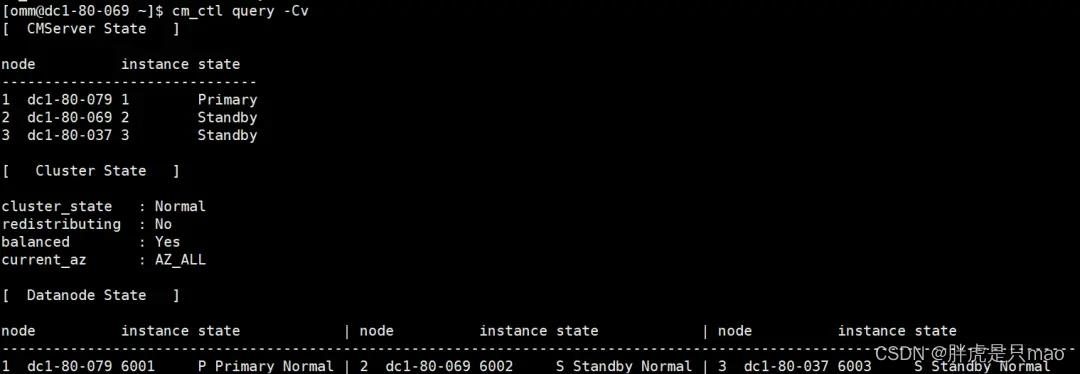
CMServer State :cm 的状态信息。
node:节点号和节点名称。
instance:表示 instanceId(此 id 为集群内的概念,每个集群中的实例都会拥有一个独一无二的 instanceId,用来标识此实例)。
state:cm 的角色信息,primary 表示主,standby 表示备,unknown 表示无法获取到 cm 的角色信息(一般故障场景才会出现 unknown)。
Cluster State:集群相关状态信息。
cluster_state:集群状态,一共有三种状态:Normal,表示数据库正常;Degraded,表示数据库可用,但有某个数据节点存在异常;Unavailable,表示数据库不可用。
Datanode State:数据库各个实例的信息。
node:数据库实例所在节点的节点号和节点名称。
instance:表示 instanceId(此 id 为集群内的概念,每个集群中的实例都会拥有一个独一无二的 instanceId,用来标识此实例)。
state:数据库实例的状态信息,由三个具体的信息注册:第一个字段 P/S 表示初始的角色信息,P 为主,S 为备;第二个字段为角色信息;第三个字段为数据库具体的状态。
至此,一个由 CM 管理的一主两备 openGauss 集群就部署好了,后续就可以用过 CM 提供的工具对集群做一些基本的运维操作。
CM 操作命令:
cm_ctl stop // 停止整个集群
cm_ctl query -Cv // 查询状态
cm_ctl start // 启动整个集群
#停止节点1上的数据库实例,-n后面指定节点号,-D后面指定数据库实例的数据目录。
cm_ctl stop -n 1 -D /home/omm/cluster/data/dn1
#启动节点1上的数据库实例,-n后面跟节点号,-D后面跟数据库实例的数据目录。
cm_ctl start -n 1 -D /home/omm/cluster/data/dn1
主备切换
#-n参数后面跟的是需要升主的数据节点的节点id,-D后面跟的是数据目录(可参考前面步骤获得数据目录)
cm_ctl switchover -n 3 -D /home/omm/cluster/data/dn3
恢复成初始主备关系
cm_ctl switchover -a


CM 集群部分高可用能力
CM 支持数据库进程保活,备机故障后自动主备切换,备机日志损坏后的自动重建等高可用能力。
自动恢复数据库实例演示
在节点 1(node1)上,故障注入
查看数据库进程id,并kill掉数据库进程
ps -ux
kill -9 [pid]
以上是关于openGauss主备流程与参数的详细介绍的主要内容,如果未能解决你的问题,请参考以下文章