“反爬虫”与“反反爬虫”
Posted FANCY PANDA
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了“反爬虫”与“反反爬虫”相关的知识,希望对你有一定的参考价值。
反爬虫:
- 不返回网页:如不返回内容和延迟网页返回时间
- 返回数据非目标网页:如返回错误页、返回空白页和爬取多页时均返回同一页
- 增加获取数据的难度,:如登陆才可查看和登陆时设置验证码
不返回网页
爬虫发送请求给相应的网站地址后,网站返回404页面,表示服务器无法正常提供信息或服务器无法回应;
网站也可能长时间不返回数据,这意味着爬虫已经进行了封杀
-
网站通过IP访问量反爬虫
如果单个IP的访问量超过了某个阈值,就会进行封杀或要求输入验证码。 -
网站通过session访问量反爬虫
session对象存储特定用户会话所需的属性和配置信息;当用户在应用程序的web页面之间跳转时,存储在session对象中的变量将不会丢失,而是整个用户会话中一直存在下去。如果一个session的访问量过大,就会进行封杀或要求输入验证码。 -
网站通过User-Agent反爬虫
User-Agent表示浏览器在发送请求时,附带当前浏览器和当前系统环境的参数给服务器。
返回数据非目标网页
- 爬取页面数据时返回的是错误信息或者是同一页的信息
- 页面上的数据信息可以和html源码不一样,爬取下来的数字和真实的数字会不一样
- 也可能呈现的部分文字和数字会用SVG矢量图来进行替代,用不同的偏移量显示不同的字符,导致会漏掉很多信息
增加获取数据的难度
网站可以通过增加获取数据的难度反爬虫,一般需要登陆后才能获得数据,而且还会设置验证码。
反反爬虫:
修改请求头
对于User-Agent反爬虫方式,我们可以修改请求头,从而实现顺利获取网页的目的


修改爬虫的间隔时间
爬虫运行的太过频繁会容易被反爬虫,所以我们要在两次访问之间设置一个间隔时间
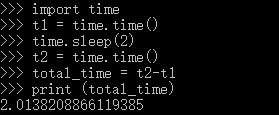
但是如果使用一个固定的数字作为时间间隔,也可能被判断出是爬虫行为,因为真正的用户是不会出现如此精准的秒数间隔,所以,我们可以使用一个random()函数,让时间可以在一个较短的间隔内进行随机获取
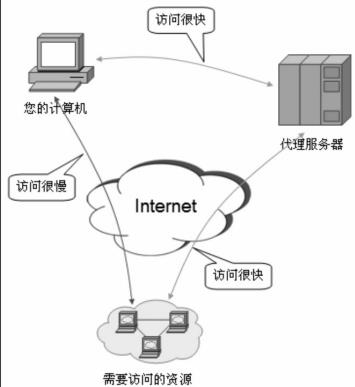
使用代理
代理(Proxy)是一种特殊的网络服务,允许一个网络终端通过这个服务与另一个网络终端进行非直接的连接。
import requests
link = "http://www.baidu.com/"
proxies = 'http':'http://xxx.xxx.xxx.xxx:xxxx'
response = requests.get(link, proxies=proxies)
更换IP地址
- 通过动态IP拨号服务器更换IP
- 是通过Tor代理服务器的方法
以上是关于“反爬虫”与“反反爬虫”的主要内容,如果未能解决你的问题,请参考以下文章