驳狗屎文 "我为啥放弃Go语言
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了驳狗屎文 "我为啥放弃Go语言相关的知识,希望对你有一定的参考价值。
此篇文章流传甚广, 其实里面没啥干货, 而且里面很多观点是有问题的. 这个文章在 golang-china 很早就讨论过了.最近因为 Rust 1.0 和 1.1 的发布, 导致这个文章又出来毒害读者.
所以写了这篇反驳文章, 指出其中的问题.
有好几次,当我想起来的时候,总是会问自己:我为什么要放弃Go语言?这个决定是正确的吗?是明智和理性的吗?其实我一直在认真思考这个问题。
开门见山地说,我当初放弃Go语言(golang),就是因为两个“不爽”:第一,对Go语言本身不爽;第二,对Go语言社区里的某些人不爽。毫无疑问,这是非常主观的结论。但是我有足够详实的客观的论据,用以支撑这个看似主观的结论。
文末附有本文更新日志。
确实是非常主观的结论, 因为里面有不少有问题的观点(用来忽悠Go小白还行).
第0节:我的Go语言经历
先说说我的经历吧,以避免被无缘无故地当作Go语言的低级黑。
2009年底,Go语言(golang)第一个公开版本发布,笼罩着“Google公司制造”的光环,吸引了许多慕名而来的尝鲜者,我(Liigo)也身居其中,笼统的看了一些Go语言的资料,学习了基础的教程,因对其语法中的分号和花括号不满,很快就遗忘掉了,没拿它当一回事。
在2009年Go刚发布时, 确实是因为“Google公司制造”的光环而吸引了(包括文章作者和诸多IT记者)很多低级的尝鲜者.
还好, 经过5年的发展, 这些纯粹因为光环来的投机者所剩已经不多了(Google趋势).
目前, 真正的Go用户早就将Go用于实际的生产了.
说到 其语法中的分号和花括号不满, 我想说这只是你的 个人主观感受, 还有很多人对Go的分号和花括号很满意,
包括水果公司的的 Swift 的语言设计者也很满意这种风格(Swift中的分号和花括号和Go基本相同).
如果只谈 个人主观感受, 我也可以说 Rust 的 fn 缩写也很蛋疼!
两年之后,2011年底,Go语言发布1.0的计划被提上日程,相关的报道又多起来,我再次关注它,重新评估之后决定深入参与Go语言。我订阅了其users、nuts、dev、commits等官方邮件组,坚持每天阅读其中的电子邮件,以及开发者提交的每一次源代码更新,给Go提交了许多改进意见,甚至包括修改Go语言编译器源代码直接参与开发任务。如此持续了数月时间。
这个到是事实, 在 golang-china 有不少吵架的帖子, 感兴趣的可以去挖下, 我就不展开说了.
到2012年初,Go 1.0发布,语言和标准库都已经基本定型,不可能再有大幅改进,我对Go语言未能在1.0定型之前更上一个台阶、实现自我突破,甚至带着诸多明显缺陷走向1.0,感到非常失望,因而逐渐疏远了它(所以Go 1.0之后的事情我很少关心)。后来看到即将发布的Go 1.1的Release Note,发现语言层面没有太大改变,只是在库和工具层面有所修补和改进,感到它尚在幼年就失去成长的动力,越发失望。外加Go语言社区里的某些人,其中也包括Google公司负责开发Go语言的某些人,其态度、言行,让我极度厌恶,促使我决绝地离弃Go语言。
真的不清楚楼主说的可以在 Go1.0 之前短时间内能实现的 重大改进和诸多明显缺陷 是什么.
如果是楼主说前面的 其语法中的分号和花括号不满 之类的重大改进, 我只能说这只是你的 个人主观感受 而已,
你的很多想法只能说服你自己, 没办法说服其他绝大部分人(不要以为像C++或Rust那样什么特性都有就NB了, 各种NB特性加到一起只能是 要你命3000, 而绝对不会是什么 银弹).
Go 1.1的Release Note,发现语言层面没有太大改变. 语言层没有改变是是因为 Go1 作出的向后兼容的承诺. 对于工业级的语言来说, Go1 这个只能是优点. 如果连语言层在每个版本都会出现诸多大幅改进, 那谁还敢用Go语言来做生产开发呢(我承认Rust的改动很大胆, 但也说明了Rust还处于比较幼稚和任性的阶段)?
说 Go语言社区里的某些人固执 的观点我是同意的. 但是这些 固执 的人是可以讲道理的, 但是他们对很多东西的要求很高(特别是关于Go的设计哲学部分).
只要你给的建议有依据(语言的设计哲学是另外一回事情), 他们绝对不会盲目的拒绝(只是讨论的周期会比较长).
关于楼主提交的给Go文件添加BOM的文章, 需要补充说明下.
在Go1.0发布的时候, Go语言的源文件(.go)明确要求必须是UTF8编码的, 而且是无BOM的UTF8编码的.
注意: 这个 无BOM的UTF8编码 的限制仅仅是 针对 Go语言的源文件(.go).
这个限制并不是说不允许用户处理带BOM的UTF8的txt文件!
我觉得对于写Go程序来说, 这个限制是没有任何问题的, 到目前为止, 我还从来没有使用过带BOM的.go文件.
不仅是因为带BOM的.go文件没有太多的意义, 而且有很多的缺陷.
BOM的原意是用来表示编码是大端还是小端的, 主要用于UTF16和UTF32. 对于 UTF8 来说, BOM 没有任何存在的意义(正是Go的2个作者发明了UTF8, 彻底解决了全球的编码问题).
但是, 在现实中, 因为MS的txt记事本, 对于中文环境会将txt(甚至是C/C++源文件)当作GBK编码(GBK是个烂编码),
为了区别到底是GBK还是UTF8, MS的记事本在前面加了BOM这个垃圾(被GBK占了茅坑), 这里的bom已经不是表示字节序本意了. 不知道有没有人用ms的记事本写网页, 然后生成一个带bom的utf8网页肯定很有意思.
这是MS的记事本的BUG: 它不支持生成无BOM的UTF8编码的文本文件!
这些是现实存在的带BOM的UTF8编码的文本文件, 但是它们肯定都不是Go语言源文件!
所以说, Go语言的源文件即使强制限制了无BOM的UTF8编码要求, 也是没有任何问题的(而且我还希望有这个限制).
虽然后来Go源文件接受带BOM的UTF8了, 但是运行 go fmt 之后, 还是会删除掉BOM的(因为BOM就是然并卵). 也就是说 带 BOM 的 Go 源文件是不符合 Go语言的编码风格的, go fmt 会强制删除 BOM 头.
前面说了BOM是MS带来的垃圾, 但是BOM的UTF8除了然并卵之外还有很多问题, 因为BOM在string的开头嵌入了垃圾,
导致正则表达式, string的链接运算等操作都被会被BOM这个垃圾所污染. 对于.go语言, 即使代码完全一样, 有BOM和无BOM会导致文件的MD5之类的校验码不同.
所以, 我觉得Go用户不用纠结BOM这个无关紧要的东西.
在上一个10年,我(Liigo)在我所属的公司里,深度参与了两个编程语言项目的开发。我想,对于如何判断某个编程语言的优劣,或者说至少对于如何判断某个编程语言是否适合于我自己,我应该还是有一点发言权的。
第1节:我为什么对Go语言不爽?
Go语言有很多让我不爽之处,这里列出我现在还能记起的其中一部分,排名基本上不分先后。读者们耐心地看完之后,还能淡定地说一句“我不在乎”吗?
1.1 不允许左花括号另起一行
关于对花括号的摆放,在C语言、C++、Java、C#等社区中,十余年来存在持续争议,从未形成一致意见。在我看来,这本来就是主观倾向很重的抉择,不违反原则不涉及是非的情况下,不应该搞一刀切,让程序员或团队自己选择就足够了。编程语言本身强行限制,把自己的喜好强加给别人,得不偿失。无论倾向于其中任意一种,必然得罪与其对立的一群人。虽然我现在已经习惯了把左花括号放在行尾,但一想到被禁止其他选择,就感到十分不爽。Go语言这这个问题上,没有做到“团结一切可以团结的力量”不说,还有意给自己树敌,太失败了。
我觉得Go最伟大的发明是 go fmt, 从此Go用户不会再有花括弧的位置这种无聊争论了(当然也少了不少灌水和上tiobe排名的机会).
是这优点, Swift 语言也使用和 Go 类似的风格(当然楼主也可能鄙视swift的作者).
1.2 编译器莫名其妙地给行尾加上分号
对Go语言本身而言,行尾的分号是可以省略的。但是在其编译器(gc)的实现中,为了方便编译器开发者,却在词法分析阶段强行添加了行尾的分号,反过来又影响到语言规范,对“怎样添加分号”做出特殊规定。这种变态做法前无古人。在左花括号被意外放到下一行行首的情况下,它自动在上一行行尾添加的分号,会导致莫名其妙的编译错误(Go 1.0之前),连它自己都解释不明白。如果实在处理不好分号,干脆不要省略分号得了;或者,Scala和javascript的编译器是开源的,跟它们学学怎么处理省略行尾分号可以吗?
又是楼主的 个人主观感受, 不过我很喜欢这个特性. Swift 语言也是类似.
1.3 极度强调编译速度,不惜放弃本应提供的功能
程序员是人不是神,编码过程中免不了因为大意或疏忽犯一些错。其中有一些,是大家集体性的很容易就中招的错误(Go语言里的例子我暂时想不起来,C++里的例子有“基类析构函数不是虚函数”)。这时候编译器应该站出来,多做一些检查、约束、核对性工作,尽量阻止常规错误的发生,尽量不让有潜在错误的代码编译通过,必要时给出一些警告或提示,让程序员留意。编译器不就是机器么,不就是应该多做脏活累活杂活、减少人的心智负担么?编译器多做一项检查,可能会避免数十万程序员今后多年内无数次犯同样的错误,节省的时间不计其数,这是功德无量的好事。但是Go编译器的作者们可不这么想,他们不愿意自己多花几个小时给编译器增加新功能,觉得那是亏本,反而减慢了编译速度。他们以影响编译速度为由,拒绝了很多对编译器改进的要求。典型的因噎废食。强调编译速度固然值得赞赏,但如果因此放弃应有的功能,我不赞成。
编译速度是很重要的, 如果编译速度够慢, 语言再好也不会有人使用的.
比如C/C++的增量编译/预编译头文件/并发编译都是为了提高编译速度.
Rust1.1 也号称 比 1.0 的编译时间减少了32% (注意: 不是运行速度).
当然, Go刚面世的时候, 编译速度是其中的一个设计目标.
不过我想楼主, 可能想说的是因为编译器自己添加分号而导致的编译错误的问题.
我觉得Go中 不能另起一行是语言特性, 如果修复这个就是引入了新的错误.
其他的我真想不起来还有哪些 调编译速度,不惜放弃本应提供的功能 (不要提泛型, 那是因为还没有好的设计).
1.4 错误处理机制太原始
在Go语言中处理错误的基本模式是:函数通常返回多个值,其中最后一个值是error类型,用于表示错误类型极其描述;调用者每次调用完一个函数,都需要检查这个error并进行相应的错误处理:if err != nil /*这种代码写多了不想吐么*/ 。此模式跟C语言那种很原始的错误处理相比如出一辙,并无实质性改进。实际应用中很容易形成多层嵌套的if else语句,可以想一想这个编码场景:先判断文件是否存在,如果存在则打开文件,如果打开成功则读取文件,如果读取成功再写入一段数据,最后关闭文件,别忘了还要处理每一步骤中出现错误的情况,这代码写出来得有多变态、多丑陋?实践中普遍的做法是,判断操作出错后提前return,以避免多层花括号嵌套,但这么做的后果是,许多错误处理代码被放在前面突出的位置,常规的处理逻辑反而被掩埋到后面去了,代码可读性极差。而且,error对象的标准接口只能返回一个错误文本,有时候调用者为了区分不同的错误类型,甚至需要解析该文本。除此之外,你只能手工强制转换error类型到特定子类型(静态类型的优势没了)。至于panic - recover机制,致命的缺陷是不能跨越库的边界使用,注定是一个半成品,最多只能在自己的pkg里面玩一玩。Java的异常处理虽然也有自身的问题(比如Checked Exceptions),但总体上还是比Go的错误处理高明很多。
话说, 软件开发都发展了半个世纪, 还是无实质性改进. 不要以为弄一个异常的语法糖就是革命了.
我只能说错误和异常是2个不同的东西, 将所有错误当作异常那是SB行为.
正因为有异常这个所谓的银弹, 导致很多等着别人帮忙擦屁股的行为(注意 shit 函数抛出的绝对不会是一种类型的 shit, 而被其间接调用的各种 xxx_shit 也可能抛出各种类型的异常, 这就导致 catch 失控了):
int main()
try
shit();
catch( /* 到底有几千种 shit ? */)
...
Go的建议是 panic - recover 不跨越边界, 也就是要求正常的错误要由pkg的处理掉.
这是负责任的行为.
再说Go是面向并发的编程语言, 在海量的 goroutine 中使用 try/catch 是不是有一种不伦不类的感觉呢?
1.5 垃圾回收器(GC)不完善、有重大缺陷
在Go 1.0前夕,其垃圾回收器在32位环境下有内存泄漏,一直拖着不肯改进,这且不说。Go语言垃圾回收器真正致命的缺陷是,会导致整个进程不可预知的间歇性停顿。像某些大型后台服务程序,如游戏服务器、APP容器等,由于占用内存巨大,其内存对象数量极多,GC完成一次回收周期,可能需要数秒甚至更长时间,这段时间内,整个服务进程是阻塞的、停顿的,在外界看来就是服务中断、无响应,再牛逼的并发机制到了这里统统失效。垃圾回收器定期启动,每次启动就导致短暂的服务中断,这样下去,还有人敢用吗?这可是后台服务器进程,是Go语言的重点应用领域。以上现象可不是我假设出来的,而是事实存在的现实问题,受其严重困扰的也不是一家两家了(2013年底ECUG Con 2013,京东的刘奇提到了Go语言的GC、defer、标准库实现是性能杀手,最大的痛苦是GC;美团的沈锋也提到Go语言的GC导致后台服务间隔性停顿是最大的问题。更早的网络游戏仙侠道开发团队也曾受Go垃圾回收的沉重打击)。在实践中,你必须努力减少进程中的对象数量,以便把GC导致的间歇性停顿控制在可接受范围内。除此之外你别无选择(难道你还想自己更换GC算法、甚至砍掉GC?那还是Go语言吗?)。跳出圈外,我近期一直在思考,一定需要垃圾回收器吗?没有垃圾回收器就一定是历史的倒退吗?(可能会新写一篇博客文章专题探讨。)
这是说的是32位系统, 这绝对不是Go语言的重点应用领域!! 我可以说Go出生就是面向64位系统和多核心CPU环境设计的. (再说 Rust 目前好像还不支持 XP 吧, 这可不可以算是影响巨大?)
32位当时是有问题, 但是对实际生产影响并不大(请问楼主还是在用32位系统吗, 还只安装4GB的内存吗). 如果是8位单片机环境, 建议就不要用Go语言了, 直接C语言好了.
而且这个问题早就不存在了(大家可以去看Go的发布日志).
Go的出生也就5年时间, GC的完善和改进是一个持续的工作, 2015年8月将发布的 Go1.5将采用并行GC.
关于GC的被人诟病的地方是会导致卡顿, 但是我以为这个主要是因为GC的实现还不够完美而导致的.
如果是完美的并发和增量的GC, 那应该不会出现大的卡顿问题的.
当然, 如果非要实时性, 那用C好了(实时并不表示性能高, 只是响应时间可控).
对于Rust之类没有GC的语言来说, 想很方便的开发并发的后台程序那几乎是不可能的.
不要总是吹Rust能代替底层/中层/上层的开发, 我们要看有谁用Rust真的做了什么.
1.6 禁止未使用变量和多余import
Go编译器不允许存在被未被使用的变量和多余的import,如果存在,必然导致编译错误。但是现实情况是,在代码编写、重构、调试过程中,例如,临时性的注释掉一行代码,很容易就会导致同时出现未使用的变量和多余的import,直接编译错误了,你必须相应的把变量定义注释掉,再翻页回到文件首部把多余的import也注释掉,……等事情办完了,想把刚才注释的代码找回来,又要好几个麻烦的步骤。还有一个让人蛋疼的问题,编写数据库相关的代码时,如果你import某数据库驱动的pkg,它编译给你报错,说不需要import这个未被使用的pkg;但如果你听信编译器的话删掉该import,编译是通过了,运行时必然报错,说找不到数据库驱动;你看看程序员被折腾的两边不是人,最后不得不请出大神:import _。对待这种问题,一个比较好的解决方案是,视其为编译警告而非编译错误。但是Go语言开发者很固执,不容许这种折中方案。
这个问题我只能说楼主的吐槽真的是没水平.
为何不使用的是错误而不是警告? 这是为了将低级的bug消灭在编译阶段(大家可以想下C/C++的那么多警告有什么卵用).
而且, import 即使没有使用的话, 也是用副作用的, 因为 import 会导致 init 和全局变量的初始化.
如果某些代码没有使用, 为何要执行 init 这些初始化呢?
如果是因为调试而添加的变量, 那么调试完删除不是很正常的要求吗?
如果是因为调试而要导入fmt或log之类的包, 删除调试代码后又导致 import 错误的花,
楼主难道不知道在一个独立的文件包装下类似的辅助调试的函数吗?
import (
"fmt"
"log"
)
func logf(format string, a ...interface)
file, line := callerFileLine()
fmt.Fprintf(os.Stderr, "%s:%d: ", file, line)
fmt.Fprintf(os.Stderr, format, a...)
func fatalf(format string, a ...interface)
file, line := callerFileLine()
fmt.Fprintf(os.Stderr, "%s:%d: ", file, line)
fmt.Fprintf(os.Stderr, format, a...)
os.Exit(1)
import _ 是有明确行为的用法, 就是为了执行包中的 init 等函数(可以做某些注册操作).
将警告当作错误是Go的一个哲学, 当然在楼主看来这是白痴做法.
1.7 创建对象的方式太多令人纠结
创建对象的方式,调用new函数、调用make函数、调用New方法、使用花括号语法直接初始化结构体,你选哪一种?不好选择,因为没有一个固定的模式。从实践中看,如果要创建一个语言内置类型(如channel、map)的对象,通常用make函数创建;如果要创建标准库或第三方库定义的类型的对象,首先要去文档里找一下有没有New方法,如果有就最好调用New方法创建对象,如果没有New方法,则退而求其次,用初始化结构体的方式创建其对象。这个过程颇为周折,不像C++、Java、C#那样直接new就行了。
C++的new是狗屎. new导致的问题是构造函数和普通函数的行为不一致, 这个补丁特性真的没啥优越的.
我还是喜欢C语言的 fopen 和 malloc 之类构造函数, 构造函数就是普通函数, Go语言中也是这样.
C++中, 除了构造不兼容普通函数, 析构函数也是不兼容普通函数. 这个而引入的坑有很多吧.
1.8 对象没有构造函数和析构函数
没有构造函数还好说,毕竟还有自定义的New方法,大致也算是构造函数了。没有析构函数就比较难受了,没法实现RAII。额外的人工处理资源清理工作,无疑加重了程序员的心智负担。没人性啊,还嫌我们程序员加班还少吗?C++里有析构函数,Java里虽然没有析构函数但是有人家finally语句啊,Go呢,什么都没有。没错,你有个defer,可是那个defer问题更大,详见下文吧。
defer 可以覆盖析构函数的行为, 当然 defer 还有其他的任务. Swift2.0 也引入了一个简化版的 defer 特性.
1.9 defer语句的语义设定不甚合理
Go语言设计defer语句的出发点是好的,把释放资源的“代码”放在靠近创建资源的地方,但把释放资源的“动作”推迟(defer)到函数返回前执行。遗憾的是其执行时机的设置似乎有些不甚合理。设想有一个需要长期运行的函数,其中有无限循环语句,在循环体内不断的创建资源(或分配内存),并用defer语句确保释放。由于函数一直运行没有返回,所有defer语句都得不到执行,循环过程中创建的大量短暂性资源一直积累着,得不到回收。而且,系统为了存储defer列表还要额外占用资源,也是持续增加的。这样下去,过不了多久,整个系统就要因为资源耗尽而崩溃。像这类长期运行的函数,http.ListenAndServe()就是典型的例子。在Go语言重点应用领域,可以说几乎每一个后台服务程序都必然有这么一类函数,往往还都是程序的核心部分。如果程序员不小心在这些函数中使用了defer语句,可以说后患无穷。如果语言设计者把defer的语义设定为在所属代码块结束时(而非函数返回时)执行,是不是更好一点呢?可是Go 1.0早已发布定型,为了保持向后兼容性,已经不可能改变了。小心使用defer语句!一不小心就中招。
前面说到 defer 还有其他的任务, 也就是 defer 中执行的 recover 可以捕获 panic 抛出的异常.
还有 defer 可以在 return 之后修改命名的返回值.
上面2个工作要求 defer 只能在函数退出时来执行.
楼主说的 defer 是类似 Swift2.0 中 defer 的行为, 但是 Swift2.0 中 defer 是没有前面2个特性的.
Go中的defer是以函数作用域作为触发的条件的, 是会导致楼主说的在 for 中执行的错误用法(哪个语言没有坑呢?).
不过 for 中 局部 defer 也是有办法的 (Go中的defer是以函数作用域):
for
func()
f, err := os.Open(...)
defer f.Close()
()
在 for 中做一个闭包函数就可以了. 自己不会用不要怪别人没告诉你.
1.10 许多语言内置设施不支持用户定义的类型
for in、make、range、channel、map等都仅支持语言内置类型,不支持用户定义的类型(?)。用户定义的类型没法支持for in循环,用户不能编写像make、range那样“参数类型和个数”甚至“返回值类型和个数”都可变的函数,不能编写像channel、map那样类似泛型的数据类型。语言内置的那些东西,处处充斥着斧凿的痕迹。这体现了语言设计的局限性、封闭性、不完善,可扩展性差,像是新手作品——且不论其设计者和实现者如何权威。延伸阅读:Go语言是30年前的陈旧设计思想,用户定义的东西几乎都是二等公民(Tikhon Jelvis)。
说到底, 这个是因为对泛型支持的不完备导致的.
Go语言是没啥NB的特性, 但是Go的特性和工具组合在一起就是好用.
这就是Go语言NB的地方.
1.11 没有泛型支持,常见数据类型接口丑陋
没有泛型的话,List、Set、Tree这些常见的基础性数据类型的接口就只能很丑陋:放进去的对象是一个具体的类型,取出来之后成了无类型的interface(可以视为所有类型的基础类型),还得强制类型转换之后才能继续使用,令人无语。Go语言缺少min、max这类函数,求数值绝对值的函数abs只接收/返回双精度小数类型,排序接口只能借助sort.Interface无奈的回避了被比较对象的类型,等等等等,都是没有泛型导致的结果。没有泛型,接口很难优雅起来。Go开发者没有明确拒绝泛型,只是说还没有找到很好的方法实现泛型(能不能学学已经开源的语言呀)。现实是,Go 1.0已经定型,泛型还没有,那些丑陋的接口为了保持向后兼容必须长期存在着。
Go有自己的哲学, 如果能有和目前哲学不冲突的泛型实现, 他们是不会反对的.
如果只是简单学学(或者叫抄袭)已经开源的语言的语法, 那是C++的设计风格(或者说C++从来都是这样设计的, 有什么特性就抄什么), 导致了各种脑裂的编程风格.
编译时泛型和运行时泛型可能是无法完全兼容的, 看这个例子:
type Adder<T> interface
Add(a, b T) T
参考技术A 一个产品,好不好用。不是取决使用人数量多不多,而是取决你用得好不好用。一个产品的发展,需要一个稳定的基础条件,“基础条件”你明白是什么意思吗! 关系、平台、用户群、大数据、资金、广告等等。
如现实社会,有钱有名的人,做什么都能赚钱,用户体验得不好,说是用户体验的方式不对。你付出再多再多,做得再好再好有可能赚不到钱,用户体验得不好,【被】说是产品体验的本身不行。你明白这个比较吗!
*米品牌手机使用的人数很多很多,好用吗!当然有一堆人会站出说好用,对我来说不好用。*果手机好用吗!你自己说? 不同用户群体,不同的用户使用价值也不同,还有一些盲目的跟随者,还不知咱会事!这样的手机适用于他们做什么,适用于你做什么?
一些人天天在对go/golang语言说不好,见到这样的,只能对他说别吵了,我还有事要做。原谅他知识浅薄,对事物的理解程度不够。你要是跟他们一般见较,你和他们又有什么不同?
其它一些受影响的盲目跟随者,不要挽留他们,他们成不了大事的,也不会对这个行业(代码)知识做出多大的供献。
我自己的经历:我没有使用 Python,不是因他的绝对不好。使用golang入手快,文档易懂,编译单文件,函数有例子,并发简单,代码简洁(除非你喜欢完成一个简单的功能,使用复杂的代码,否则不要反对我),真正合适自己的才是最好的。(不扯性能,免得一些人又开喷: if、for、...)
没有比较,没有伤害。你就算比较,我也没伤害。你扯你的,我玩我的。
完成工作,下班回家。加班没工资的,除非你精力过剩。
写代码工作是常加班的,不建议大家入这行。人的一生,也就是为了赚点钱,过得轻松一些。
坚持还是放弃,Go 语言的“美好与丑陋”解读
协作翻译
原文:Go: the Good, the Bad and the Ugly
链接:https://bluxte.net/musings/2018/04/10/go-good-bad-ugly/
译者:Tocy, 琪花亿草, 凉凉_, kevinlinkai, Tot_ziens, 边城
作者语:我对 Go 又爱又恨。 Go 有点像一个朋友,你喜欢和他在一起,因为他很有趣,但是当你想要进行更深入的对话时,你会觉得无聊或痛苦,而且你不想与他去一起度假。
Go 确实有一些不错的特性,也就是本文中提到的“好”的部分,但是当我们不将它用于 API 或者网络服务器(这是为它设计的),而是将它用于业务领域逻辑的时候,它看起来比较糟糕。即使是用于网络编程,它在设计和实现方面也有很多缺陷。
最近我开始用 Go 做一个“兼职”项目,因此我用这篇文章总结一下我使用 Go 的体验。我希望这个博客已经让你了解到了一些关于 Go 的你曾经没意识到的问题,这样你就可以避免陷阱而不会被陷进去!

背景
我喜欢静态类型语言。我的第一个重要项目是用 Pascal 编写的。在 90 年代初我开始工作之时,我使用了 Ada 和 C/C ++,后来我迁移到了 Java,最后又使用了 Scala(在期间还用过 Go),最近开始学习 Rust。我还写了大量的 JavaScript 代码,因为直到最近它是 Web 浏览器中唯一可用的语言。对动态类型语言我感觉不牢靠,并尝试将其应用限制在简单脚本中。我对命令式、函数式和面向对象的方法感到很满意。
我通过三个方面介绍我使用 Go 的体验:好(the Good)、坏(the Bad)、丑(the Ugly)
本文目录
好的方面
Go 易于学习
使用协程(goroutines)和通道(channels)简单的并发编程
强大的标准库
GO 的高性能
语言所定义的源代码格式
标准化的测试框架
Go程序非常适合运维
Defer语句,用于避免遗忘清理
自定义类型
不好的方面
GO 忽略现代语言设计的进步
接口是结构类型
没有枚举类型
:= / var 的尴尬
零值恐慌
Go 中没有异常
丑的方面
依赖关系管理的噩梦
可变性在语言中是硬编码的
Slice 陷阱
Mutability 和 channels:更容易产生竞争条件
混乱的错误管理
Nil 接口值
结构字段标签:运行时字符串中的 DSL
没有泛型......至少不适合你
Go 除了分片和映射之外几乎没有数据结构
go generate:还行,但是...
结语
好的方面
Go 易于学习
这是事实:如果你会任何一种编程语言,你可以通过“Go 教程”在几个小时之内学会 Go 的大部分语法,在几天之内就可以写出你的第一个程序。阅读和消化 Effective Go,徘徊在标准库中,运用 web 工具包如 Gorilla 或者 Go kit,你就能成为一个相当不错的 Go 开发者。
这是因为 Go 的首要目标就是简单。当我开始学习 Go 的时候,它让我回忆起了我初次接触 Java:一个丰富却不臃肿的简单语言。与现在 Java 繁重的环境对比,学习 Go 是一个新鲜的体验。由于 Go 的简单,Go 程序是非常易读的,即使错误处理方面有不少麻烦。
但是这可能并不是真的简单。引用 Rob Pike 的话,简单即复杂,我们在下面可以看到在后面有很多的陷阱等着我们,简洁和极简主义阻止了我们编写 DRY 原则的代码。
使用协程(goroutines)和通道(channels)简单的并发编程
Goroutines 可能是 Go 最好的特性。与操作系统线程不同,这是轻量级的计算线程。
当一个 Go 程序执行阻塞 I/O 操作一类的工作时,实际上 Go 实时挂起了这个 goroutine,而且在一个 event 表明一些结果已经可以访问之后,会重新运行。在此期间,其他 goroutines 已经在执行调度。因此我们在使用一个同步编程模型做异步编程的时候有可扩展性的优点。
Goroutines 也是轻量级的:他们的栈按需增加或减少,也就是说有数百个甚至数千个 goroutines 都不是问题。
在一个应用中我曾经有一个 goroutine 泄露:在结束之前这些 goroutine 等待一个 channel 去关闭,但那个 channel 不会关闭(一个常见的死锁问题)。这个进程平白占了 90% 的 CPU,查看 expvars 发现 60 万个空的 goroutine!我猜 CPU 都被 goroutine 调度占用了。
当然,一个像 Akka 的 actor 系统可以不费力气就处理数百万 actors,一部分是因为 actors 没有栈,但是他们在写复杂并发 request/response 应用(如 http APIs)时不如 goroutine 简单。
Channel 是 goroutine 之间交互的通道:他们提供了一个方便的编程模型可以在 goroutine 之间发送和接收数据,而不用依赖脆弱的底层同步原语。Channel 拥有他们自己的一套使用模式。
由于错误的 channel 数量(他们默认无缓冲)会导致死锁,Channel 必须要慎重考虑。我们在下面也会提到因为 Go 缺少不变性,使用 channel 并不能阻止争抢资源。
强大的标准库
Go 标准库真的很强大,特别是对网络协议相关的所有东西或者 API 开发:http 客户端和服务器,加密,压缩格式,压缩,发送邮件等等。甚至还有 html 解析器和相当强大的模板引擎,通过自动 escaping 可以用来产生文字 text & html 来避免 XSS(在 Hugo 模板的示例中使用)。
大多数情况下 API 通常是简单易懂的:这当中,一部分是由于 goroutine 编程模式告诉我们只需要关心“看似同步”的操作。另一部分是因为少数通用的多功能函数能替代大量单一功能的函数,就像最近一段时间,我发现的那些用于时间计算的函数一样。
GO 的高性能
Go 编译成一个本地可执行文件。许多 Go 的用户来自于 Python,Ruby 或者 Node.js。对他们来说,这是个令人兴奋的体验,因为他们发现服务器可以处理的并发请求数量大幅的增加。对于没有并发的语言(Node.js)或者全局解释器锁(GIL)来说,这实际上是再正常不过的事情。结合语言的简单性,这说明了 Go 语言令人兴奋的一面。
然而相比 Java,在原始性能基准测试中,情况并不是那么清晰。在内存使用和垃圾收集方面 Go 力压 Java。
Go 的垃圾收集的设计目的是优先考虑延迟和避免 stop-the-world 停顿,这在服务器中尤其重要。这可能会带来更高的 CPU 成本,但是在水平可伸缩的架构(horizontally scalable architecture)中通过添加更多的机器这是易于解决的。记住,Go 是 Google 设计的,他们不缺资源。
相比于 Java,Go 的 GC 要做的工作更少:slice 的结构是一个连续的结构数组,而不是像 Java 这样的指针数组。相似地,Go 的 maps 出于同样的目的使用像桶的小数组。这意味着在 GC 上工作量更少,并且还更有利于 CPU 的缓存位置。
在命令行实用程序方面,Go 也可以力压 Java:一个本地可执行的,相对 Java 首先必须加载和编译字节码来说,Go 程序几乎没有启动成本。
语言所定义的源代码格式
在我职业生涯中一些最激烈的争论发生在团队代码格式的定义上。Go 通过为 Go 代码定义规范格式解决了这个问题。gofmt 工具会重新格式化你的代码,并且没有选项。
不管喜不喜欢,gofmt 都定义了 Go 代码应该如何格式化,因此该问题得到一次性解决!
标准化的测试框架
Go 在其标准库中提供了一个很好的测试框架。它支持并行测试、基准测试,并且包含很多用于轻松测试网络客户端和服务器的使用程序。
Go 程序非常适合运维
与 Python、Ruby 或 Node.js 相比,仅安装单个可执行文件对于运维工程师来说是一个梦想。随着越来越多的 Docker 投入使用,这个问题出现的越来越少,但独立的可执行文件也意味着更小的 Docker 镜像。
Go 还具有一些内置的可观察性功能,使用 expvar 包发布内部状态和指标,并且可以轻松添加新内容。但要小心,因为它们在默认的 http 请求处理程序中自动暴露,变得不受保护。Java 中 JMX 有类似的功能,但它更复杂。
Defer 语句,用于避免遗忘清理
defer 语句的作用类似于 Java 中的 finally:在当前函数结束时执行一些清理代码,并不管此函数是如何退出的。有关 defer 的有趣的事情是它没有链接到一段代码上,并可以随时出现。这允许清理代码尽可能靠近创建那些需要清理资源的代码:
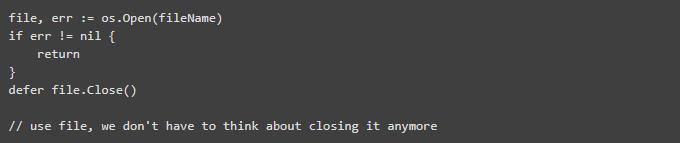
当然,Java 的“try-with-resource”不是那么冗长,同时 Rust 在资源的所有者被删除时会自动声明资源,但由于 Go 要求你对资源清理明确了解,因此用它靠近资源分配是很不错的。
自定义类型
我喜欢自定义类型,而且我恼怒/害怕一些情况,就好像当我们来回传一个字符串型或者 long 型的持久化对象标识符的时候。我们经常对参数名为 id 的类型编码,但是这就是一些产生小 bug 的原因,即当一个函数有多个标识符作为参数的时候,一些调用就会弄混参数顺序。
Go 的自定义类型支持 first-class,例如那些分配给一个已有类型的独立的标识符的类型,可以与原来的标识符区分开来。与封装相反,自定义类型没有运行时开销。这使得编译器能捕获这种错误:
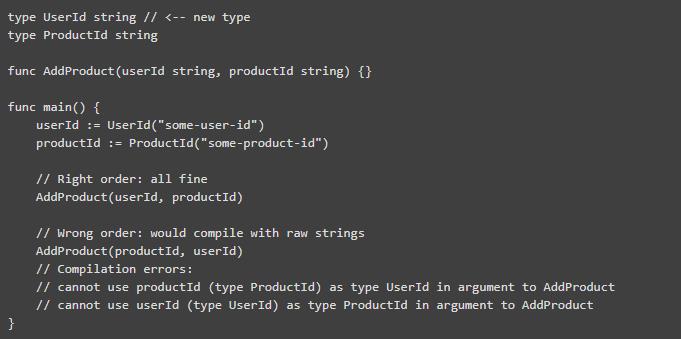
不幸的是,对那些要求自定义类型与原始类型做转换的人来说,由于不支持泛型,自定义类型在写复用代码的时候用起来比较累赘。
不好的方面
GO 忽略现代语言设计的进步
在大道至简(Less is exponentially more)的演讲上,Rob Pike 解释说 Go 是要取代 C 和 C++ 的,它的前身是 Newsqueak,这是他在 80 年代写的一种语言。Go 也有很多关于 Plan9 的参考,这是一个分布式操作系统,80 年代在贝尔实验室开发的。
甚至有一个 Go 组件直接从 Plan9 获得灵感。为什么不使用 LLVM 来提供范围广泛的目标体系结构呢?我可能也在这里漏掉了什么,但为什么需要呢?如果你需要编写程序集以充分利用 CPU,那么你不是应该直接使用目标 CPU 汇编语言吗?
Go 的设计者很值得尊敬,但是他们就像在一个平行宇宙(或者他们的 Plan9 实验室)设计的 Go,在那里大多数编译器和编程语言的设计是在 90 年代, 但在 21 世纪是没有的。或者,是那些能写编译器的系统编程人员设计了 Go。
函数式编程就不提了。泛型你们应该也用不着,看它们在 C++ 里产生的混乱就知道了!
Go 的目标就是代替 C 和 C++,但是很明显它的设计者没有多看看其他语言。他们避开了他们的目标,Google 的 C 和 C++ 开发者不采用它。我猜主要原因就是垃圾回收。低级 C 开发者十分抗拒管理内存,因为他们不了解管理什么,在什么时候管理。他们喜欢这种控制,即使会带来额外的复杂,而且打开内存泄露和 buffer 溢出的大门。有趣的是,Rust 在不使用 GC 的情况下使用另一种方法做自动内存管理。
相反的,在操作工具方面 Go 吸引了那些像使用 Python 和 Ruby 等脚本语言的人。他们在 Go 中发现一个方法,有很好的性能,而且减少了内存/CPU/硬盘的占用空间。而且也是更 static 的类型,这对他们来说是新颖的。对 Go 来说 Docker 是杀手级应用,这使得它在开发界开始被广泛使用。Kubernetes 的提出加强了这个趋势。
Interfaces 是结构化类型(structural types)
Go 的 interfaces 就像 Java 的 interface 或者 Scala 和 Rust 的 trait:他们定义行为,之后才会被一个 type(我在这不把他们叫做“class”)实现。
不像 Java 的 interface 和 Scala 和 Rust 的 trait,一个 type 不需要明确定义它实现了一个 interface:它必须要实现所有定义在 interface 中的函数。因此 Go 的 interfaces 的确是 structural types。
我们也许认为 Go 允许在其他的 package 中实现 interface,而不仅仅是在 type 所在的 package 中申请,就像 Scala、Kotlin 的类扩展和 Rust 的 trait 一样。但事实并非如此:与 type 相关的所有方法都必须在这个 type 的 package 中定义。
Go 并不是唯一使用 structural typin g的语言,但我发现它存在几个缺点:
寻找有哪些 type 实现了 interface 是困难的,因为它依赖于函数定义匹配。在 Java 或 Scala 中,我经常通过搜索实现了 interface 的类来寻找相关的实现。
当给 interface 添加一个方法时,你将会发现只有当那些 types 被用作 interface type 的值时,type 才会被更新。很长一段时间内你会忽视这种问题。Go 建议尽少使用方法来创建 interface,以此来防止该问题的发生。
因为 type 中有一个方法与 interface 相同,这个 type 可能会无意中实现了一个 interface。但是偶然的情况下,它所实现的功能可能与预想的 interface 协议不同。
更新:interface 的一些丑陋的地方,请详看后面的“interface 空值”章节。
没有枚举类型
Go 中没有枚举值,我觉得这是它的损失。
iota 可以快速生成自增的数值,但它看起来更像是一种修改而非特性。而实际上,由于在一系列 iota 所生成的常量中插入一行会改变其后面的值是一个危险的操作。由于所生成的值是在整个代码中使用的,因此这可能会触发意外。
这也意味着在 Go 中没有办法让编译器检查 switch 语句是否详尽,并且无法描述给定类型所支持的值。
:= / var 的尴尬
Go 提供了两种方法声明和分配给变量一个值:var x = "foo" 和 x := "foo”,为什么这样?
主要区别是:var 允许声明而不初始化(那你就必须声明类型),就像 var x string,然而 := 要求分配一个值,而且这种方法可以同样用于已有变量和新变量。我猜发明 := 就是用来让我们在捕获错误的时候不那么痛苦:
使用 var:

使用 := :

:= 语法也容易在不经意中对一个变量重新赋值。我曾经不止一次遇到这个问题,就像 :=(声明和分配)与=(分配)太像了,就像下面这样:

零值恐慌
Go 里没有构造函数。因此,它奉行“零值”应该可以随时使用。这是一个有趣的方法,但在我看来,它所带来的简化化主要是针对语言实现者的。
在实践中,如果没有正确的初始化,许多类型都不能做有用的事情。让我们来看一下在 Effective Go 中作为示例的 io.Fileobject:
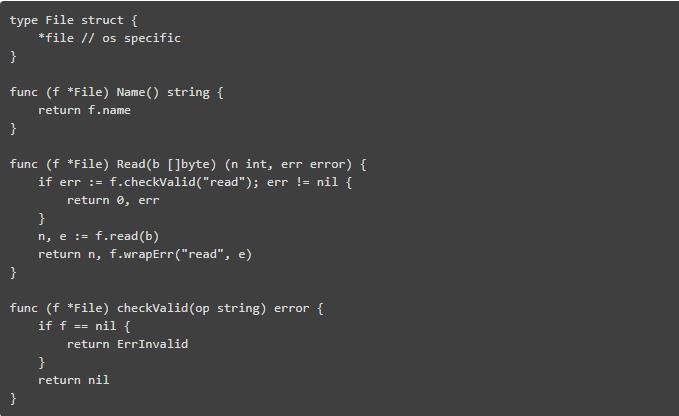
我们在这里能看到什么呢?
在零值文件上调用 Name() 将会出现问题,因为它的 file 字段为 nil。
Read 函数和 File 几乎所有其他的方法都一样,首先检查文件是否已初始化。
所以基本上零值文件不仅没用,而且会导致问题。你必须使用以下构造函数中的一个:如“Open”或“Create”。检查是否正确的初始化是每次函数调用都必须承受的开销。
标准库中有无数类似这样的类型,有些甚至不试图使用它们的零值做一些有用的事情。在零值的 html.Template 上调用任何方法:它们都引起问题。
同时 map 的零值有个严重的缺陷:它可以查询,但在 map 中存储任何数据都有导致 panic 异常:
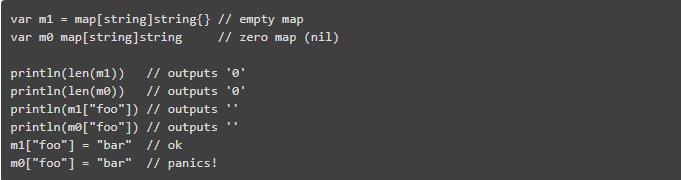
当结构具有 map 字段时,就要当心了,因为在向其添加条目之前必须对其进行初始化。
因此,身为一名开发人员,你必须经常检查你要使用的结构体是否需要调用构造函数或者零值是否有用。为了一些语言上的简化,这将给代码编写者带来很大的负担。
Go 的异常
博客文章“为何 Go 处理异常是正确的”中详细解释了为什么异常是很糟糕的,以及为什么 Go 中的方法需要返回错误是更好的作法。我同意这一点,并且在使用异步编程或像 Java 流这样的函数式风格时,异常是很难处理的(让我们暂且将之抛之脑后,因为前者在 Go 中是不需要的,这要归功于 goroutine;而后者根本不可能)。该博文中提到 panic 是“对你的程序总是致命的,游戏结束”,这是对的。
现在,“Defer, panic 和 recove”在这之前,解释了如何从 panic 中恢复过来(实际上通过捕获它们),并说:“对于一个真实世界的 panic 和恢复示例,请参阅 Go 标准库中的 json 包。
事实上,json 解码器有一个会触发 panic 的通用的错误处理函数,在最顶层的 unmarshal l函数中可恢复该 panic,该函数将检查 panic 类型,并在其是“local panic”时将其作为错误返回,或重新触发 panic 错误(在此丢失了原来的 panic 堆栈跟踪信息)。
对于任一 Java 开发人员来说,这看起来像try / catch (DecodingException ex)。所以 Go 确实有异常,可以在内部使用,但不建议你这么做。
有趣的是:几个星期前,一个非 googler 修复了 json 解码器,其中使用常规错误冒泡。
丑陋的方面
依赖关系管理
一位知名的 Google Go 开发者 Jaana Dogan(又名 JBD),最近在推特上发泄他的不满:
如果依赖关系管理不能在一年解决,我会考虑弃用 Go 并且永远不再回来。依赖性管理问题通常会改变我从语言中获得的所有乐趣。
让我们把它简单化:Go 中没有依赖项管理,所有当前的解决方案都只是一些技巧和变通方法。
这可以追溯回谷歌的起源阶段,众所周知,谷歌使用了一个巨大的单块存储库,用于所有源代码。不需要模块版本控制,不需要第三方模块存储库,你在你当前分支上build任何(你想要的)东西。不幸的是,这在开放的互联网上行不通。
为 Go 添加依赖就表示将依赖项的源代码库拷贝到 GOPATH 中。但是是什么版本呢?是克隆时的 master 分支,不管它是哪个版本。如果不同项目需要不同版本的依赖项怎么办呢?没办法。版本的概念甚至不存在。
同时,自己的项目也要放在 GOPATH,否则编译器就找不到它。你是否想让项目整洁的组织在各自独立的目录中呢?那就必须想为每个项目设置 GOPATH 或恰当的建立符合连接。
社区中设计出来的方法带来了大量工具。包管理工具引入了提供方和 lock 文件,它们包含的 Git ShA1 可以支持重复构建。
vendor 目录最终在 Go 1.6 中得到了官方支持。但对于克隆的供应内容,仍然没有合适的版本管理。也不能通过语义化版本解决混淆导入和依赖传递的问题。
不过情况正在好转:dep,最近出现了这个官方依赖管理工具用于支持供应内容。它支持版本(git tags),同时具有支持语义化版本约定的版本解析器。这个工具尚未达到稳定版本,但它在做正确的事情。而且,它仍然需要你把项目放在 GOPATH 目录下。
但dep可能不会存在太久,因为 vgo,也来自 Google,想在语言本身中引入版本信息并且近期一直在发起一些此类的浪潮。
所以 Go 中的依赖管理是噩梦般的存在。完成配置是很痛苦的,而你在开发过程中从没有考虑过它,直到你添加一个新的导入或者简单地想把你的一个团队成员的一个分支拉到你的 GOPATH 中时...
现在让我们回到代码上吧。
可变性在语言中是硬编码的
在 Go 中没有办法定义不可变的结构体:struct 字段是可变的,而 const 关键词不适用于它们。Go 可以很容易地通过简单的赋值来完成整个结构的复制,因此我们可能会认为按值传参是以复制为代价以实现不变性的前提。
然而,毫不奇怪,这不会复制由指针引用的值。由于内置集合(map,slice 和 array)是引用并且是可变的,所以复制包含其中之一的结构体只会将复制指向同一后台内存的指针。
下面的示例说明这一点:
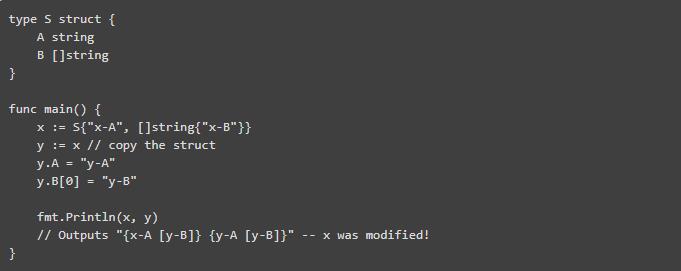
所以你必须对此非常小心,并且如果你是通过传值来传递参数的话,则不要假定它是不可变的。
有一些 deepcopy 库试图用(慢)反射来解决这个问题,但由于专有字段不能被反射访问,所以它们存在不足之处。因此可避免竞态条件的预防式复制将会是很困难的,需要大量的样板代码。Go 甚至没有可以标准化的 Clone 接口。
Slice 陷阱
Slice 带来了很多陷阱:就像在“Go slices: usage and internals”中解释的一样,由于一些性能原因,re-slicing 一个 slice 不会复制底层数组。它的目的是好的,但这意味着一个 slice 中的子 slice 仅仅是继承了原始 slice 的 mutations 的视图。因此如果你想将子 slice 与原始的 slic e区分,不要忘了 copy() 这个 slice。
因为 append 函数,忘记调用 copy() 会很危险:如果它没有足够的容量存储新值,在一个 slice 中 append 一个值会改变底层数组的大小。这就意味着 append 的结果可能会也可能不会指向依赖初始化容量的原始的数组。这会导致很难找到不确定的 bug。
在下面的代码我们看到一个函数将值 append 到一个子 slice 改变了使用容量初始化的原始 slice 产生的结果。
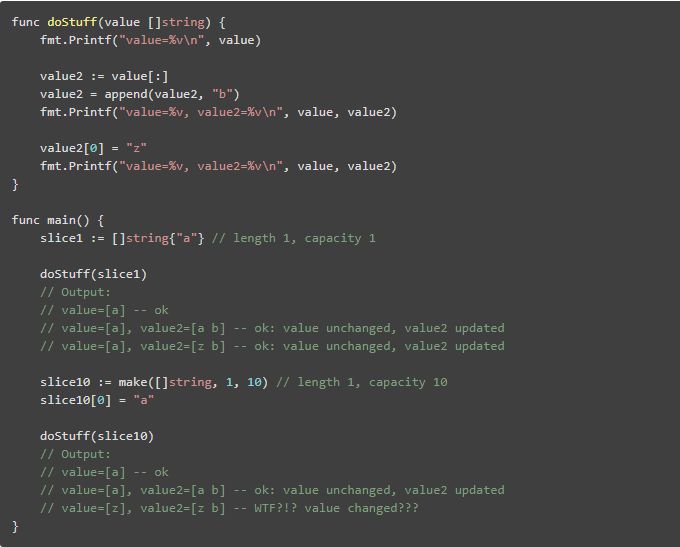
Mutability 和 channels:更容易产生竞争条件
Go 的并发是使用 channel 在 CSP 上建立的,这会使相应的 goroutine 比同步共享数据更加简单和安全。这里的 mantra 是“不要通过共享内存来通信;相反,通过通信来共享内存”。然而这只是一厢情愿,实际上并不能安全的完成这个目标。
就像我们之前看到的,在 Go 中没有方法使用不可变数据结构。这意味着我们使用 channel 发送一个指针,就玩完了:我们在并发进程共享了可变数据。当然 structure(不是指针)的一个 channel 复制了在 channel 上发送的值,但是就像我们之前看到的,这不是深度复制引用,包括 slice 和 map,他们本质上都是可变的。一个 interface type 的结构字段也是一样:他们是指针,interface 定义的任何 mutation 方法都是通向竞争条件的大门。
因此虽然 channel 明显让并发编程更简单,但他们不阻止在共享数据里的竞争条件。而且 slice 和 map 的本质可变性让这种情况更容易发生。
来说一下竞争条件,Go 包含了一个竞争条件的检测模式,这些代码工具是用来寻找未同步的共享访问。它只能在他们出问题的时候检测竞争问题,因此大多都是在集成或负载测试中使用,借此期望产生会引发竞争条件的问题。在生产中,实际上这并不可行,因为它的高运行时代价,除了临时 debug sessions。
混乱的错误管理
在 Go 中你需要快速学习的是错误处理模式,因为反复出现:

由于 Go 声称不支持异常(虽然它支持异常),但每个可能以错误结尾的函数都必须有 error 作为其最终处理结果。 这尤其适用于执行一些 I/O 功能,因此这种冗长的模式在网络应用程序中非常普遍,这是 Go 的主要领域。
你的眼睛会很快为这种模式开发一个可视化过滤器,并将其识别为“是的,错误处理”,但仍然有很多其他干扰,有时很难在错误处理过程中找到实际的代码。
虽然有一些陷阱,因为错误结果实际上可能只是一个表面上的情况,例如从普遍存在的 io.Reader 读取时:

在“有价值错误”中,Rob Pike 提出了一些减少冗长错误处理的策略。 我发现他们实际上是危险的救急:
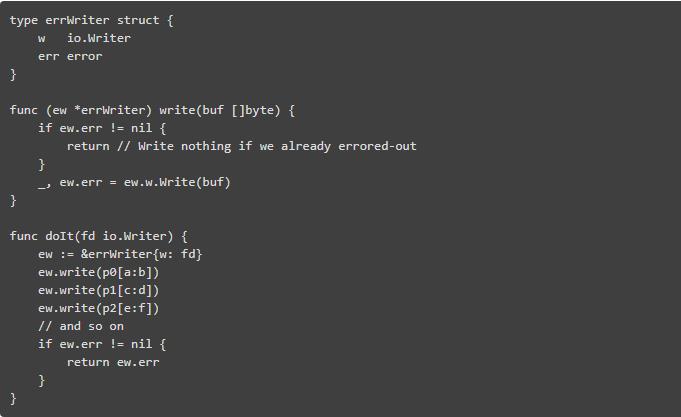
以上的检查错误一直令人痛苦,这种模式忽略了写入时的序列错误,而是在写完时才提示。 因此,任何执行的操作都会在执行完错误后执行。 如果这些比分片更昂贵呢? 我们只是浪费资源。
Rust 有一个类似的问题:没有异常(与 Go 相反),函数可能失败后返回 Result <T,Error>,并且需要对结果进行一些模式匹配。 所以 Rust 1.0 带有 try! 宏指令认识到这种模式的普遍性,并做成一流的语言功能。 因此,您在保持正确的错误处理的同时保持上述代码的简洁。
不幸的是,将 Rust 的方法转换为 Go 是不可能的,因为 Go 没有泛型或宏。
无接口值
在一次更新后,出现 redditor jmickeyd 显示 nil 和接口的奇怪行为,这十分丑陋。 我把它扩展了一点:
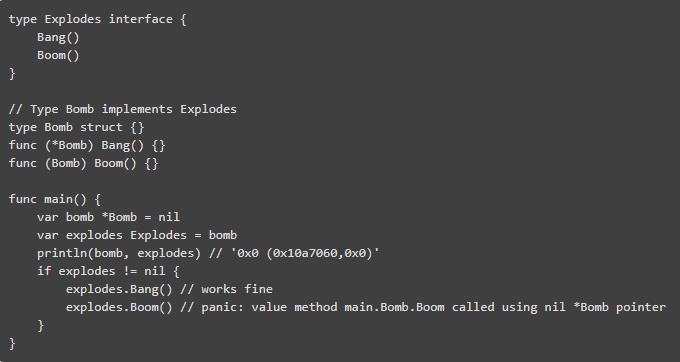
上面的代码验证了 explode 不是 nil,但是 code 在 Boom 中冒出来,但不在 Bang 中。 这是为什么? 解释一下在 println 行中:bomb 指针是0x0,实际上是 nil,但 explodes 是非空值(0x10a7060,0x0)。
对 Bang 的调用成功了,因为它应用在指向 Bomb 的指针上:不需要解引用该指针来调用该方法。Boom 方法操作一个值,因此一个调用导致指针被解引用,这会导致 panic。
请注意,如果我们写了 var explode Explodes = nil,那么 != nil 将不会成功。
那么我们应该如何以安全的方式编写测试? 我们必须对接口值和非零值都进行 nil-check,检查接口对象指向的值...使用反射!

错误或功能? Tour of Go 有一个专门的页面来解释这种行为,并明确指出:“请注意,一个具有 nil 值的接口值本身不是零”。
不过,这很丑陋,可能会导致很微小的错误。 它在语言设计中看起来像是一个很大的缺陷,使其实现更容易。
结构字段标签:运行时字符串中的 DSL
如果您在 Go 中使用过 JSON,您肯定遇到过类似的情况:

这些语言规范所说的结构标签是一个字符串“通过反射接口可见并参与结构的类型标识,但是被忽略”。 所以基本上,写上任何你想要的字符串,并在运行时使用反射来解析它。 如果语法不对,会在运行时会出现宕机。
这个字符串实际上是字段元数据,在许多语言中已经存在了数十年的“注释”或“属性”。 通过语言支持,它们的语法在编译时被正式定义和检查,同时仍然是可扩展的。
为什么 Go 决定使用原始字符串,并且任何库都可以决定是否使用它想要的任何 DSL,在运行时解析?
当您使用多个库时,情况可能会变得尴尬:下面是从协议缓冲区的 Go 文档中取出的一个例子:

边注:为什么在使用 JSON 的时候有很多常见的标签。因为在 Go 中,public 的字段必须使用大骆驼命名法,或者至少以大写字母开始。然而在 JSON 中,常见的字段命名习惯用小骆驼命名法或者蛇形命名法。因此需要很多冗长的标签。
JSON 编码器和解码器标准不允许提供命名策略来转自动转化,就像 Java 中的 Jackso n文档。这就解释了为什么在 Docker API 的所有的字段都是大驼峰命名法:避免他的开发人员为他们的大型 API 写这些麻烦的标签。
没有泛型......至少不适合你
很难想象一个没有泛型的现代静态类型语言,但这就是你用 Go 得到的东西:它没有泛型......或者更确切地说几乎没有泛型,正如我们将看到的那样,这使得它比没有泛型更糟糕。
内置切片,地图,数组和通道是通用的。 声明一个 map [string] MyStruct 清楚地显示了使用具有两个参数的泛型类型。 这很好,因为它允许类型安全编程捕捉各种错误。
然而,没有用户可定义的泛型数据结构。这意味着你无法以类型安全的方式定义可用于任何一个 type 的可复用 abstractions。你必须使用 untyped 的 interface{} 并且需要将值转成合适的 type。任何错误都只会在运行时捕获,并且产生了 panic。作为一个 Java 开发者,这就像回到了之前 2004 年 Java 5 时代。
在 "Less is exponentially more"中,Rob Pike 惊人的将泛型和继承放进了同一个“typed programming”包中,说他赞成组合替换继承。不喜欢继承是可以的(事实上,我写Scala的时候很少使用继承)但是泛型解决了另一个问题:在保持类型安全的同时有可复用性。
正如接下来我们将看到的,把内置的泛型与用户定义的非泛型分隔开,对开发者的“舒适度”和编译时的类型安全产生了影响:它影响了整个Go的生态系统。
Go 除了分片和映射之外几乎没有数据结构
Go 生态系统没有很多数据结构,它们可以从内置切片和贴图中提供额外的功能或不同的功能。 Go的最新版本添加了其中几个的容器包。 他们都有同样的说明:他们处理interface{}值,这意味着你失去了所有类型的安全机制。
我们来看看 sync.Map 的一个例子,它是一个具有较低线程争用的并发映射,而不是使用互斥锁来保护常规映射:
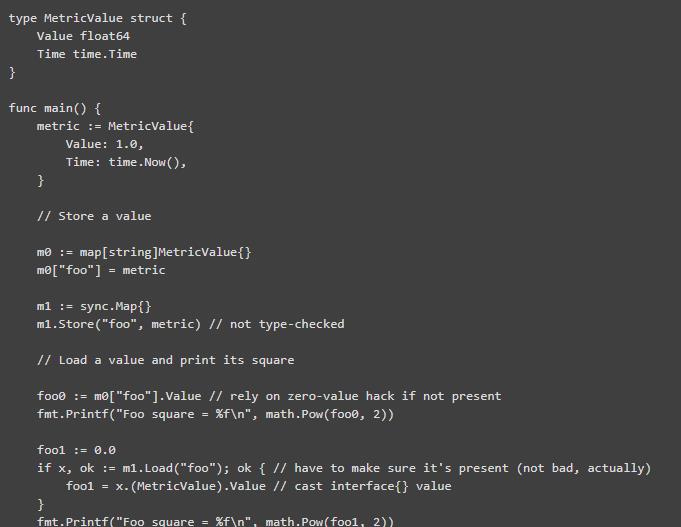
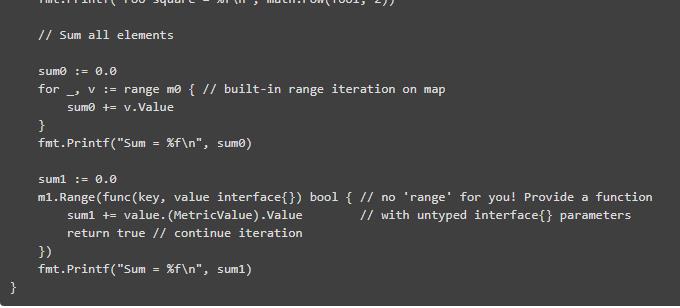
这是个很好的例子来解释为什么 Go 的生态系统中没有太多的数据结构:与内置的 slice 和 map 相比它们用起来很痛苦。出于一个简单的原因:Go 的数据结构中只有两大类。
aristocracy,内置的 slice,map,array 和 channel:类型安全,通用且调用 range 方便,
Go 代码写的其他的类型:不提供类型安全,因为需要强制转换所以用起来笨拙。
所以库定义的数据结构必须为我们开发者提供很多实在的好处,让我们愿意付出失去类型安全和额外冗长代码的代价。
当我们想要编写可重用的算法时,内置结构和 Go 代码之间的双重性更加微妙。 这是标准库的排序包对排序片段的一个例子:
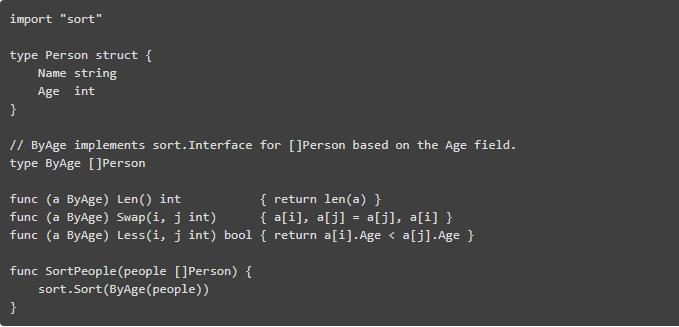
等等...这是真的吗? 我们必须定义一个新的 ByAge 类型,它必须实现 3 种方法来桥接泛型(“可重用”)排序算法和类型化片段。
对于我们开发者来说,唯一需要关注的一件事,就是用于比较两个对象的Less函数,并且它是域依赖的。其他一切都是干扰,因为 Go 没有泛型所以出现了模板。我们不得不一次次地重复使用它,包括我们想去排序的每个 type 和 comparator。
更新:Michael Stapelberg 指导我去看被我遗漏的 sort.Slice。它在底层使用了反射,而且要求排序的时候,在 slice上comparator 函数得形成一个闭包。虽然这看起来会好些,但它依旧丑陋。
对于 Go 不需要泛型的所有解释都是在告诉我们这就是“Go 方式”,Go 允许有可复用的算法来避免向下转型成 interface{}...
好了,现在来缓解一下痛苦,如果 Go 能用宏来生成这些无意义的模板将会变得美好一些,对吗?
go generate:还行,但是...
Go 1.4 引入了 go generate command 命令来触发源代码中注释的代码生成。 那么,这里的“注释”实际上意味着一个神奇的 //go:generate,用严格的规则生成注释:“注释必须从行的开始处开始并且在 // 和 go:generate 之间没有空格”。 弄错了,增加一个空格,没有空格工具会警告你。
这实际上涵盖了两种用例:
从其他来源生成 Go 代码:ProtoBuf / Thrift / Swagger 模式,语言文法等
生成补充现有代码的 Go 代码,例如作为示例给出的 stringer,它为一系列类型常量生成一个String() 方法。
第一个用例是可以正常使用的,附加的是你不必使用 Makefiles,生成指令可以接近生成的代码的用法。
对于第二种用例,许多语言(如 Scala 和 Rust)都有宏(在设计文档中提到)可在编译期间访问源代码的 AST。 Stringer 实际上导入了 Go 编译器的解析器来遍历 AST。 Java 没有宏,但注释处理器扮演着相同的角色。
许多语言也不支持宏,因此除了这种脆弱的注释驱动语法之外,没有任何根本性的错误,除了这种脆弱的注释驱动的语法之外,它看起来像是一种快速破解,它不知道怎么做了这个工作,而不是被认真考虑为连贯的语言设计。
哦,你知道Go编译器实际上有许多注释/杂注和条件编译使用这种脆弱的注释语法?
结论
正如你可能猜到的那样,我对 Go 又爱又恨。 Go 有点像一个朋友,你喜欢和他在一起,因为他很有趣,很适合一起喝啤酒闲谈,但是当你想要进行更深入的对话时,你会觉得无聊或痛苦,而且你不想与他去一起度假。
我喜欢 Go 编写高效的 API 及网络工具的简单性,这归功于 Goroutine,我讨厌它在我必须实现业务逻辑时限制我的表现力,并且我讨厌它的所有怪异和陷阱等着你踩进去。
直到最近,Go 还没有真正的替代品,它正在开发高效的本地可执行文件,而不会产生 C 或 C ++ 的痛苦。Rust 正在迅速发展,我越玩越多,我发现它越来越有趣和设计得非常好。我有一种感觉,Rust 是需要一段时间才能相处的朋友之一,但是你最终会想要与他们建立长期合作关系。
回到更技术的层面,你会发现文章中说的 Rust 和 Go 并不是一个层面的,由于 Rust 没有 GC 等原因,Rust 是一个系统语言。我认为这越来越不符合实际。Rust 在大型 web 框架和优秀的 ORM 中的地位正在逐渐升高。它也给你一种亲切感:“如果它是编译器,错误会出现在我写的逻辑上,而不是我忘记注意的语言特性上”。
我们也从容器/服务网格领域上看到一些有趣的活动,包括使用 Rust 写的高效 Sozu 代理,或者 Buoyant(Likerd 的开发者)开发的他们的新 Kubernetes 服务网格 Conduit 来作为 Go 和 Rust 的结合,其中 Go 作为控制层(我猜由于现有的 Kubernetes 库),Rust 作为数据层因为它的高效和健壮。
Swift 也是可以替代 C 和 C++ 语言的家族的一部分。尽管它的生态仍然太以 Apple为 中心,但是现在它在 Linux 是可以用的,而且出现了服务端 API 和 Netty 框架。
现在当然没有万能和完全通用的技术。但是了解你使用的这些工具的优点和缺点是很重要的。我希望这个博客已经让你了解到了一些关于 Go 的你曾经没意识到的问题,这样你就可以避免陷阱而不会被陷进去!

,
以上是关于驳狗屎文 "我为啥放弃Go语言的主要内容,如果未能解决你的问题,请参考以下文章