性能优化
Posted 漠小浅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能优化相关的知识,希望对你有一定的参考价值。
spark core部分
一:Spark性能优化核心基石
1,Spark是采用Master-slaves的模式进行资源管理和任务执行的管理:
a) 资源管理:Master-Workers,在一台机器上可以有多个Workers;
b) 任务执行:Driver-Executors,当在一台机器上分配多个Workers的时候,那么默认情况下每个Worker都会为当前运行的应用程序分配一个Executor,但是我们可以修改配置 来让每个Worker为我们当前的应用程序分配 若干个Executor。程序运行的时候会被划分成为若干个Stages(Stage内部没有Shuffle,遇到Shuffle的时候会划分Stage),每个Stage里面包含若干个处理逻辑完全一样只是处理的数据不一样的Tasks,这些Tasks会被分配到Executor上去执行。
2,在Spark中可以考虑在Worker节点上使用固态硬盘以及把Worker的shuffle结果保存到RAM DISK的方式来极大的提高性能。
3,默认情况下Spark的Executor会尽可能占用当前机器上尽量多的Core,这样带来的一个好处就是可以最大化的提高计算的并行度,减少一个Job中运行的批次,但带来的一个风险就是如果每个Task占用内存比较大,就需要频繁的splill over(写操作磁盘)或者有更多的OOM的风险。
4,当你经常发现机器频繁的OOM的时候,可以考虑的一种方式就是减少并行度,这样同样的内存空间并行运算的任务少了那么对内存的占用就更少了,也就减少了OOM的可能性;
5,处理Spark Job的过程中如果出现特别多的小文件,这时候就可以通过coalesce来减少Partition的数量,进而减少并行运算的Task的数量来减少过多任务的开辟,从而提升硬件的使用效率。(coalesce:shuffle->false;repartition:shuffle->true)
6,慢任务:处理Spark Job时候如果发现某些Task运行的特别慢,这个时候应该考虑增加任务的并行度,减少每个Partition的数据量来提高执行效率。
7,满任务:处理Spark Job时候如果发现某些Task运行的特别慢另外一个处理办法是增加并行的Executor的个数,这样每个Executor分配的计算资源就变少了,可以提升硬件的整体使用效率。
8,处理Spark Job的时候如果发现比较容易内存溢出,一个比较有效的办法就是增加Task的并行度,这样每个Task处理的Partition的数据量就变少了,减少了OOM的可能性。另外一个比较有效的办法是减少并行的Executor数量,这样每个Executor就可以分配到更多的内存,进而增加每个Task使用的内存数量,降低OOM的风险。
9,提升Spark硬件尤其是CPU使用率的一个方式就是增加Executor的并行度,但是如果Executor过多的话,直接分配在每个Executor的内存就大大减少,在内存中的操作就减少,某些磁盘的操作就越来越多,导致性能越来越差。
10,适当设置Partition分片数是非常重要的,过少的Partition分片数可能会因为每个Partition数据量太大而导致OOM以及频繁的GC,而过多的Partition分片数据可能会因为每个Partition数据量太小而导致执行效率低下。
11,如果Spark的CPU的使用率不够高,可以考虑为当前的程序分配更多的Executor,或者增加更多的Worker实例来充分的使用多核的潜能。
12,性能调优的有效性是暂时的!!!例如为当前的应用程序增加Executor可能在一开始可以提高性能 (例如CPU使用率提高等),但是随着Executor越来越多,性能可能会下降!!!因为Executor越来越多的时候,为每个Executor分配的内存就越来越少,Task执行过程中可用的内存就越来越少,这个时候就要频繁的Spill over到磁盘,此时自然而然的导致性能变差。
13,实际执行Spark Job的时候要根据输入数据和每个Executor分配的Memeory来决定执行时候的并行度,实际上一个简单事实是每个Core可以考虑分配2-3个Task。
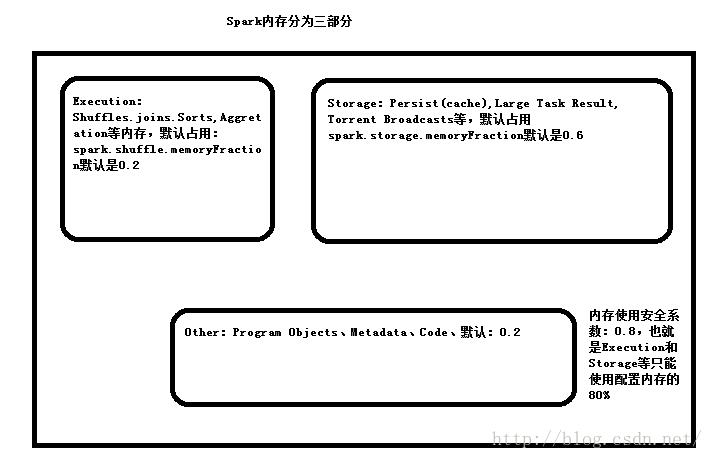
14,默认情况下Executor的60%的内存被用来作为RDD的缓存,40%内存被用来作为对象的创建空间。设置是通过spark.storage.memoryFraction。
15,GC一般不能超过CPU的2%的时间。
16,Broadcast,如果Task在运行的过程中使用炒股20KB大小的静态大对象,这个时候一般都要考虑使用Broadcast,例如一个大表Join一个小表,此时如果使用Broadcast把小表广播出去,这个时候大表就只需要静静地做一个美男子在自己的节点上呆着来等待小表的到来。
小节一下:一台机器上可以有很多Worker,每个Worker上可以有许多Executor,Task是程序要运行的时候根据Shuffle划分的Stage内部的Task,一个Stage内部的Task他们的处理逻辑完全一样,只是处理的数据不一样而已。具体的Task是运行在Executor中,而Executor在默认情况下会占用尽量可能多的cores,例如你有时候发现一个Executor占用了绝大多数的cores,但是他的cpu使用率并不高,这个时候我们可以考虑设置减少Executor占用的cores,或者说增加更多的Worker,或者说增加一个Worker下更多的Executor来增加并行度从而提高cpu的利用率。另外一方面,Executor在处理数据的时候需要严格考虑内存的使用情况,不然容易出现OOM,一个Task对应一个Partition,如果说这个Partition比较小,则导致执行效率低下,因为大多数情况下都用在Task的切换下了,如果Partition太大,则导致内存压力过大,这个样子一方面会出现OOM,另一方面因为Partition太大,所以Partition的数量减少,这个样子并行度就会降低,一个极端的例子就是说总共的并行度还没有总共的cores多,这个样子不能很好的发挥硬件的潜力。 默认情况下:程序中有多少并行度,它是根据父RDD的最大的并行度决定的,即并行度具有继承性,也可以通过参数进行控制,例如我们运行Job的非常慢,CPU利用率不高,这个时候可以考虑减少没有Executor占用的core的个数,增加Executor或者增加程序的分片数来提高程序的并行度。OOM最简单的方法就是增加分片的数量。由于在一台机器上为一个应用程序开辟过多的Executor的话,这个时候可能会有OOM的风险,这个时候可以考虑减少Executor的个数,这个,内存就分配给了更少的Executor,,即相同的内存资源分配给了更少的Executor,这样就相当于增加了每个Task运行的内存分配,当然运行速度会减少,因为并行度不是那么多了。还有就是大量的小文件的情况,这个时候就必须减少文件的分片数,小文件的产生一般是在处理的过程中产生的,可以使用coalesce。
二,Task性能优化
1,慢任务的性能优化:可以考虑减少每个Partition处理的数据量,同时建议开启spark.speculation(任务推测执行模式:任务还没有完成的情况下,开启相同的任务来执行来观察谁先完成就要谁的结果),因为当我们减少每个Partition处理数据的数量的话,有一个问题,就是有可能只有几个任务比较慢,但是如果直接减少每个Partition处理的数据量的话,这个样子每个Partition的数据量都减少了。慢任务的产生:硬件的故障,数据倾斜等。
2,尽量减少Shuffle,例如我们要尽量减少groupByKey的操作,因为groupByKey会要求通过网络拷贝(Shuffle)所有的数据,优先考虑使用reduceByKey,因为reduceByKey会首先reduce locally;在例如在进行join操作的时候,形如(k1,v1)join(k1,v2)=》(k1,v3)此时就可以进行pipeline,但是(o1)join (o2) =>(o3),此时就会产生Shuffle操作;
3,Repartition:增加Task数量的时候可以考虑使用,从而更加充分的使用计算资源;Coalesce:整理Partition碎片;
三,数据倾斜
1,定义更加合理的Key(或者说自定义Partitioner);
2,可以考虑使用ByteBuffer来存储Block,最大的存储数据为2G,如果超过这个大小会报异常;
四,网络
1,可以考虑Shuffle的数据放在Tachyon中带来更好的数据本地性,减少网络的Shuffle;
2,优先采用Netty的方式进行网络通讯;
3,广播:例如进行join操作的时候采用Broadcast可以达到完全的数据本地性的情况下进行join操作;
4,mapPartitions中的函数会直接作用于整个Partition(一次!!!);
5,最优先考虑使用PROCESS_LOCAL(Spark默认情况下也是这样做的),所以你更应该考虑使用Tachyon;
5,如果要访问HBase或者Canssandra,务必保证数据处理发生在数据所在的机器上,
五,Spark程序数据结构的优化
1,Java的对象:对象头是16个字节(例如指向对象的指针等原数据信息),如果对象中只有一个int的property,则此时会占用20个字节,也就是说对象的元数据占用了大部分的空间,所以在封装数据的时候尽量不要使用对象!例如说使用JSON格式来封装数据。
2,Java的String在实际占用内存方面要额外使用40个字节(String的内部使用char[]来保存他的字符序列),另外需要注意的是String中每个字符是2个字节(UTF-16),如果内部有5个字符的话,实际上会占用50个字节。
3,Java中的集合List、HashMap等等其内部一般使用链表来实现,具体的每个数据使用Entry等,这些也非常消耗内存;
4,Java中基本的数据类型会自动的封箱操作,例如int会自动变成Integer,这回额外增加对象头的空间占用。
5,优先使用原生数组,尽可能不要直接去使用ArrayList、HashMap、LinkedList等数据结构,例如说List<Integer> list = new ArrayList<integer> 需要考虑替换为int[] array = new int[];
6,优先使用String(推荐使用JSON) 而不是采用HashMap、List等来封装数据,例如Map<Integer,Worker> workers = new HashMap<Integer,Worker>(),,建议使用JSON字符串或者自己构建的String字符串对象,例如“id:name,salary||id:name,salary||id:name,salary”;
六,Spark内存消耗诊断
1,JVM自带众多内存消耗诊断的工具,例如JMap、JConsole等、第三方 IBM JVM Profile tools等。
2,在开发、测试、生产环境下用的最多的是日志,Dirver产生的日志!最简单也是最有效的方式就是调用RDD.cache,当进行cache操作的时候,Driver上的BlockManagerMaster会记录该信息并写进日志中!
七,persist和checkpoint
1,当反复使用某个(些)RDD的时候强烈建议使用persist来对数据进行缓存(MEMORY_AND_DISK)。
2,若果某个步骤的RDD计算特别耗时或者经历了很多步骤的计算,如果数据丢失则重新计算的代价特别大,此时考虑使用checkpoint,因为checkpoint是把数据写入HDFS,天然具有高可用性。
八,Spark性能调优之序列化
1,之所以进行序列化,最重要的原因是内存空间有限(减少GC的压力,最大化的避免Full GC的产生,因为一旦产生Full GC则整个Task处于停止状态),减少磁盘IO的压力、减少网络IO的压力。
2,什么时候会必要的产生序列化和反序列化呢?发送磁盘IO和网络通信的时候会序列化和反序列化,更为重要的考虑序列化和反序列化的时候有另外两种情况:
a)Persist(Checkpoint)的时候必须考虑序列化和反序列化,例如说cache到内存的时候只能使用JVM分配的60%的内存空间,此时好的序列化机制就至关重要了。
b)编程的时候!使用算子的函数操作如果传入了外部数据就必须进行序列化和反序列化。
conf.set(“spark.serializer”,“org.apache.spark.serializer.KryoSerializer”)
conf.registryKryoClass(Array(classOF[Person]))
val person = new Person();//在Driver中
rdd.map(item => person.add(item))//在Executors中
3,强烈建议使用kyro序列化器进行序列化和反序列化,Spark默认情况下不是使用的kryo,而是Java自带的序列化器ObjectInputStream和ObjectOutPutStream(主要是考虑了方便性和通用性),在默认情况下如果自定义了RDD中数据元素娥类型则必须实现Serializable接口,当然您也可以实现自己的序列化接口Externalizable来实现更加高效的Java序列化算法;采用默认的ObjectInputStream和ObjectOutputStream会导致序列化后的数据占用大量的内存或者磁盘或者大量的消耗网络,并且在序列化和反序列化的时候比较消耗CPU(Java的序列化接口是Serializable,java内部实现并采用了ObjectInputStream和ObjectOutPutStream)
4,强烈推荐大家采用Kryo序列化机制,Spark使用Kryo序列化机制会比Java默认的序列化机制更加节省空间(节省近10倍的空间)以及更少的消耗CPU,个人强烈建议大家在一切情况下尽可能的使用Kryo序列化机制!
5,使用Kryo的两种方式:
a)在spark-default.conf中配置:
b)在程序的SparkConf中配置,conf.set(“spark.serializer”,“org.apache.spark.serializer.KryoSerializer”)使用kryo可以更加快速、更低存储空间占用量以及更高性能的方式来进行序列化。
6,Spark中scala常用的类型自动的通过AllScalaRegisty注册给了Kryo进行序列化管理。
7,如果是自定义的类型必须注册给序列化器,例如:
conf.set(“spark.serializer”,“org.apache.spark.serializer.KryoSerializer”)
conf.registryKryoClass(Array(classOF[Person]))
val person = new Person();//在Driver中
rdd.map(item => person.add(item))//在Executors中
8,Kryo在序列化的时候魂村空间默认大小是2MB,可以根据具体的业务模型调整该大小,具体方式spark.kryoserializer.buffer为10MB等
9,在使用Kryo强烈建议注册时写完整的包名和类名,否则的话每次序列化的时候都会保存一份整个包名和类名的完整信息,这就会不必要的消耗内存空间。
九,Spark JVM性能调优
1,好消息是Spark的钨丝计划是用来专门解决JVM性能问题的,不好的消息是至少在spark2.0以前钨丝计划功能不稳定且不完整其职能在特定的情况下发生作用,也就是说包括spark1.6.0在内的spark以及以前的版本我们大多数情况下没有使用钨丝计划的功能,所以此时就必须关注JVM性能调优。
2,JVM性能调优的关键是调优GC!为什么GC如此重要!主要是因为Spark热衷于RDD的持久化!GC本身的性能开销是和数据量成正比的。
3,初步可以考虑的是尽量多的array和String,并且在序列化机制方面尽可能的采用Kryo,让每个partiton都成为字节数组;
4,监控GC的基本方式有两种:
a)配置
spark.executor.extraJavaOptions
-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateTimeStamps
b)SparkUI
5,Spark在默认情况下使用60%的空间来进行Cache缓存RDD的内容,也就是说Task在执行的时候只能使用剩下的40%,如果空间不够用就会触发(频繁的)GC
可以设置spark.memory.fraction参数来进行调整空间的使用,例如降低Cache的空间,让Task使用更多的空间来创建对象和完成计算。
再一次,强烈建议进行RDD的Cache的时候使用Kryo序列化机制,从而给Task可以分配更大的空间来顺利完成计算(避免频繁的GC)。
6,因为在老年代空间满的时候会发生Full GC操作,而老年代空间中基本都是活的比较久的对象(经历数次GC依旧存在),此时会停下所有程序线程,进行Full GC,对Old区中的对象进行整理,严重影响性能,此时可以考虑:
a)可以设置spark.memory.fraciton参数来进行调整空间的使用来给年轻代更多的空间用户存放短时间的存放对象
b)-Xmn调整Eden区域;
c)对RDD中操作的对象和数据进行大小评估,如果在HDFS上解压后一般体积可能变成原有体积的3倍左右。根据数据的大小来设置Eden,如果有10个Task,每个Task处理的HDFS上的数据是128M,则需要设置-Xmn为10*128*3*4/3的大小;
d)-XX:SupervisorRatio
e)-XX:NewRatio
十,数据本地性
1,数据本地性对分布式系统的性能而言是一件最为重要的事情(之一),程序运行本身包含代码和数据两部分,单机版本一般情况下很少考虑数据本地性的问题(因为数据在本地),但是对于单机版本的程序由于数据本地性有PROCESS_LOCAL和NODE_LOCAL之分,所以我们还是尽量的让数据处于PROCESS_LOCAL;Spark作为分部署系统更加注意数据本地性,在Spark中数据本地性分为PROCESS_LOCAL、NODE_LOCAL、NO_PREF、RACK_LOCAL(机架)、ANY(数据可能子啊任何地方,包括在其他网络环境中,例如说百度云中,数据和计算集群不在同样的集群中,此时就是ANY的一种表现)
2,对于ANY的情况,默认状态下性能会非常低下,此时;强烈建议使用Tachyon;例如在百度云上,为了确保计算速度,就在计算集群和存储集群之间加入了Tachyon,通过Tachyon来从远程抓取数据,而Spark基于Tachyon来进行计算,这就更好的满足了数据本地性。
3,如果数据是PROCESS_LOCAL,但是此时并没有空闲的Core来运行我们的Task,此时Task就要等待,例如等待3000ms,3000ms内如果能够运行待运行的Task则直接运行,如果超过了3000ms,此时数据本地性就要退而求其次采用NODE_Local,同样的道理NODE_LOCAL也会有等待的超时时间,依次类推........如何配置Locality呢?可以统一采用spark.locality.wait来设置(例如设置5000ms),当然你可以分别spark.locality.wait.process,spark.locality.wait.node,spark.locality.wait.rack等,一般的具体设置是本地Locality优先级越高,则可以设置越高的等待超时时间。
十一,RDD的自定义(以Spark on HBase为例)
1,第一步是定义RDD.getPartitions的实现
a) createRelation具体确定HBase的链接方式和具体访问的表;
b) 然后通过HBase的API来获取Region的List
c) 可以过滤出有效的数据
d) 最后返回Region的Array[Partition],也就是说一个Partition处理一个Region的数据,为更佳的数据本地性打下基础
2,第二步是RDD.getPreferredLocations
a) 根据Split包含的Region信息来确定Region具体在什么节点上,这样Task在调度的时候就可以游侠被调度到Region所在的机器上,最大化的提高数据本地性。
3,第三步是RDD.compute
a) 根据Split中的Region等信息调用HBase的API来进行操作(主要是查询)
十二,Shuffle性能调优
1,为题:Shuffle output file lost?真正的原因是GC导致的!如果GC尤其是Full GC产生通常会导致线程停止工作,这个时候下一个Stage的Task在默认情况下就会尝试重试来获取数据,一般重试3次每次重试的时间为5s,也就是说默认情况下15s内如果还是无法抓取到数据的话,就会出现Shuffle output file lost等情况,进而导致Task重试,甚至会导致Stage重试,最严重的是会导致App失败;在这个时候首先就要采用高效的内存数据结构和序列化机制、JVM的调优来减少Full GC的产生;
2,在Shuffle的时候,Reducer端获取数据会有一个指定大小的缓存空间,如果内存足够大的情况下,可以适当的增大该缓存空间,否则会spll到磁盘,影响效率,此时可以调整(增大)spark.reducer.maxSizeInFlightt参数
3,,在ShuffleMapTask端通常也会增大Map任务的写磁盘的缓存,默认情况下时32k spark.shuffle.file.buffer 32k
4,调整获取Shuffle数据的重试次数,默认是3次,通常建议增大重试次数;调整获取Shuffle数据重试的时间间隔,默认5s,强烈建议提高该时间,spark.shuffle.io.retryWait
5,在reducer端做Aggregation的时候,默认是20%的内存用来做Aggregation,如果超出了这个大小就会溢出到磁盘上,建议调大百分比来提高性能。
十三,“钨丝计划”产生的本质原因
1,Spark作为一个一体化多元化的大数据处理通用平台,性能一直是其根本性的追求之一,Spark基于内存迭代的模型极大的满足了人们对分布式系统处理性能的渴望,但是有Spark是采用Scala+Java语言编写的所以运行在了JVM平台,当然JVM是一个绝对伟大的平台,因为JVM让整个离散的主机融为了一体(网络即OS),但是JVM的死穴GC反过来限制了Spark(也就是说平台限制了Spark),所以Tungsten聚焦于CPU和Memory使用,以达到对分布式硬件潜能的终极压榨
2,对Memory的使用,Tungsten使用了Off-Heap,也就是在JVM之外的内存空间(这就好像C语言对内存的分配、使用和销毁),此时Spark实现了自己的独立的内存管理,就避免了JVM的GC引发的性能问题。其实还包含避免了序列化和反序列化
3,对于Memory管理方面一个至关重要的内容Cache,Tunsten提出了Cache-awarecomputation,也就是说使用对缓存友好的算法和数据结构来完成数据的存储和复用;
4,对于CPU而言,Tunsten提吃了Code Generation,其首先在Spark SQL使用,通过Tunsten要把该功能普吉岛Spark的所有功能中;
总结:Tungsten的内存管理机制独立于JVM,所以Spark操作数据的时候具体操作的是Binary Data,而不是JVM Object,而且还免去了序列化和反序列化的过程
十四,“钨丝计划”内幕详解
内存管理方面:Spark使用了sun.misc.Unsafe来进行Off-heap级别的内存分配、指针使用及内存释放。Spark为了统一管理Off-Heap和On-Heap而提出了Page
十五,使用Tungsten功能
如果想让你的程序使用Tunsten的功能,可以配置spark.shuffle.manager=tunsten-sort
十六,Tungsten-sort base shuffle writer内幕
1,写数据在内存足够大的情况下是写到Page里面,在Page中有一条条的Record,如果内存不够的话 会Spill到磁盘上;
2,如何看内存是否足够呢?两方面:
a)系统默认情况系爱给ShuffleMapTask最大准备了多少内存空间,默认情况下是ExecutorHeapMemory*0.8*0.2
spark.shuffle.memoryFraction = 0.2
spark.shuffle.safeyFraction = 0.8
b)另外一方面是和Task处理的Partition大小紧密相关;
十七,Tungsten中到底什么事Page?
1,在Spark其实是不存在Page这个类的!实质上来说,Page是一种数据结构(类似于Stack、List等),从OS的层面来讲,Page代表了一个内存块,在Page里面可以存放数据,在OS中会存在很多不同的Page,当要获取数据的时候首先要定位具体是哪个Page中的数据,找到该Page之后从Page中根据特定的规则(例如说数据的Offset和length等)取出数据。
以上是关于性能优化的主要内容,如果未能解决你的问题,请参考以下文章