数据结构 平均查找长度
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构 平均查找长度相关的知识,希望对你有一定的参考价值。
设散列表的长度为8,散列函数H(k)=k mod 7,初始记录关键字序列为(25,31,8,27,13,68),要求分别计算出用线性探测法和链地址法作为解决冲突方法的平均查找长度
给出具体过程不要答案
对于含有n个数据元素的查找表,查找成功的平均查找长度为:ASL=∑PiCi (i=1,2,3,…,n)。其中:Pi 为查找表中第i个数据元素的概率,Ci为找到第i个数据元素时已经比较过的次数。
已知一个待散列存储的线性表为(38,25,74,63,52,48),散列函数为H(k)=k mod 7,若采用线性探测的开放地址法处理冲突,则平均查找长度为:
解答:ASL=p1c1+p2c2+p3c3+.......
也可以表示为
ASL=1/n(c1+c2+c3+....)
其中c是每个数查询的次数
按照H(K)=k mod 7得:
38----1
25----1
74----2
63----1
52----4
48----3
所以ASL=1/6(1+1+2+1+4+3)=2追问
可以答案是这样的
ASL1=7/6,ASL2=4/3
题目说了散列表 那应该是哈希吧
查找
1 查找
在数据集合中寻找满足某种条件的数据元素的过程称为查找
查找长度——在查找运算中,需要对比关键字的次数称为查找长度
平均查找长度(ASL, Average Search Length)——所有查找过程中进行关键字的比较次数的平均值
2 顺序查找法
例 顺序查找法适合于存储结构为(顺序存储或链式存储)的线性表
3 折半查找法

例 对线性表进行折半查找时,要求线性表必须(以顺序方式存储,且结点按关键宇有序排列)
4 散列(Hash)技术(在各种查找方法中,平均查找长度与结点个数 n 无关的查找方法是散列查找法)
4.1 散列函数
除留余数法
H(key) = key % p
散列表表长为m,取一个不大于m但最接近或等于m的质数p(质数又称素数。指除了1和此整数自身外,不能被其他自然数整除的数)
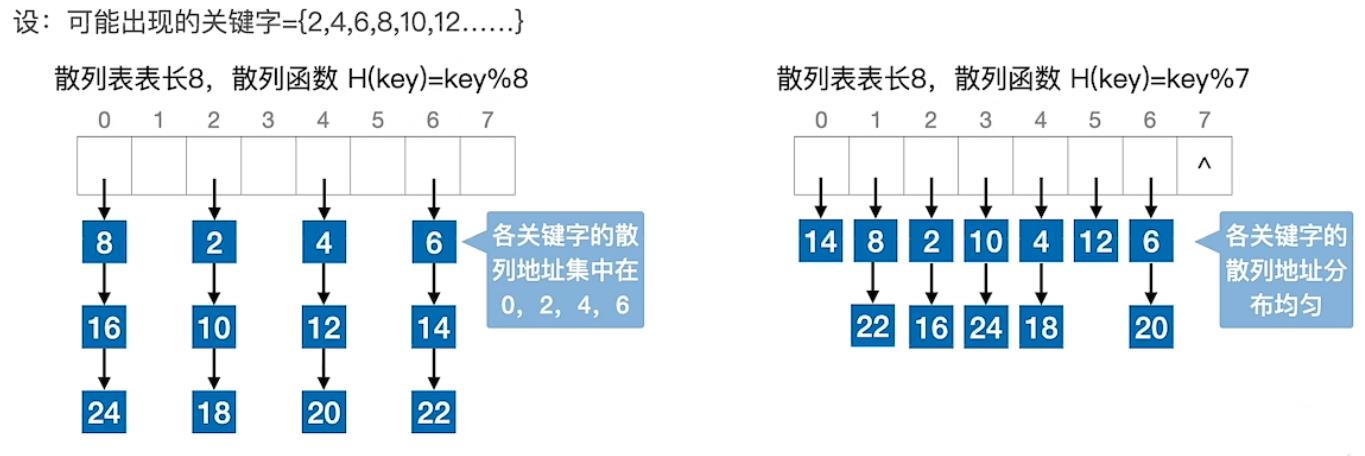
用质数取模.分布更均匀,冲突更少
直接定址法
H(key) = key 或 H(key) = a*key + b
其中,a和b是常数。这种方法计算最简单,且不会产生冲突。它适合关键字的分布基本连续的情况,若关键字分布不连续,空位较多,则会造成存储空间的浪费。
4.2 散列表
散列法存储的思想是由关键字值决定数据的存储地址
4.3 散列冲突的发生及其解决方法(散列表的查找效率主要取决于散列表构造时选取的散列函数和处理冲突的方法)
拉链法(又称链接法、链地址法)把所有“同义词”存储在一个链表中
开放定址法(是指可存放新表项的空闲地址既向它的同义词表项开放,又向它的非同义词表项开放)
数学递推公式为
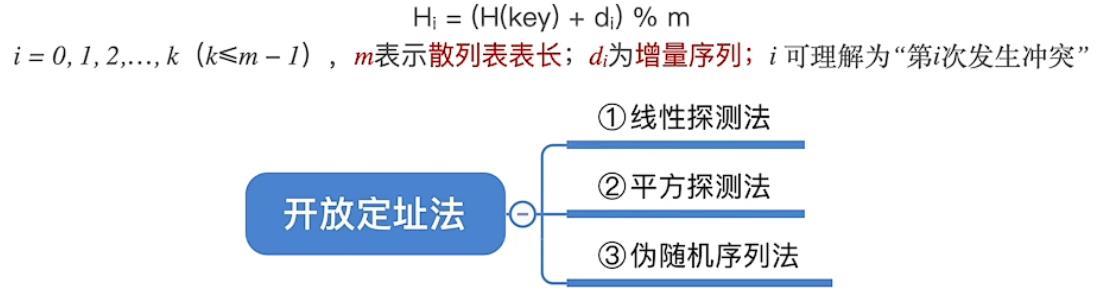
再散列法
4.4 负载因子(负载因子是散列表的一个重要参数,它反映了散列表的饱满程度)
装填因子a=表中记录数/散列表长度
以上是关于数据结构 平均查找长度的主要内容,如果未能解决你的问题,请参考以下文章