JAVA目录树
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JAVA目录树相关的知识,希望对你有一定的参考价值。
JAVA中File类的listFiles()方法:返回一个抽象路径名数组,这些路径名表示此抽象路径名表示的目录中的文件。
用这个方法,取得的数组文件会在文件夹前面,
j1
├ j1.txt
├ ppt
└ source
这象这样,j1.txt应该在后面的。如下:
j1
├ source
├ ppt
└ j1.txt
有没有什么办法使返回的抽象路径名数组中,文件在文件夹的后面就象图里的一样,

做两个文件过滤器。
import java.io.FileFilter;
class FolderFilter extends FileFilter
public boolean accept(File f)
return f.isDirectory();
class FilesFilter extends FileFilter
public boolean accept(File f)
return f.isFile();
在调用listFiles()取子项目时,先new一个FolderFilter做参数调用listFiles,得到的子项目就是目录。
new一个FilesFilter做参数调用listFiles得到的就是子文件。 参考技术B 你继承一下,再重写listFiles()方法。本回答被提问者采纳
字典树(java)
什么是字典树
- 字典树(又叫单词查找树、TrieTree),是一种树形结构,典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串,如01字典树)。主要思想是利用字符串的公共前缀来节约存储空间。很好地利用了串的公共前缀,节约了存储空间。字典树主要包含两种操作,插入和查找。
其实很好理解,小时候我们都用过英语字典,前面有个目录,目录里的内容就是字典树
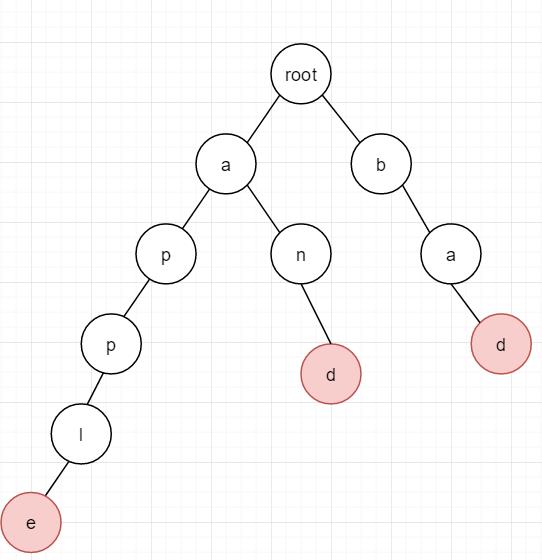
字典树的基本性质如下:
- 根节点没有字符路径。除根节点外,每一个节点都被一个字符路径找到;
- 从根节点出发到任何一个节点,如果将沿途经过的字符连接起来,一定为某个加入过的字符串的前缀;
- 每个节点向下的所有字符串路径上的字符都不同;
字典树的应用
根据字典树的性质,有以下几个应用场景:
-
串的快速检索:给出N个单词组成的熟词表,以及一篇全用小写英文书写的文章,要求按最早出现的顺序写出所有不在熟词表中的生词。
-
串”排序:给定N个互不相同的仅由一个单词构成的英文名,将他们按字典序从小到大输出。用字典树进行排序,采用数组的方式创建字典树,这棵树的每个结点的所有儿子很显然地按照其字母大小排序。对这棵树进行先序遍历即可。
-
最长公共前缀:对所有串建立字典树,对于两个串的最长公共前缀的长度即他们所在的结点的公共祖先个数,于是,问题就转化为当时公共祖先问题。
字典树的实现
字典树的功能主要包括两个操作,插入和查找
插入(insert)
我们英文中总共有26个字母,所以在字典树中的每个节点,最多只有26个子节点
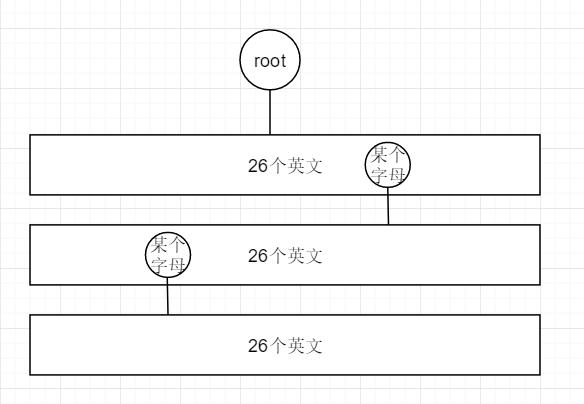
我们在插入的时候,只需要判断,对应的26个字母索引中存不存在当前字母,若存在,查看该节点的的26个子节点(26个字母),不存在,加入
遍历完成后将最后一个字母设置为终止节点,代表一个单次的结束
java代码:
public void insert(String word) {
Trie node = this;
for (int i = 0; i < word.length(); i++) {
char ch = word.charAt(i);
int index = ch - 'a';
if (node.children[index] == null) {
//我们只需要在让索引对应位置不为空就行,不一定要赋值
node.children[index] = new Trie();
}
node = node.children[index];
}
node.isEnd = true;
}
查询
查询其实和插入没什么区别,遍历的同时查看对应索引存不存在对应字母,存在则继续深入,直到将这个单词遍历完成,并且最后一个节点为终止节点,否则也不存在;若索引中都不存在对应字母直接退出
private Trie searchPrefix(String prefix) {
Trie node = this;
for (int i = 0; i < prefix.length(); i++) {
char ch = prefix.charAt(i);
int index = ch - 'a';
if (node.children[index] == null) {
return null;
}
node = node.children[index];
}
return node;
}
完整代码:
class Trie {
private Trie[] children;
private boolean isEnd;
public Trie() {
children = new Trie[26];
isEnd = false;
}
//插入
public void insert(String word) {
Trie node = this;
for (int i = 0; i < word.length(); i++) {
char ch = word.charAt(i);
int index = ch - 'a';
if (node.children[index] == null) {
node.children[index] = new Trie();
}
node = node.children[index];
}
node.isEnd = true;
}
//查询某个单词
public boolean search(String word) {
Trie node = searchPrefix(word);
return node != null && node.isEnd;
}
//查询前缀是否存在
public boolean startsWith(String prefix) {
return searchPrefix(prefix) != null;
}
//查询前缀,并返回前缀
private Trie searchPrefix(String prefix) {
Trie node = this;
for (int i = 0; i < prefix.length(); i++) {
char ch = prefix.charAt(i);
int index = ch - 'a';
if (node.children[index] == null) {
return null;
}
node = node.children[index];
}
return node;
}
}
若有误,请指教!!!
以上是关于JAVA目录树的主要内容,如果未能解决你的问题,请参考以下文章